Hive体系架构
1、Hive体系架构
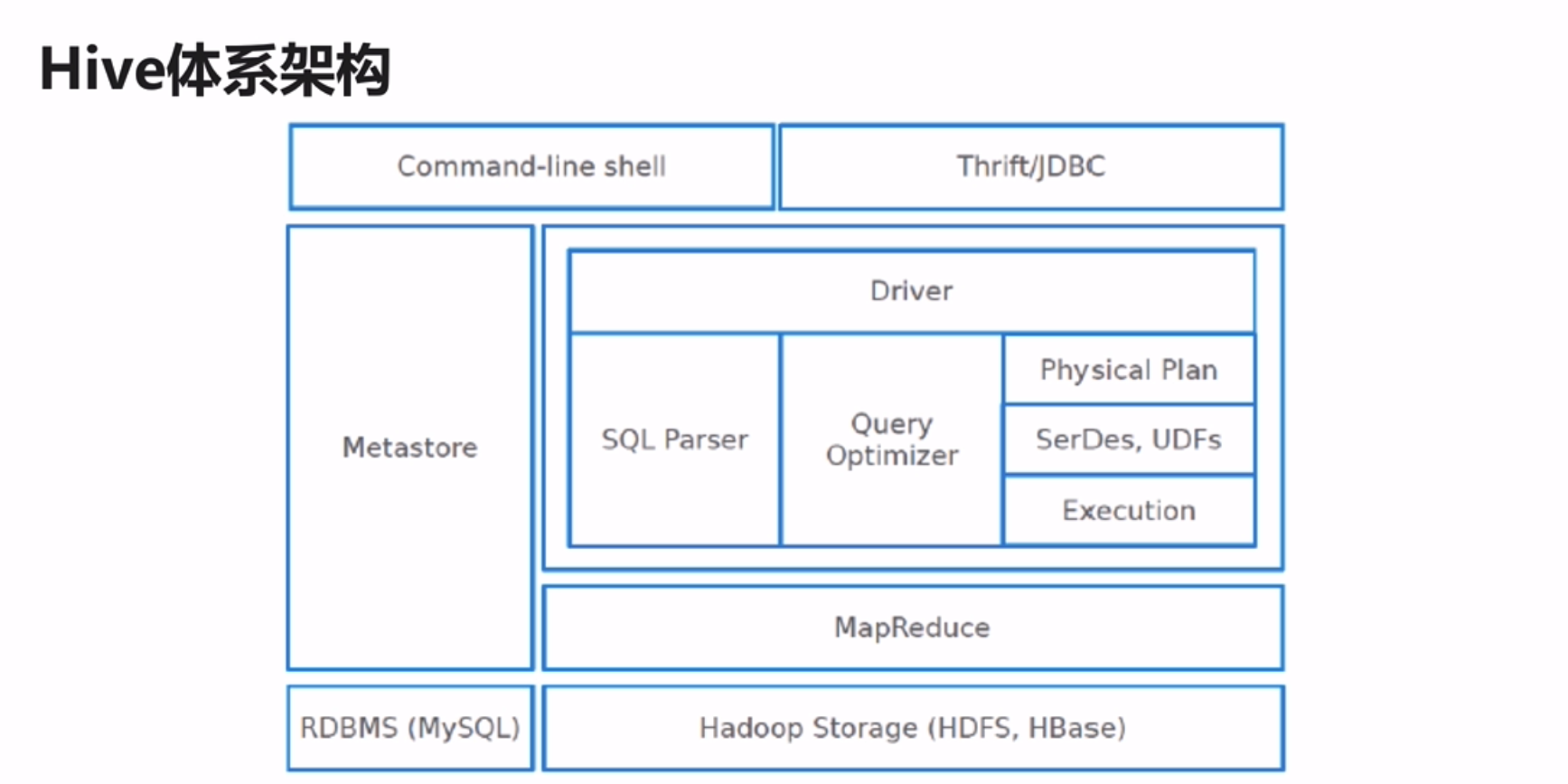
(1)Command-line shell:client在命令行shell上写sql,写完后提交给Hive引擎上。
(2)Thrift/JDBC:看做server/jdbc。Thrift是一种协议,把Hive起成一个服务server,通过JDBC的方式提交sql。额外可以看看WebUI(HUE/Zeppelin)通过图形化界面进行jdbc连接,sql在图形化界面上运行,所有进行可视化的展示。
(3)metastore:即元数据信息,存储在MySQL上
database:name、location、owner...
table:name、location、owner、column name/type...
(4)Driver:
sql语句是普通的字符串,如何让字符串让Hive识别:
Driver编译sql为语法数
首先使用SQL Parser进行解析、编译为语法数
基于这个语法数,使用Query Optimizer进行优化,取出最优的执行计划
最优的执行计划生成物理执行计划
在这个物理执行计划过程中,存在序列化及反序列化SerDes、用户自己定义的函数UDFs
物理执行计划会生成一个Execution
在Execution下,生成一个MapReduce
Driver的这一过程,即将客户端来的sql翻译成MapReduce
(5)最后将作业提交到HDFS,进行执行。