流量统计之自定义Partitioner(第六步)
1、Partitioner即reduce上进行自定义分区个数
先搜索Partitioner.java。
然后在HashPartitioner.java中:
public class HashPartitioner<K, V> extends Partitioner<K, V> { public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
numReduceTasks是根据key获取hashCode(),与Integer.MAX_VALUE做运算,得出结果与numReduceTasks取模值
其中numReduceTasks:Job中所指定的reducer的个数,reducer决定了Job输出的文件数量
HashPartitioner是MapReduce默认的分区规则
假设reducer是3
1 % 3 = 3
2 % 3 = 2
3 % 3 = 0
需求:将统计结果按照手机号的前缀进行区分,并输出到不同的输出文件中去。
13* ==> ..
15* ==> ..
other ==> ..
Partitioner决定maptask输出的数据交由哪个reducetask处理
默认实现:分发的key的hash值与reducetask个数取模

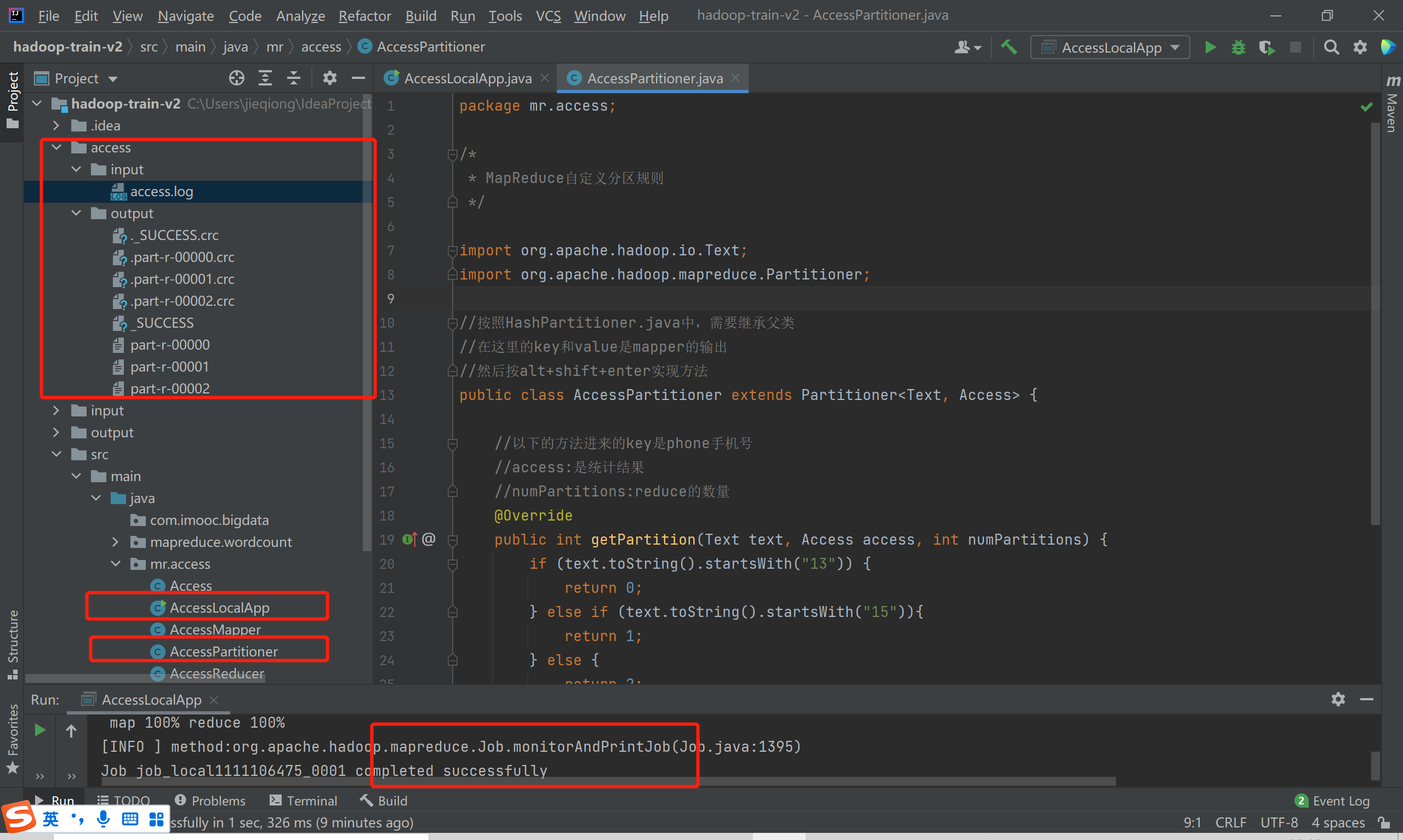
2、AccessPartitioner.java
package mr.access; /* * MapReduce自定义分区规则 */ import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; //按照HashPartitioner.java中,需要继承父类 //在这里的key和value是mapper的输出 //然后按alt+shift+enter实现方法 public class AccessPartitioner extends Partitioner<Text, Access> { //以下的方法进来的key是phone手机号 //access:是统计结果 //numPartitions:reduce的数量 @Override public int getPartition(Text text, Access access, int numPartitions) { if (text.toString().startsWith("13")) { return 0; } else if (text.toString().startsWith("15")){ return 1; } else { return 2; } } }
3、AccessLocalApp.java
添加分区规则和分区个数
//5、设置自定义分区规则 job.setPartitionerClass(AccessPartitioner.class); //设置reduce个位 job.setNumReduceTasks(3);
4、access.log
添加两行数据
031 15161021755 192.168.126.104 200 45 50 032 16161021755 192.168.126.104 200 45 50