3D U-Net卷积神经网络
3D U-Net这篇论文的诞生主要是为了处理一些块状图(volumetric images),基本的原理跟U-Net其实并无大差,因为3D U-Net就是用3D卷积操作替换了2D的,不过在这篇博文中我会按照论文的结构大概介绍一下整体的原理及结构运用。当然在原本的论文中,论文作者为了证实框架的可执行性及实验的最终结果,是设立了两组不同的实验的,一个是半自动设置(即:人为地利用算法对3D图像中地某些切片(slices)进行标注然后再放入模型中去跑程序),而另外一种情况则是作者假设有代表性地,稀疏地标注训练集是存在地,直接将数据输入模型进行end-to-end地训练,这部分地处理我将不详细描述,有兴趣的朋友或者小伙伴请点击下面论文链接进行下载阅读理解,在博文中将主要讲述3D U-Net的结构及特征。
论文地址:https://arxiv.org/abs/1606.06650
这里附上我自己基于PyTorch复现的代码(主体部分已经完成,还在继续完善中):https://github.com/JielongZ/3D-UNet-PyTorch-Implementation
1. 介绍(Introduction)
生物医学影像(biomedical images)很多时候都是块状的,也就是说是由很多个切片构成一整张图的存在。如果是用2D的图像处理模型去处理3D本身不是不可以,但是会存在一个问题,就是不得不将生物医学影像的图片一个slice一个slice成组的(包含训练数据和标注好的数据)的送进去设计的模型进行训练,在这种情况下会存在一个效率问题,因而很多时候处理块状图的时候会让任感到不适,并且数据预处理的方式也相对比较繁琐(tedious)。
所以,论文的作者就提出来了3D -Net模型,模型不仅解决了效率的问题,并且对于块状图的切割只要求数据中部分切片被标注即可(可参考下图说明)。

2. 模型结构(Network Architecture)
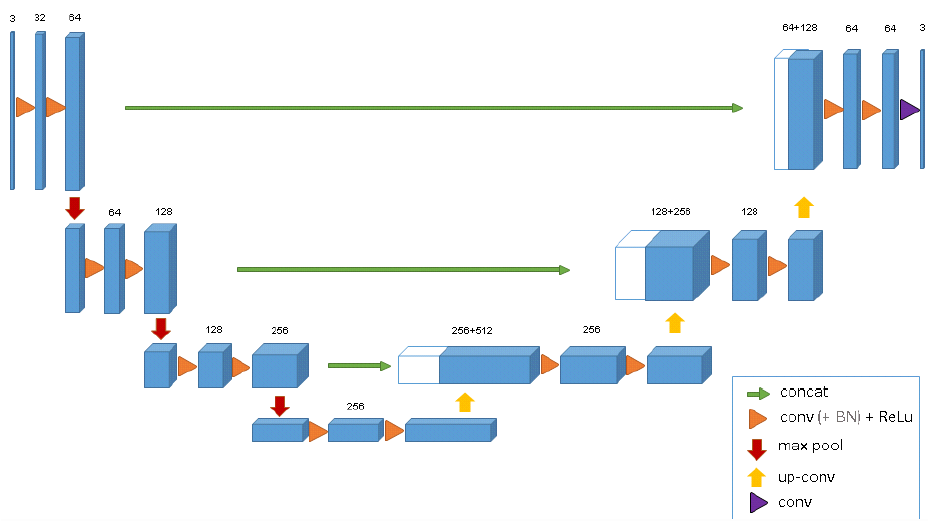
整个3D U-Net的模型是基于之前U-Net(2D)创建而来,同样包含了一个encoder部分和一个decoder部分,encoder部分是用来分析整张图片并且进行特征提取与分析,而与之相对应的decoder部分是生成一张分割好的块状图。论文中使用的输入图像的大小是132 * 132 * 116,整个网络的结构前半部分(analysis path)包含及使用如下卷积操作:
a. 每一层神经网络都包含了两个 3 * 3 * 3的卷积(convolution)
b. Batch Normalization(为了让网络能更好的收敛convergence)
c. ReLU
d. Downsampling:2 * 2 * 2的max_polling,步长stride = 2
而与之相对应的合成路径(synthesis path)则执行下面的操作:
a. upconvolution: 2 * 2 * 2,步长=2
b. 两个正常的卷积操作:3 * 3 * 3
c. Batch Normalization
d. ReLU
e. 于此同时,需要把在analysis path上相对应的网络层的结果作为decoder的部分输入,这样子做的原因跟U-Net博文提到的一样,是为了能采集到特征分析中保留下来的高像素特征信息,以便图像可以更好的合成。
整体的一个网络结构如下图所示,其实可以看出来跟2D结构的U-Net是基本一样,唯一不同的就是全部2D操作换成了3D,这样子做了之后,对于volumetric image就不需要单独输入每个切片进行训练,而是可以采取图片整张作为输入到模型中(PS:但是当图像太大的时候,此时需要运用random crop的技巧将图片随机裁切成固定大小模块的图片放入搭建的模型进行训练,当然这是后话,之后将会在其他文章中进行介绍)。除此之外,论文中提到的一个亮点就是,3D U-Net使用了weighted softmax loss function将未标记的像素点设置为0以至于可以让网络可以更多地仅仅学习标注到的像素点,从而达到普适性地特点。
3. 训练细节(Training)
3D U-Net同样采用了数据增强(data augmentation)地手段,主要由rotation、scaling和将图像设置为gray,于此同时在训练数据上和真实标注的数据上运用平滑的密集变形场(smooth dense deformation field),主要是通过从一个正态分布的随机向量样本中选取标准偏差为4的网格,在每个方向上具有32个体素的间距,然后应用B样条插值(B-Spline Interpolation,不知道什么是B样条插值法的可以点连接进行查看,在深度学习模型的创建中有时候也不需要那么复杂,所以这里仅限了解,除非本身数学底子很好已经有所了解),B样条插值法比较笼统地说法就是在原本地形状上找到一个类似地形状来近似(approximation)。之后就对数据开始进行训练,训练采用的是加权交叉熵损失(weighted cross-entropy loss function)以至于减少背景的权重并增加标注到的图像数据部分的权重以达到平衡的影响小管和背景体素上的损失。
实验的结果是用IoU(intersection over union)进行衡量的,即比较生成图像与真实被标注部分的重叠部分。3D U-Net的IoU的具体公式如下:
IoU = True Positives / (True Positives + Falese Negatives + False Positives)
4. 总结
论文针对肾脏的生物医学影像的分割结果达到了IoU=86.3%的结果。3D U-Net的诞生在医学影像分割,特别是那些volumetric images都是由很大帮助的,因为它很大程度上解决了3D图像一个个slice送入模型进行训练的尴尬局面,也大幅度的提升训练效率,并且保留了FCN和U-Net本来具备的优秀特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号