Flink介绍
1、Flink简介
- Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。
- Apache Flink 是 Apache 的顶级项目。
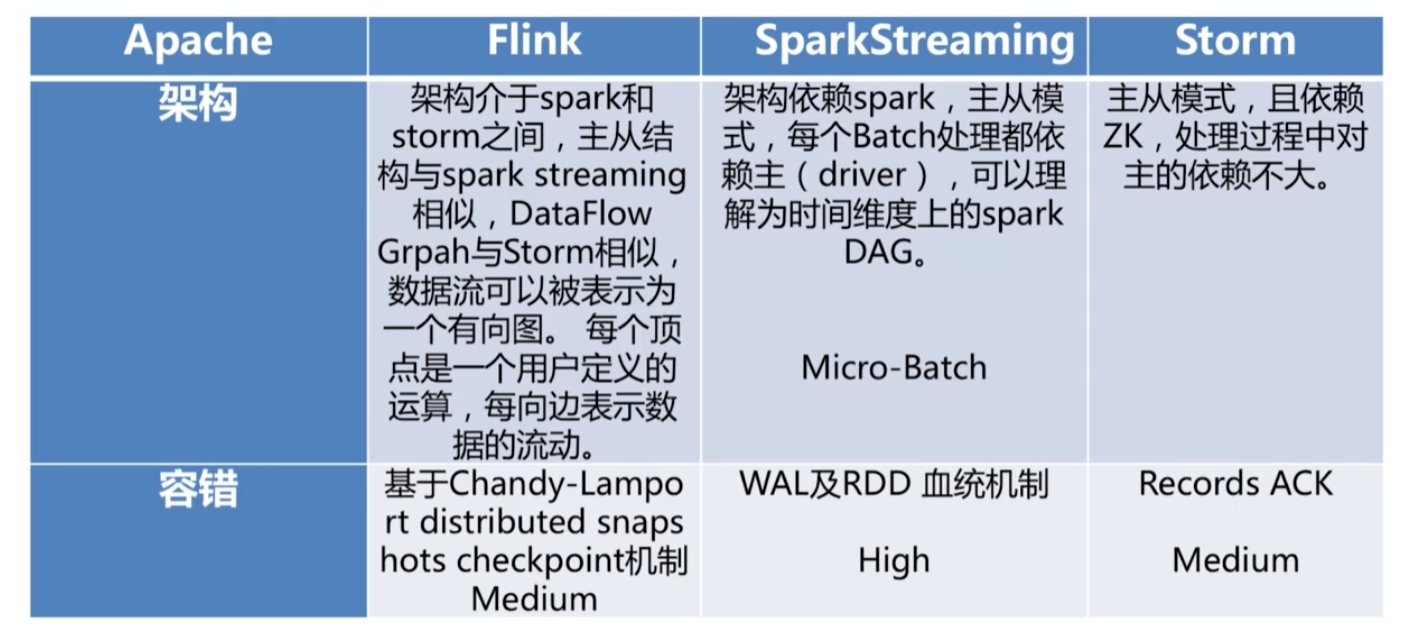
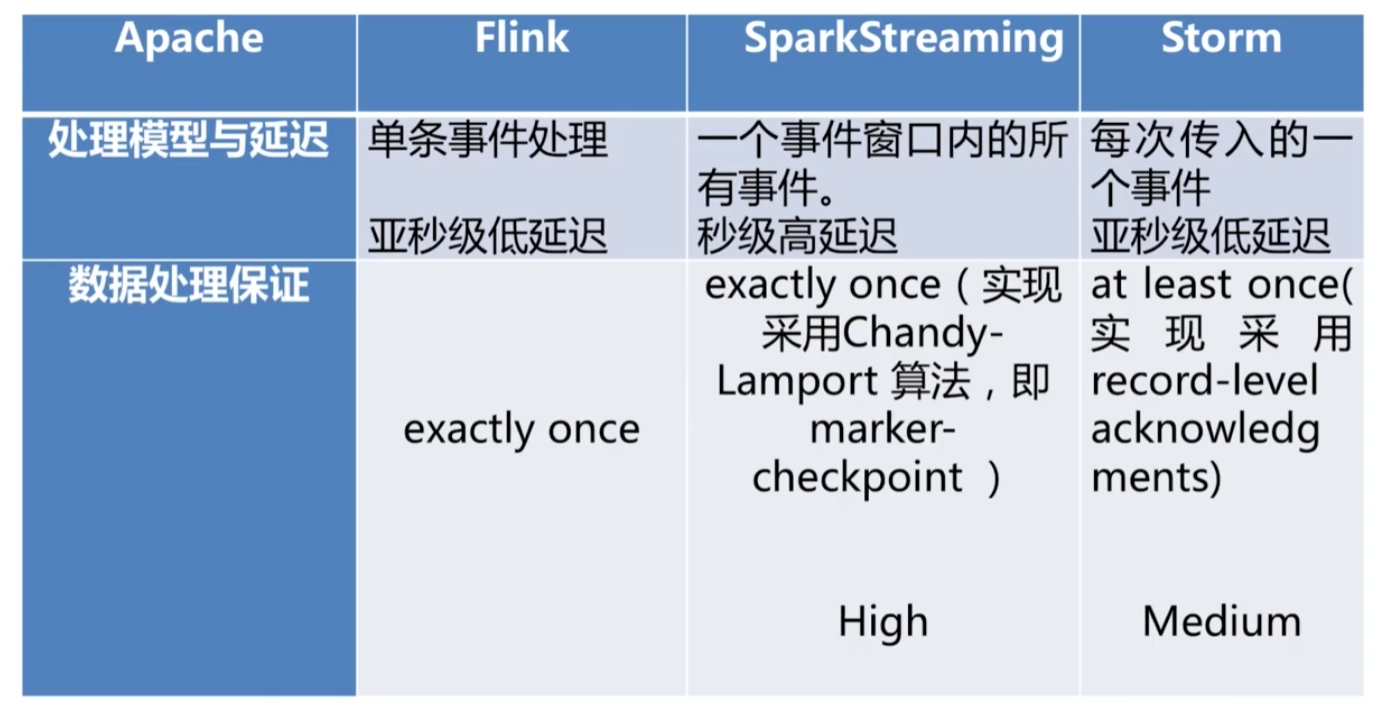
- Apache Flink 特点:现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持毫秒级的低延迟、Exactly-once数据只消费一次保证。而批处理要支持高吞吐、高效处理。
- Flink 完全支持流处理。作为流处理看待时,输入数据流是无界的。Flink将批处理作为一种特殊的流处理,输入的数据流是有界的。
2、Flink组件站
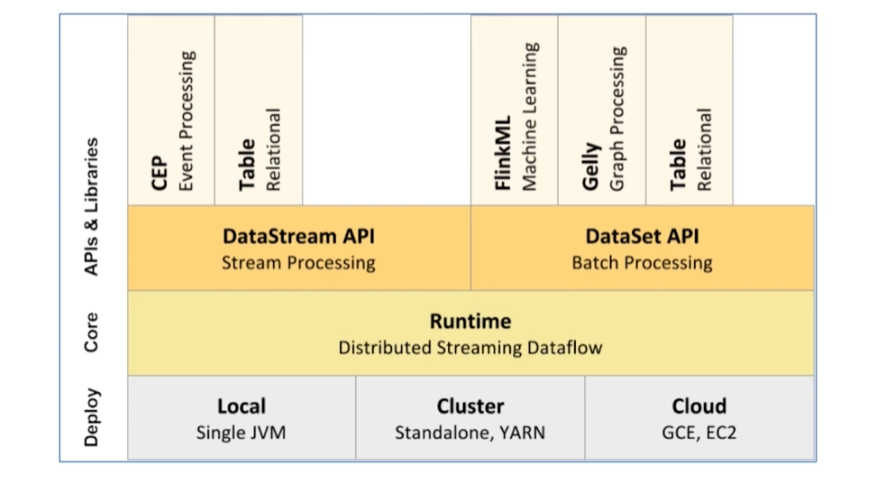
- Flink系统本身是一个分层的架构。
- 从下到上依次有:Deploy(Flink部署层)、Core(核心层,提供Flink本身的一些计算实现)、APIs层(Flink本身暴露出来的一些操作流或者批量数据的API)、Libraries层(Flink自己封装的一些满足特定应用的计算框架)。
- Deployment层:主要涉及Flink的部署模式。Flink支持多种部署模式:本地、集群(Standaline/YARN【在生产环境中主要使用此模式,用于资源管理。】)、云(GCE/EC2)。
- Flink onYarn 模式(绿图):Flink yarn的客户端,直接和 yarn resource manager 进行通信,resource manager向Flink集群申请资源,来启动服务。资源申请好了后,客户端可以直接提交job到链上运行。资源调度这一方面,直接交给resource manager来负责。
- Runtime层:提供了支持Flink计算的全部核心计算。比如:支持分布式stream流处理、Flink内部job graph到 execution graph的映射、调度等。为上层API层提供基础服务。
- API层:主要实现了无界stream的流处理,和面向batch的批处理API。其中面向流处理对应DataStream API,面向批处理对应DataSet API。API层是面向编程者本身的。最终的代码编写都是操作Flink本身暴露API进行编写的。
- Libraries层:在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。提供CEP事件处理模型、table内sql的操作,FlinkML机器学习处理、Gelly图处理。

3、Flink自身优势
- 支持高吞吐、低延迟、高性能的流处理。
- 支持高度灵活的窗口Window操作。
- 支持有状态(假如代码是搜索特定的事件,用户的点击和购买行为,状态会保存这到截至目前为止,遇到的所有这些事件的顺序。)计算的exactly-once(数据只消费一次保证)语义。
- 提供data stream api 和 data set api。