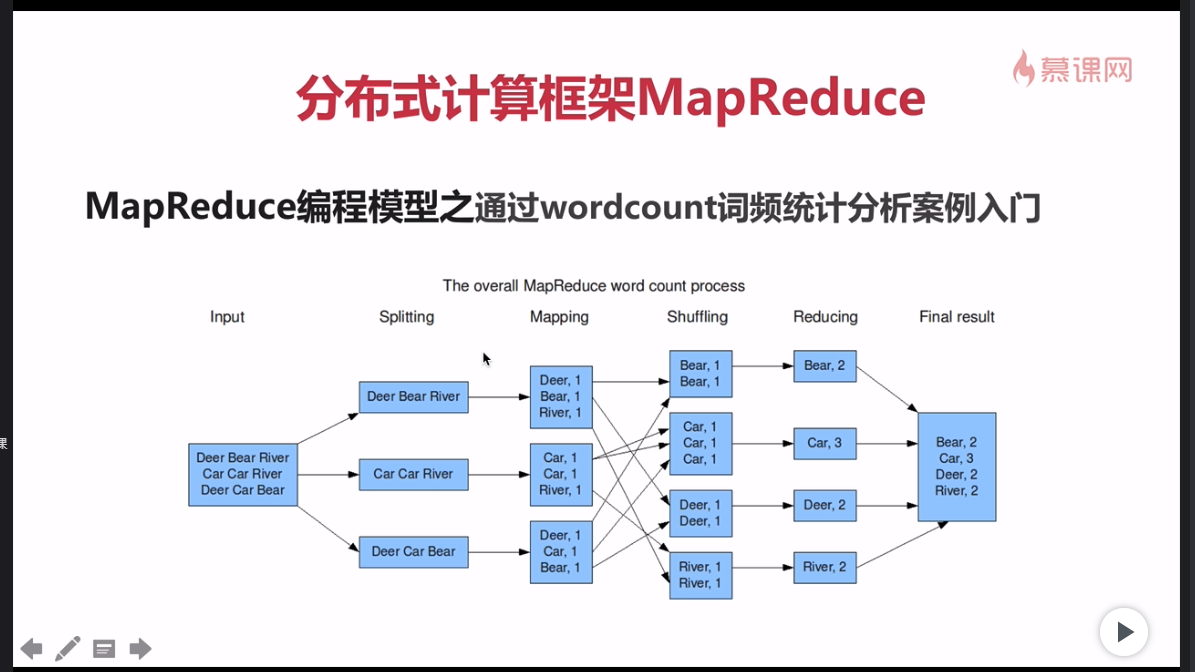
MapReduce编程模型
1、MapReduce编程模型执行步骤
(1)准备map处理的输入数据
(2)Mapper处理
(3)Shuffle
(4)Reduce处理
(5)结果输出
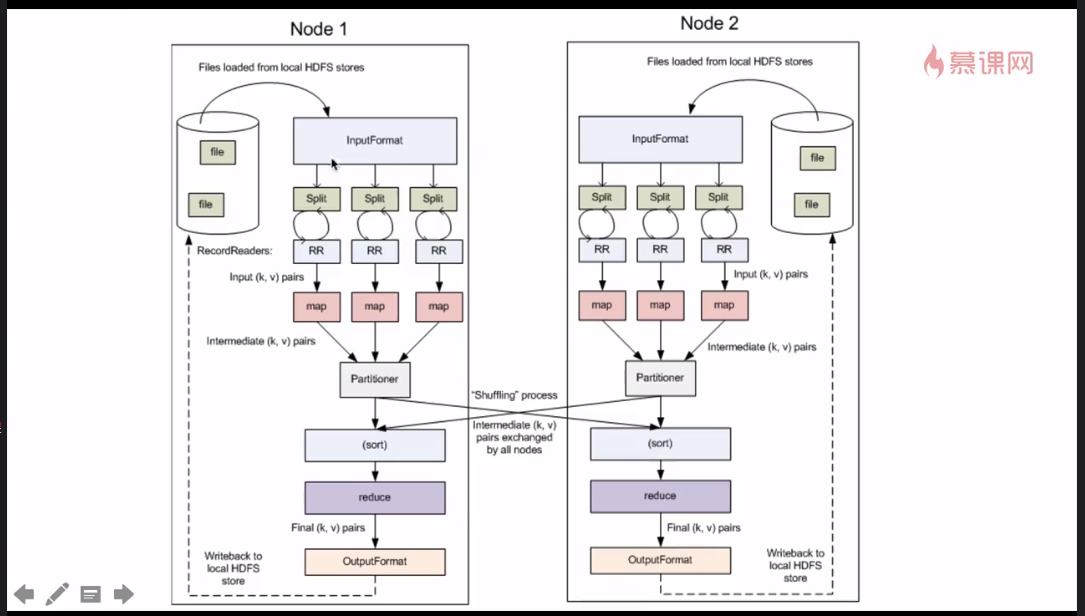
2、图解(同一个作业在不同机制上运行)
(1)NameNode执行文件系统名称空间操作,如打开、关闭和重命名文件和目录。它还确定块到数据节点的映射。
(2)DataNodes负责处理来自文件系统客户机的读写请求。datanode还根据NameNode发出的指令执行块创建、删除和复制。
(3)InputFormat 抽象类,解析文本文件(数据库),将 files-->lines
(4)Split,将文件切片
(5)RecordReader,读取切片文件的东西,内容以键值对的形式存在。
(6)map,将读取的切片放入map里,并形成临时键值对。
(7)Partitioner,主要执行Shuffle,按键值规则进行分区。
(8)sort,在分区过程中,按着一定顺序排序(字母顺序)。map的数据会放在node1,node2上。
(9)Reduce处理,形成最终的键值对。
(10)OutputFormat,将数据文件file写回本地或HDFS中。
3、MapReduce编程模型的5个核心概念
(1)Split
(2)InputFormat
(3)OutputFormat
(4)Combiner
(5)Partitioner