1 package com.imooc.bigdata.hadoop.hdfs;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.FSDataInputStream;
5 import org.apache.hadoop.fs.FileSystem;
6 import org.apache.hadoop.fs.Path;
7 import org.apache.hadoop.io.IOUtils;
8 import org.junit.After;
9 import org.junit.Before;
10 import org.junit.Test;
11
12 import java.net.URI;
13
14 /**
15 * 使用Java API操作HDFS文件系统
16 *
17 * 因为是放在test下面,所以最好使用单元测试的方式
18 * 在pom中引入的jUnit单元测试的方式
19 * 单元测试有两个方法:(1)在单元测试之前进行;(2)在单元测试之后进行
20 *
21 * 关键点:
22 * 1)创建Configuration
23 * 2)获取FileSystem
24 * 3)剩下的是HDFS API的操作
25 */
26
27 public class HDFSApp {
28
29 public static final String HDFS_PATH = "hdfs://hadoop000:8020";
30 //Configuration、FileSystem是每一个方法使用之前必须构建的
31 Configuration configuration = null;
32 FileSystem fileSystem = null;
33
34 @Before
35 public void setup() throws Exception{
36 System.out.println("-----setup-----");
37
38 configuration = new Configuration();
39 /*
40 *构造一个访问指定HDFS系统的客户端对象
41 * 第一个参数:HDFS的URI
42 * 第二个参数:客户端指定的配置参数
43 * 第三个参数:客户的用户名
44 */
45 fileSystem = FileSystem.get(new URI("hdfs://hadoop000:8020"), configuration, "hadoop");
46 }
47
48 /*
49 * 查看HDFS文件夹内容
50 */
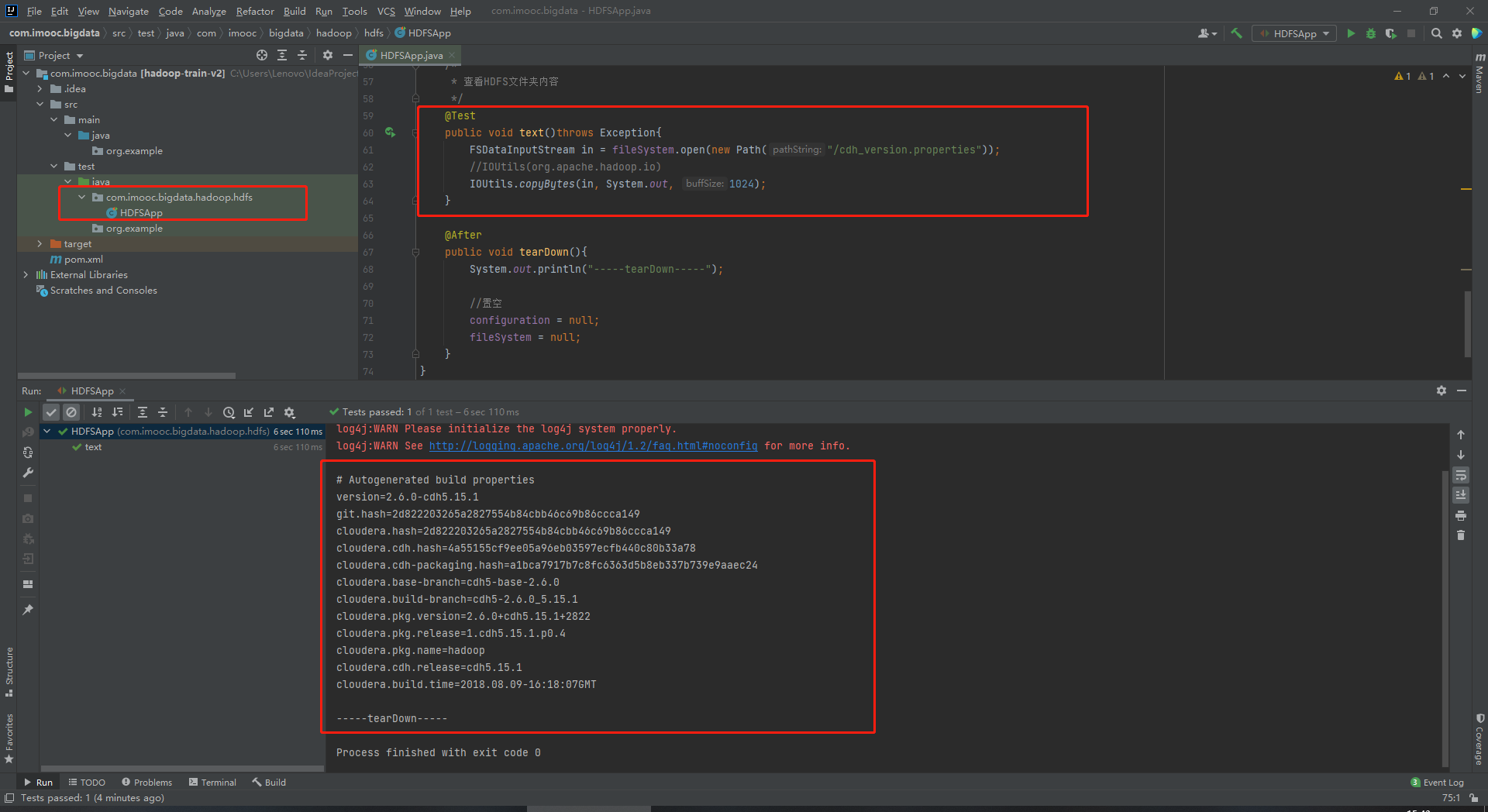
51 @Test
52 public void text()throws Exception{
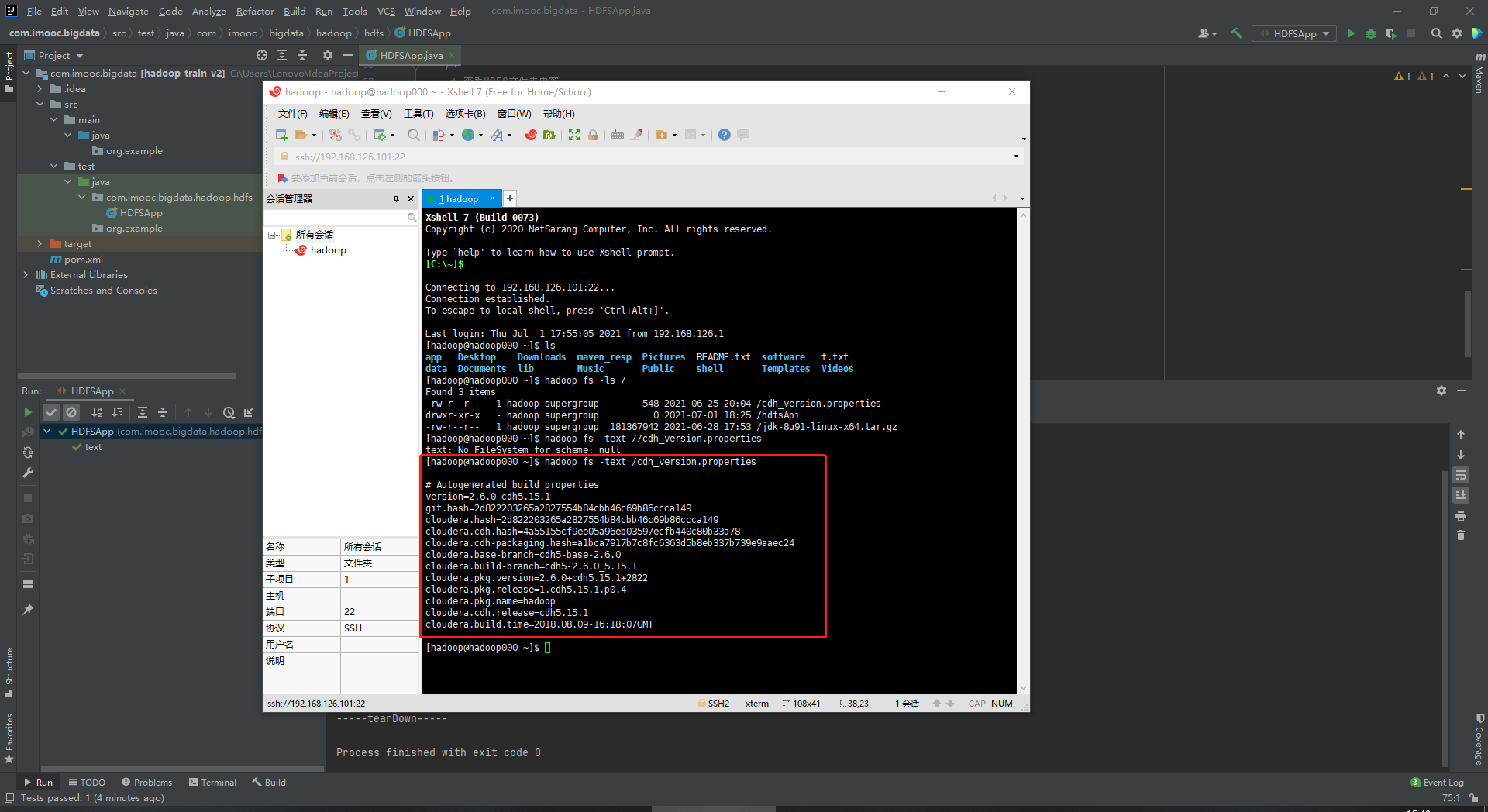
53 FSDataInputStream in = fileSystem.open(new Path("/cdh_version.properties"));
54 //IOUtils(org.apache.hadoop.io)
55 IOUtils.copyBytes(in, System.out, 1024);
56 }
57
58 @After
59 public void tearDown(){
60 System.out.println("-----tearDown-----");
61
62 //置空
63 configuration = null;
64 fileSystem = null;
65 }
66 }