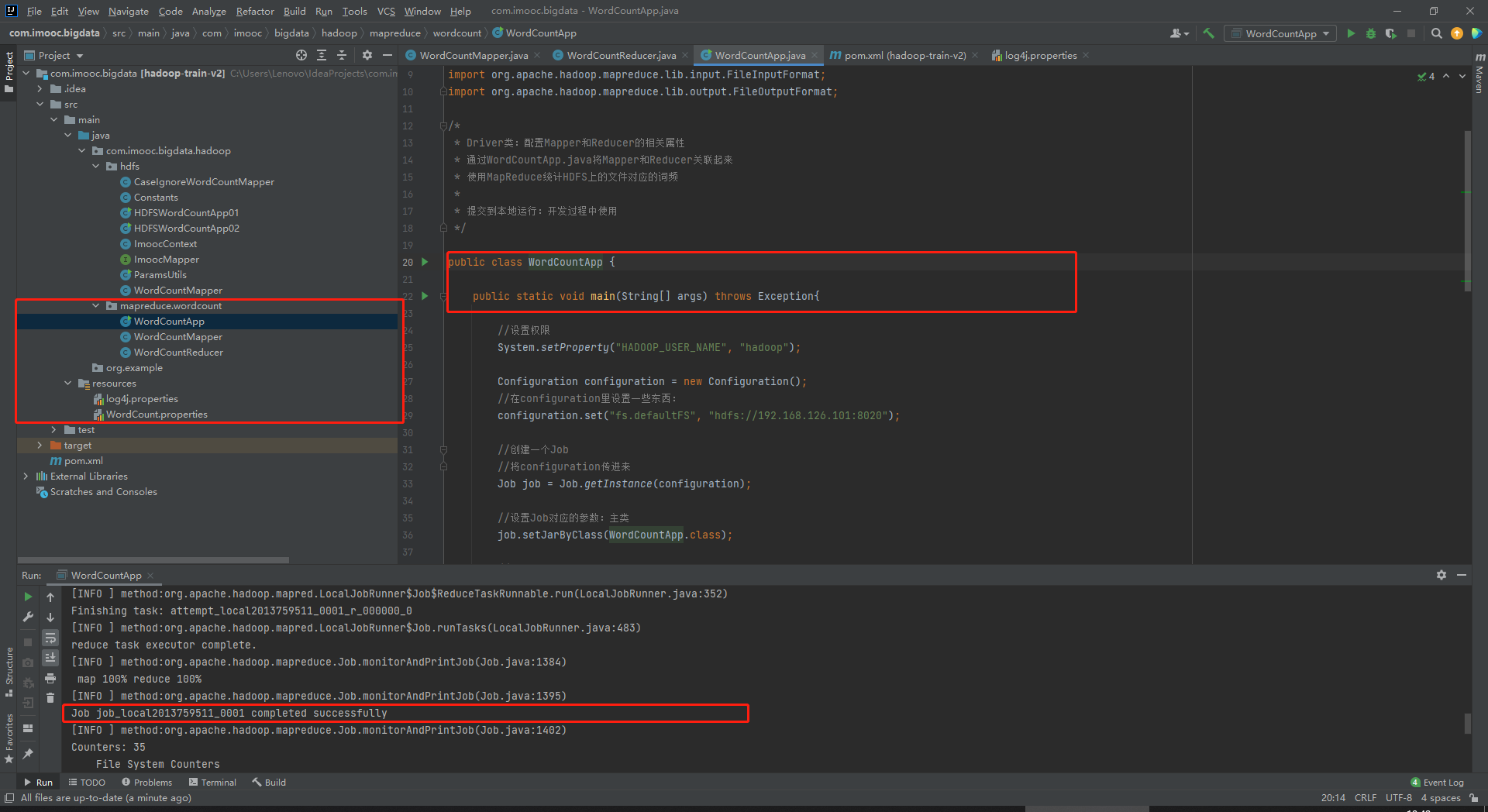
MapReduce自定义Driver类实现(第三步)
1、Driver类:配置Mapper和Reducer的相关属性
通过WordCountApp.java将Mapper和Reducer关联起来
使用MapReduce统计HDFS上的文件对应的词频
提交到本地运行:开发过程中使用
2、WordCountApp.java
package com.imooc.bigdata.hadoop.mapreduce.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /* * Driver类:配置Mapper和Reducer的相关属性 * 通过WordCountApp.java将Mapper和Reducer关联起来 * 使用MapReduce统计HDFS上的文件对应的词频 * * 提交到本地运行:开发过程中使用 */ public class WordCountApp { public static void main(String[] args) throws Exception{ //设置权限 System.setProperty("HADOOP_USER_NAME", "hadoop"); Configuration configuration = new Configuration(); //在configuration里设置一些东西: configuration.set("fs.defaultFS", "hdfs://192.168.126.101:8020"); //创建一个Job //将configuration传进来 Job job = Job.getInstance(configuration); //设置Job对应的参数:主类 job.setJarByClass(WordCountApp.class); //设置Job对应的参数:设置自定义的Mapper和Reducer处理类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //设置Job对应的参数:Mapper输出key和value的类型 //不需要关注Mapper输入 //Mapper<LongWritable, Text, Text, IntWritable> job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Job对应的参数:Reducer输出key和value的类型 //不需要关注Reducer输入 //Reducer<Text, IntWritable, Text, IntWritable> job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置Job对应的参数:Mapper输出key和value的类型:作业输入和输出的路径 FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : -1); } //若输出失败,添加以下代码 static { try { //G:\BaiduNetdiskDownload\hadoop2.7.6\bin\hadoop.dll System.load("G:\\BaiduNetdiskDownload\\hadoop2.7.6\\bin\\hadoop.dll"); } catch (UnsatisfiedLinkError e) { System.err.println("Native code library failed to load.\n" + e); System.exit(1); } } }
3、log4j.properties
由于日志中不报错,添加后,可查看错误原因
在resources中新建file
log4j.rootLogger=INFO,stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=[%-5p] method:%l%n%m%n
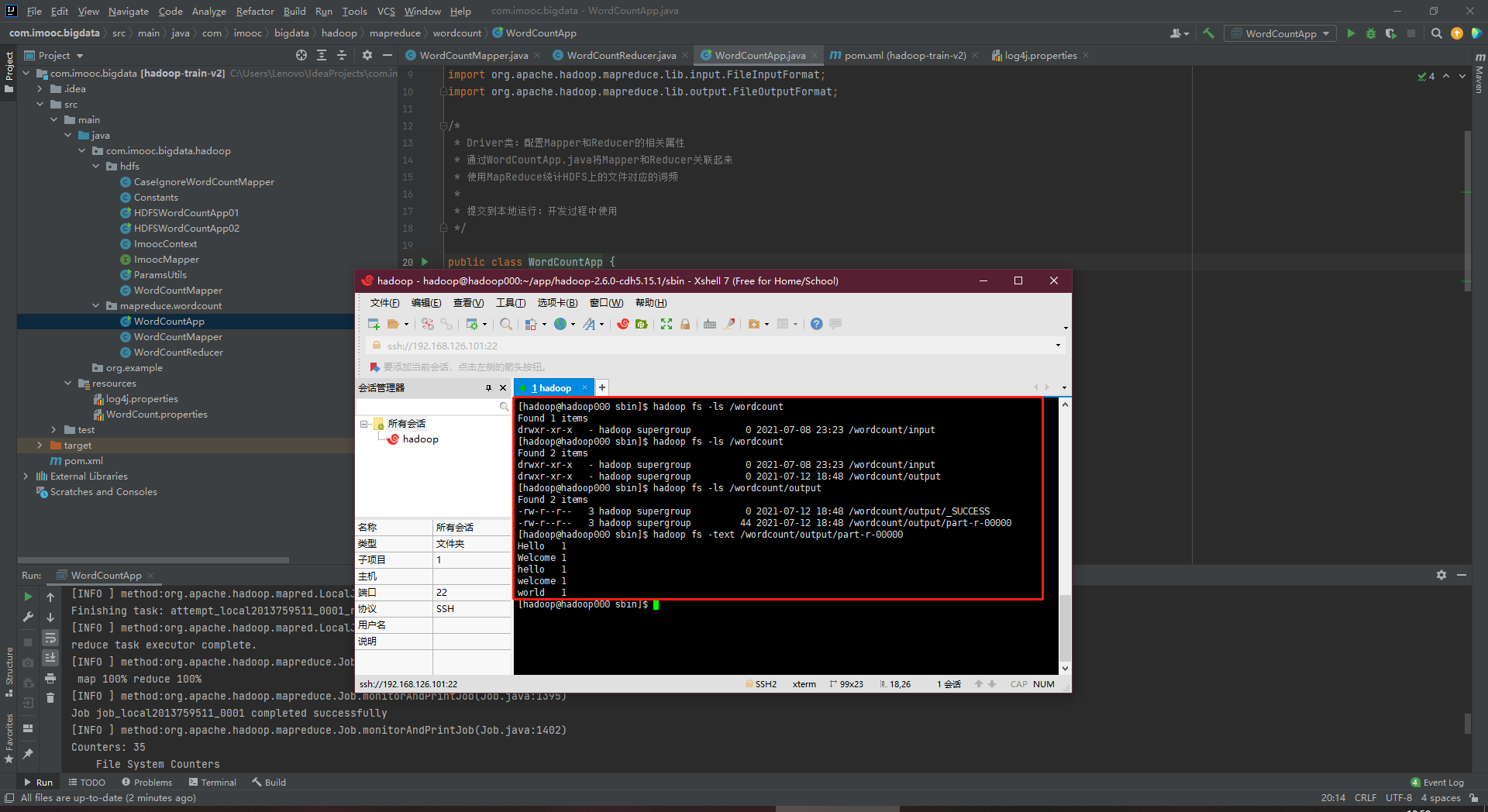
4、在命令行中多层新建input文件夹,并放入文件h.txt
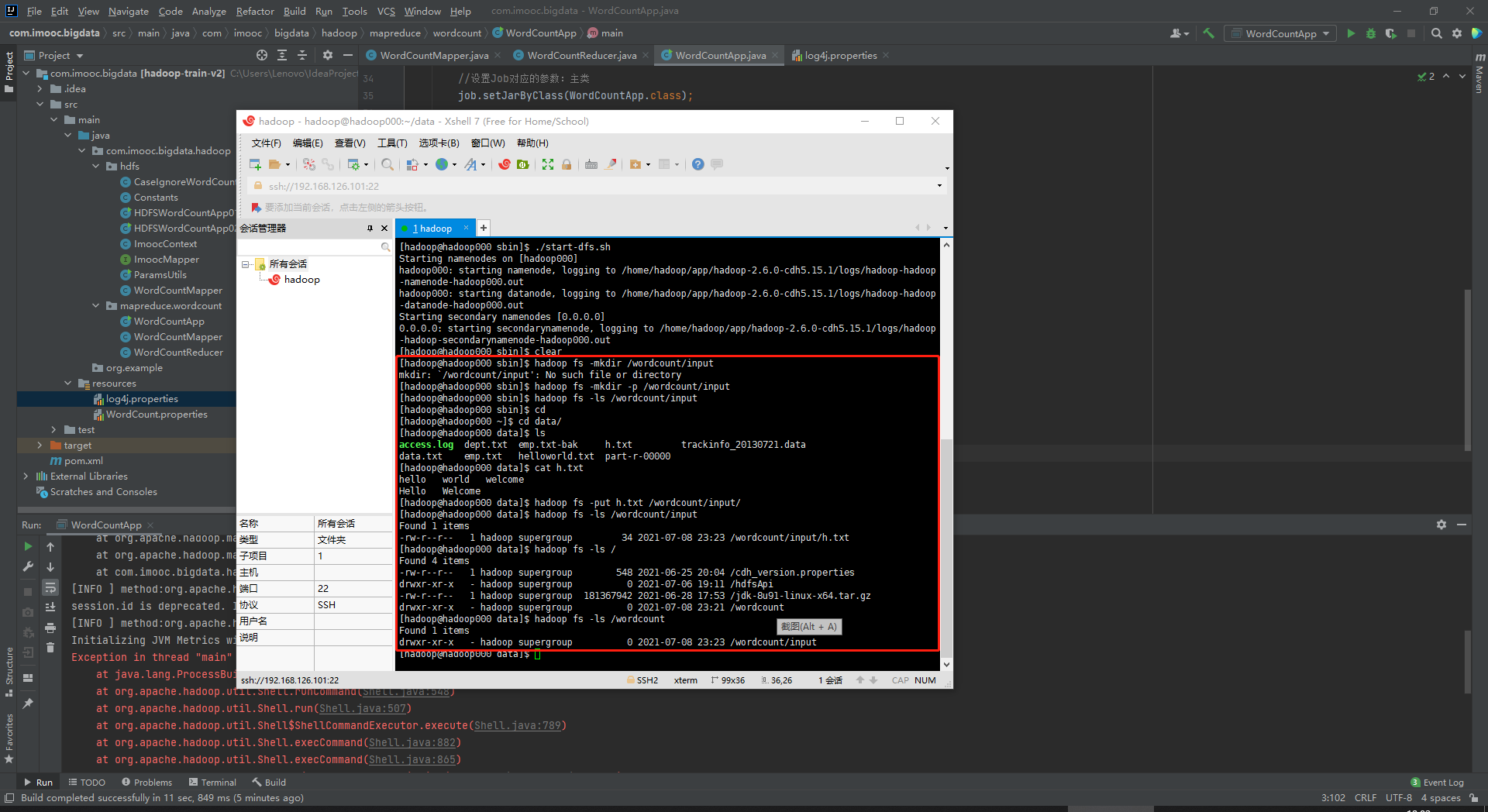
5、运行