元素定位
find_element_by_link_text()方法通过元素标签对之间的文本信息来定位元素。不过,需要强调的是
Python 对于中文的支持并不好,如查Python 在执行中文的地方出现在乱码,可以在中文件字符串的前面
加个小“u”可以有效的避免乱码的问题,加u 的作用是把中文字符串转换中unicode 编码,如:
find_element_by_link_text(u"新闻")
加r的作用是避免转义(r'12as\n)
webdriver 提供了八种元素定位方法:
id
name
class name
tag name
link text
partial link text
xpath
css selector
在Python 语言中对应的定位方法如下:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
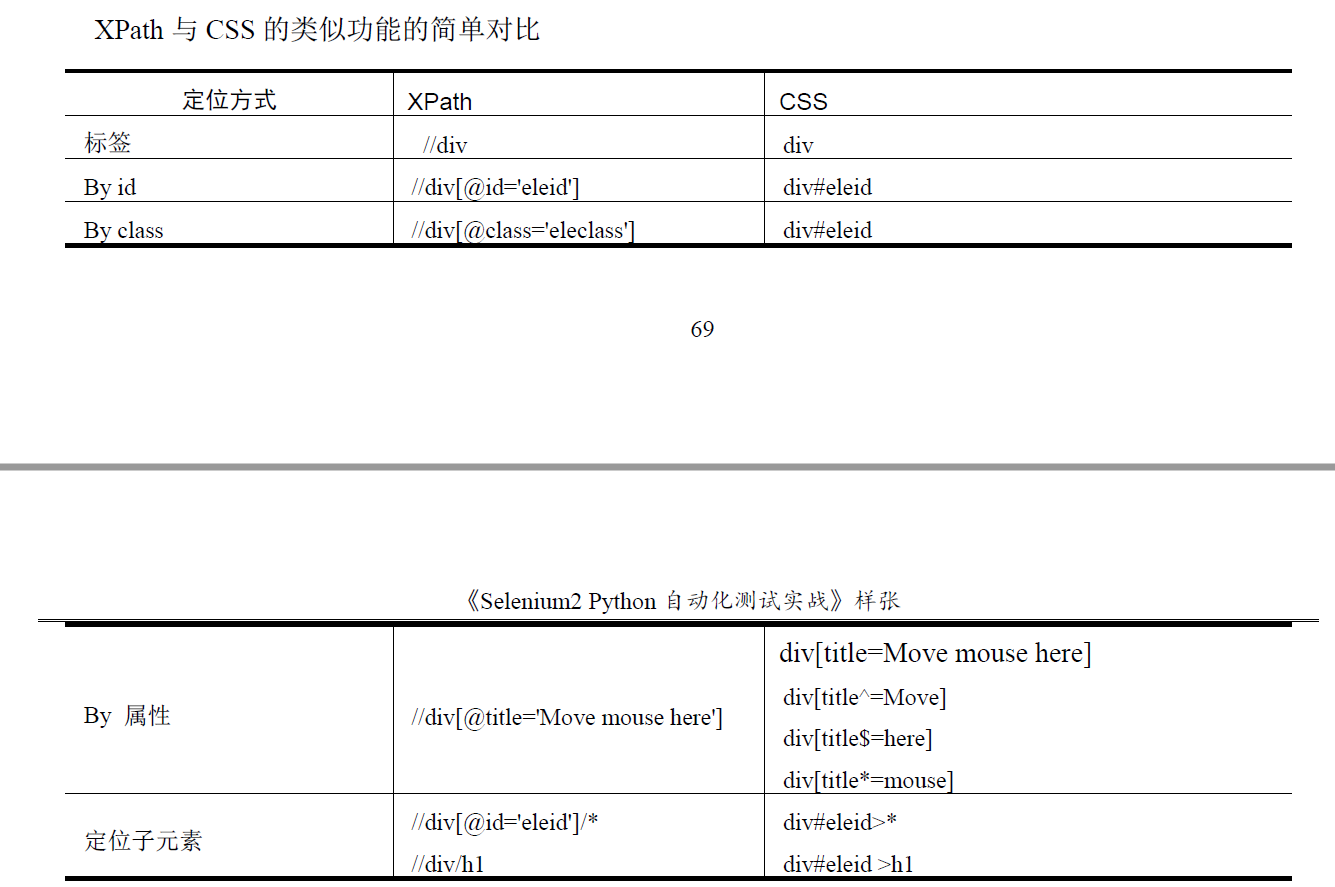
css方式定位:
通过class 属性定位:
find_element_by_css_selector(".s_ipt")
find_element_by_css_selector(".bg s_btn")
find_element_by_css_selector()方法用于CSS 语言定位元素,点号(.)表示通过class 属性来定位元素。
通过id 属性定位:
find_element_by_css_selector("#kw")
find_element_by_css_selector("#su")
井号(#)表示通过id 属性来定位元素。
通过标签名定位:
find_element_by_css_selector("input")
在CSS 语言中用标签名定位元素不需要任何符号标识,直接使用标签名即可,但我们前面已经了解到
标签名重复的概率非常大,所以通过这种方式很难唯一的标识一个元素。
通过父子关系定位:
find_element_by_css_selector("span>input")
上面的写法表示有父亲元素,它的标签名叫span,查找它的所有标签名叫input 的子元素。
通过属性定位:
find_element_by_css_selector("input[autocomplete='off']")
find_element_by_css_selector("input[maxlength='100']")
find_element_by_css_selector("input[type='submit']")
在CSS 当中也可以使用元素的任意属性,只要这些属性可以唯一的标识这个元素。
组合定位:
我们当然可以把上面的定位策略组合起来使用,这样就大大加强了元素的唯一性。
find_element_by_css_selector("span.bg s_ipt_wr>input.s_ipt")
find_element_by_css_selector("span.bg s_btn_wr>input#su")
有一个父元素,它的标签名叫span,它有一个class 属性值叫bg s_ipt_wr,它有一个子元素,标签名
叫input,并且这个子元素的class 属性值叫s_ipt。好吧!我们要找的就是具有这么多特征的一个子元素。