解析Wide Residual Networks
Wide Residual Networks (WRNs)是2016年被提出的基于扩展通道数学习机制的卷积神经网络。对深度卷积神经网络有了解的应该知道随着网络越深性能越好,但是训练深度卷积神经网络存在着这样子那样子的问题,如梯度消失/弥散(gradient vanishing/exploding)。当然除此之外,实验结果也表明越深的网络结构/模型带来的性能提升并不是很明显,反而会需要大量的计算资源来做支撑(具体可看ResNet系列结果)。
那WRNs究竟干了什么呢?在这之前,作者的观点是过往大家对于残差网络(Residual Networks)的研究基本都停留在了如何加深残差网络的深度和编排残差模块的内部结构,所以作者就提出能否通过增大网络结构的width来改善网络的性能的假设。也就是说希望通过使用更浅层的网络来获得跟跟深度网络媲美的准确度。
简单点说ResNet存在的问题有如下:
- He Kaiming大神设计的ResNet卷积神经网络是通过不断增加层数的传统叠加式的卷积神经网络,即使在这值终引入了bottleneck block来减少参数;
- 在训练的过程中,模型中可能只有部分模块具备很好的表征能力,这就相当于减弱了特征复用的情况;

图 1 不同的Residual Blocks
ResNet的典型Residual Block是由两个conv 3x3构成的或者conv 1x1 -> conv 3x3 -> conv 1x1 (参看上图左边两个小图)。而WRNs则通过增加作用于同一个输入的通道数(channels)来构建模型,除此之外有一个很重要的点需要注意:WRNs的作者重新定义了如何使用Dropout来正则化继而防止模型过拟合。增加通道数获取更多的特征图跟增加层数一样都会增加网络模型种的参数量,所以需要借助一定的正则化方法(BatchNorm或者Dropout)来防止过拟合。以往的卷积神经网络Dropout都是放在一层网络的所有卷积操作之后,但是在这个实验中作者将Dropout放到了两个conv 3x3的卷积中间,并经过测试验证如此的结构设计所带来的效果要比以前的设计模式所带来的效果更好(作者之所以没使用BN(BatchNorm)是因为觉得它需要有数据增强的辅助,这点我查找了些资料并没有看到出自哪里,有朋友了解的话劳烦留言告知一下。文中提到的另外一点说BN也并不是大多数时候都需要的,这点估计指的是可能受限于Batch大小的选择原因,这点倒是可以说得通,这可以看我关于BN的分析的博客,但是放在这里说不用可能会有点牵强。),当然作者并不是完全没有使用BN,而是Dropout和BN都用了,BN主要放在Residual Block之间(BN-ReLU-Conv,注意这里跟以往的结构也是不一样,以往的结构都是Conv-BN-ReLU)。
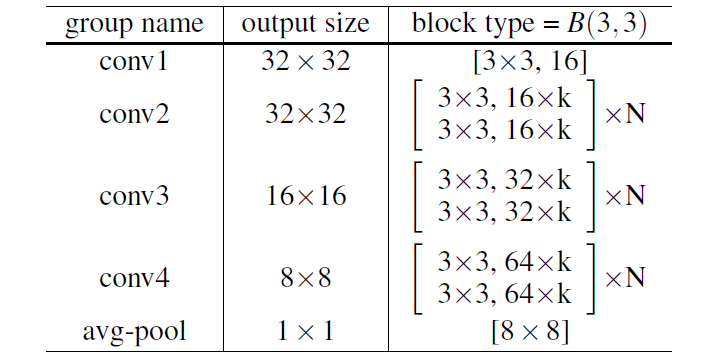
图 2 WRNs网络结构
从上述的网络结构中看三个超参数:l (小写的L)、k、N。网络深度l、通道系数k、一组中有N个Residual Block。为什么要看这几个超参数呢?因为它主要影响了模型中的参数总量。假设保持某卷积层的通道数(也就是所谓的width of the network)不变,增加N层操作将会增加参数的量为:N * (kernel_size * kernel_size) * #channels。那么如果此时增加通道数,也就是k的值,那么参数的量就会呈平方增加:N * (kernel_size * kernel_size) * # channels * 2 (k=2)。咋一看就会觉得这哪里有减少计算量,反而计算量成倍的增长啊。但是作者强调GPU计算适合并行计算,所以总体来说还是computational efficiency。

图 3 k对网络结构的影响(图片来源:Understanding Wide Residual Networks)
结果比对:从图3的CIFAR-10实验结果可以看出一些ResNet-1202有10.2M个参数,error为7.93,反观WRN-40-4的结果要好很多,参数量也稍微少点。当然从Paper中另外一幅图也可以看出WRN的训练速度要比更深的网络ResNet-1004要快得多(快8倍的速度)。

图 4 基于CIFAR-10和CIFAR-100的结果比对

图 5 训练速度比对
论文的主要几个贡献点:
- 重新定义了如何使用Dropout;
- 确实不一定要更深的网络(thin and deeper)来训练模型,WRN也可以达到相同的效果;
- BN-ReLU-CONV训练的速度要比CONV-BN-ReLU的快,且准确度更好(其实BN放在哪里一直有争议,所以持怀疑态度!);
这里谈谈几点个人观点(纯粹讨论,有能解决我疑惑的朋友欢迎指出):
- Wide ResNet的贡献点并不是很能说服人,我个人更认为它是简化版的GoogLeNet(参考Inception Module);
- 上述的贡献的最后一点,我也说了BN放在哪里一直比较有争议,我当初做课题研究的时候也有过这个疑惑,个人认为BN的位置并不是决定训练速度的重要观点;
- WRN的实验设置个人觉得比较有问题,其实对于ResNet普通版本(这里指非1000层以上的)来说性能比WRN没差多少,但是参数量和速度比WRN要好(这里指K>4),所以并没有太大的一个优势存在,这里从作者本身的论文可以看出。当然作者的重点是为了强调“深层网络(几百到1000)”这样子的网络其实是没必要的,通过增加通道数(number of feature maps)也可以达到相应的效果;
- 个人对于Dropout的新的使用方法比较认可;
原文链接地址:Sergey Zagoruyko and Nikos Komodakis, Wide Residual Networks, arXiv:1605.07146v4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号