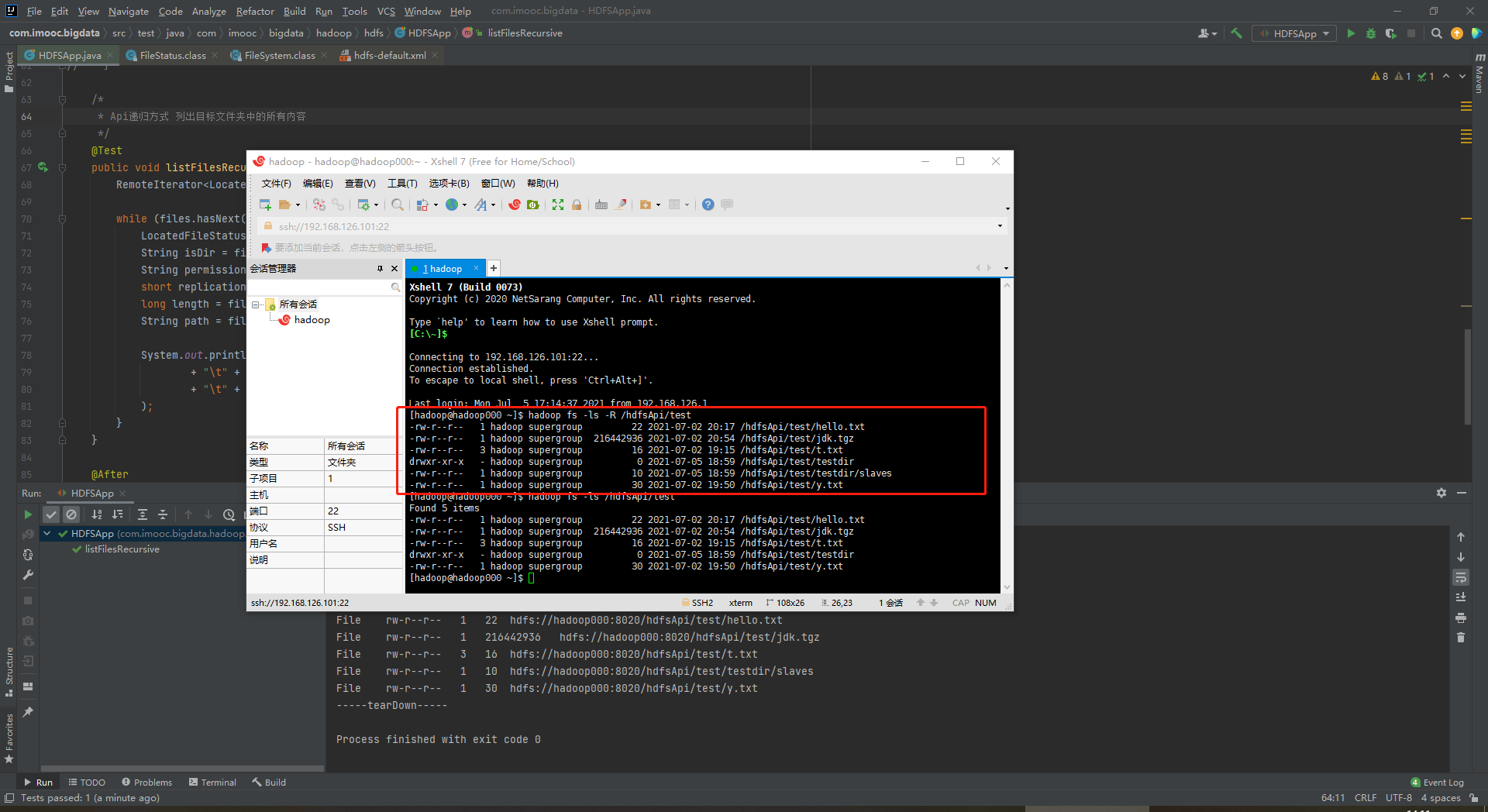
使用Java API之递归方式 列出目标文件夹中的所有内容
package com.imooc.bigdata.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.util.Progress; import org.apache.hadoop.util.Progressable; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; /** * 使用Java API操作HDFS文件系统 * * 因为是放在test下面,所以最好使用单元测试的方式 * 在pom中引入的jUnit单元测试的方式 * 单元测试有两个方法:(1)在单元测试之前进行;(2)在单元测试之后进行 * * 关键点: * 1)创建Configuration * 2)获取FileSystem * 3)剩下的是HDFS API的操作 */ public class HDFSApp { public static final String HDFS_PATH = "hdfs://hadoop000:8020"; //Configuration、FileSystem是每一个方法使用之前必须构建的 Configuration configuration = null; FileSystem fileSystem = null; @Before public void setup() throws Exception{ System.out.println("-----setup-----"); configuration = new Configuration(); configuration.set("dfs.replication", "1"); /* *构造一个访问指定HDFS系统的客户端对象 * 第一个参数:HDFS的URI * 第二个参数:客户端指定的配置参数 * 第三个参数:客户的用户名 */ fileSystem = FileSystem.get(new URI("hdfs://hadoop000:8020"), configuration, "hadoop"); } /* * Api递归方式 列出目标文件夹中的所有内容 */ @Test public void listFilesRecursive() throws Exception{ RemoteIterator<LocatedFileStatus> files = fileSystem.listFiles(new Path("/hdfsApi/test"), true); while (files.hasNext()){ LocatedFileStatus file = files.next(); String isDir = file.isDirectory() ? "Folder " : "File"; String permission = file.getPermission().toString(); short replication = file.getReplication(); long length = file.getLen(); String path = file.getPath().toString(); System.out.println(isDir + "\t" + permission + "\t" + replication + "\t" + length + "\t" + path ); } } @After public void tearDown(){ System.out.println("-----tearDown-----"); //置空 configuration = null; fileSystem = null; } }
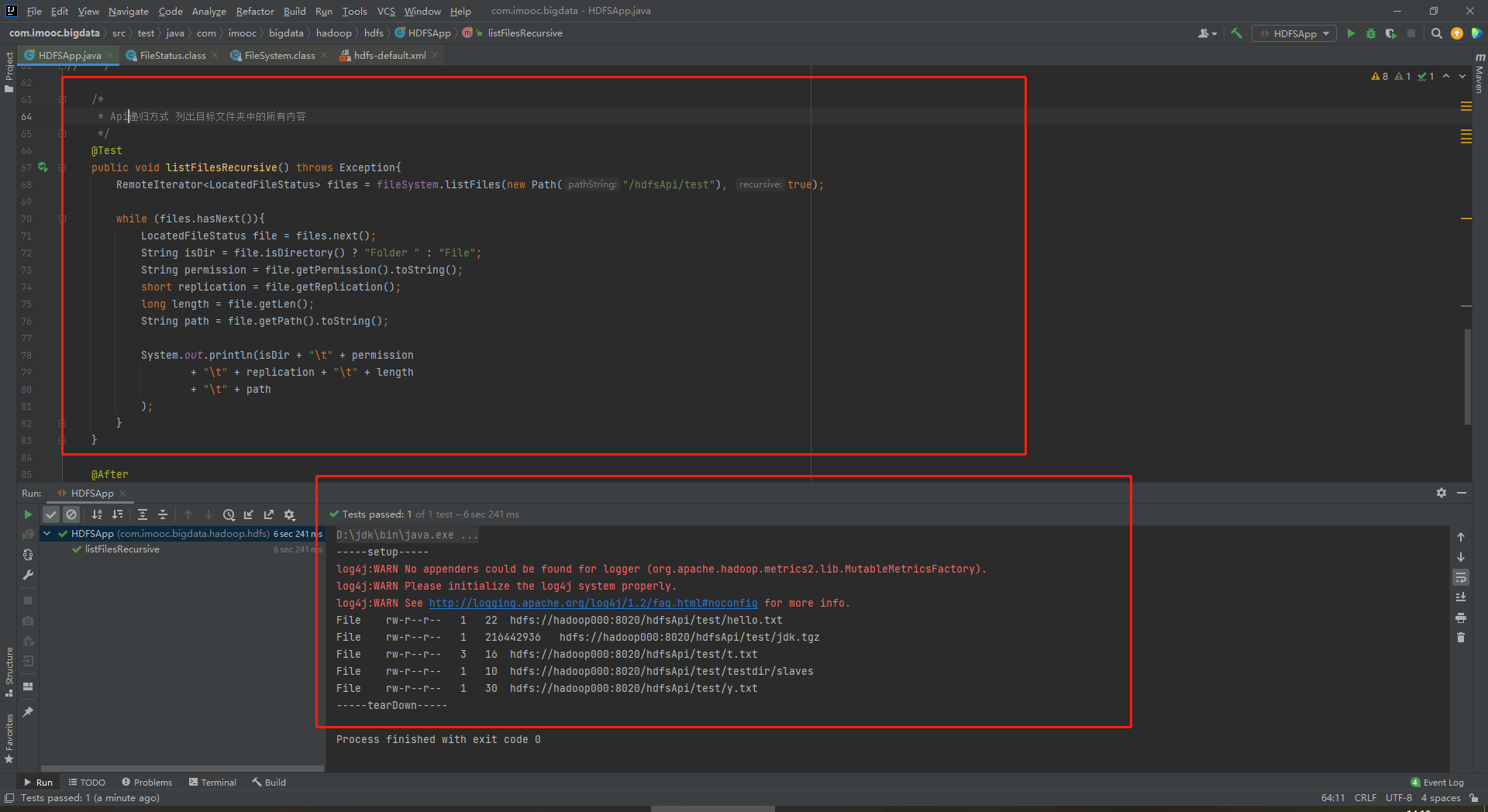
存在命令行递归显示文件夹下所有层级内容
[hadoop@hadoop000 ~]$ hadoop fs -ls -R /hdfsApi/test