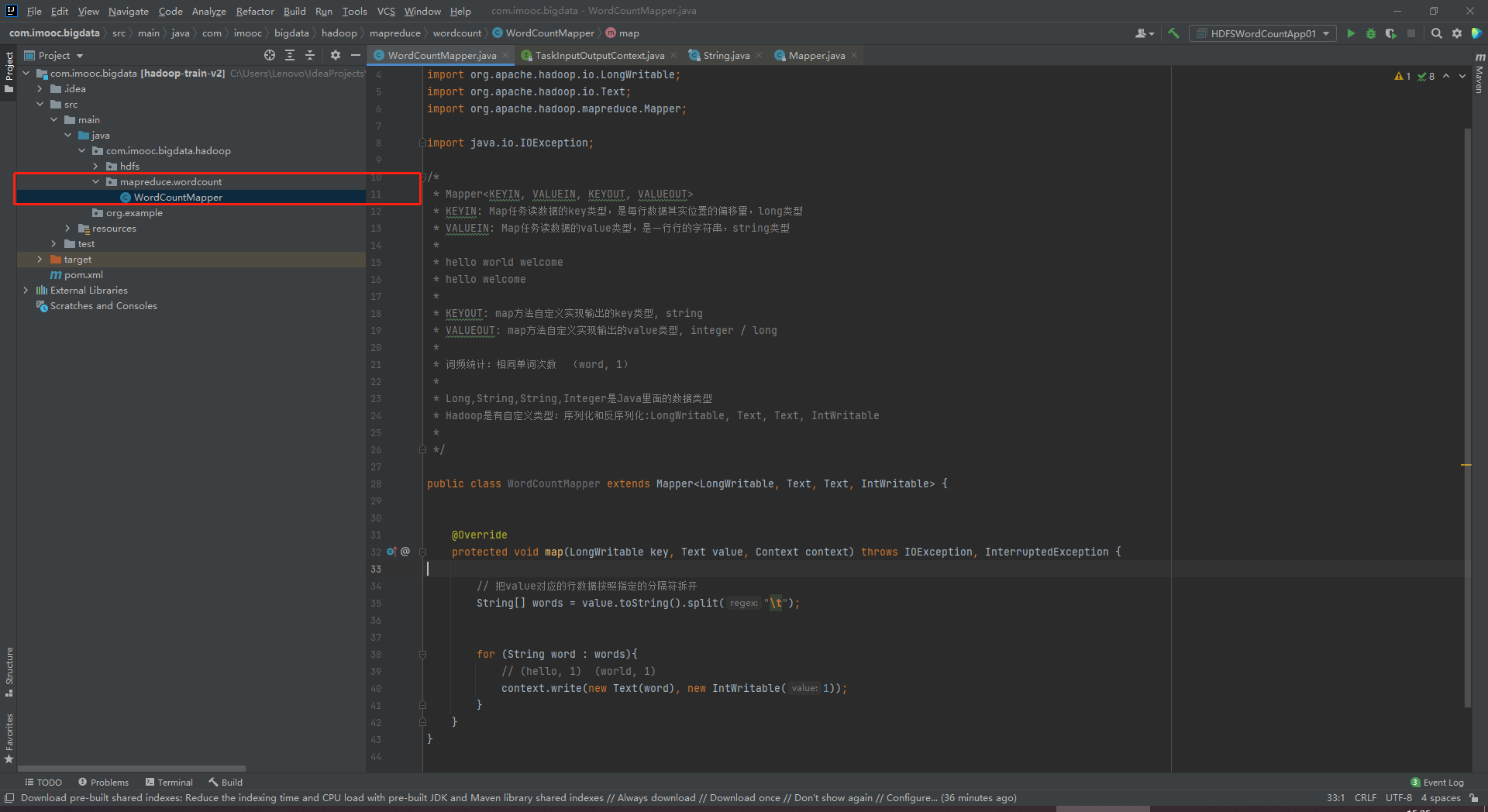
package com.imooc.bigdata.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN: Map任务读数据的key类型,是每行数据其实位置的偏移量,long类型
* VALUEIN: Map任务读数据的value类型,是一行行的字符串,string类型
*
* hello world welcome
* hello welcome
*
* KEYOUT: map方法自定义实现输出的key类型, string
* VALUEOUT: map方法自定义实现输出的value类型, integer / long
*
* 词频统计:相同单词次数 (word, 1)
*
* Long,String,String,Integer是Java里面的数据类型
* Hadoop是有自定义类型:序列化和反序列化:LongWritable, Text, Text, IntWritable
*
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 把value对应的行数据按照指定的分隔符拆开
String[] words = value.toString().split("\t");
for (String word : words){
// (hello, 1) (world, 1)
context.write(new Text(word), new IntWritable(1));
}
}
}