
mysql.进阶01
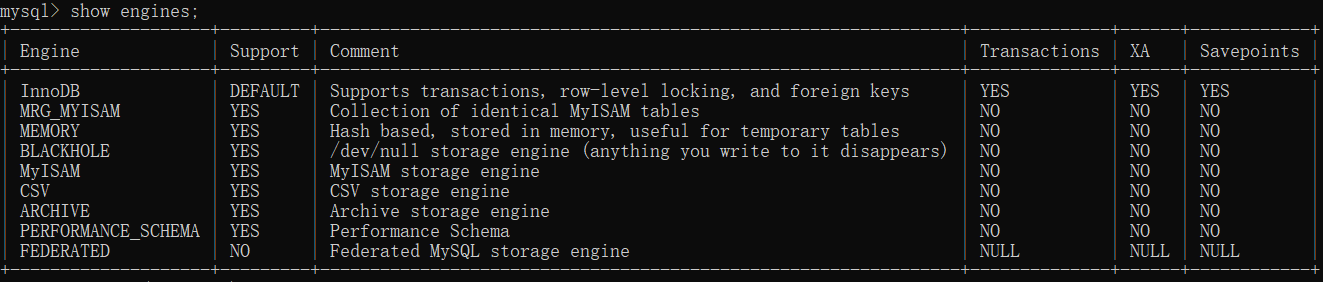
01.查询mysql支持的存储引擎
> 创建表时进行配置

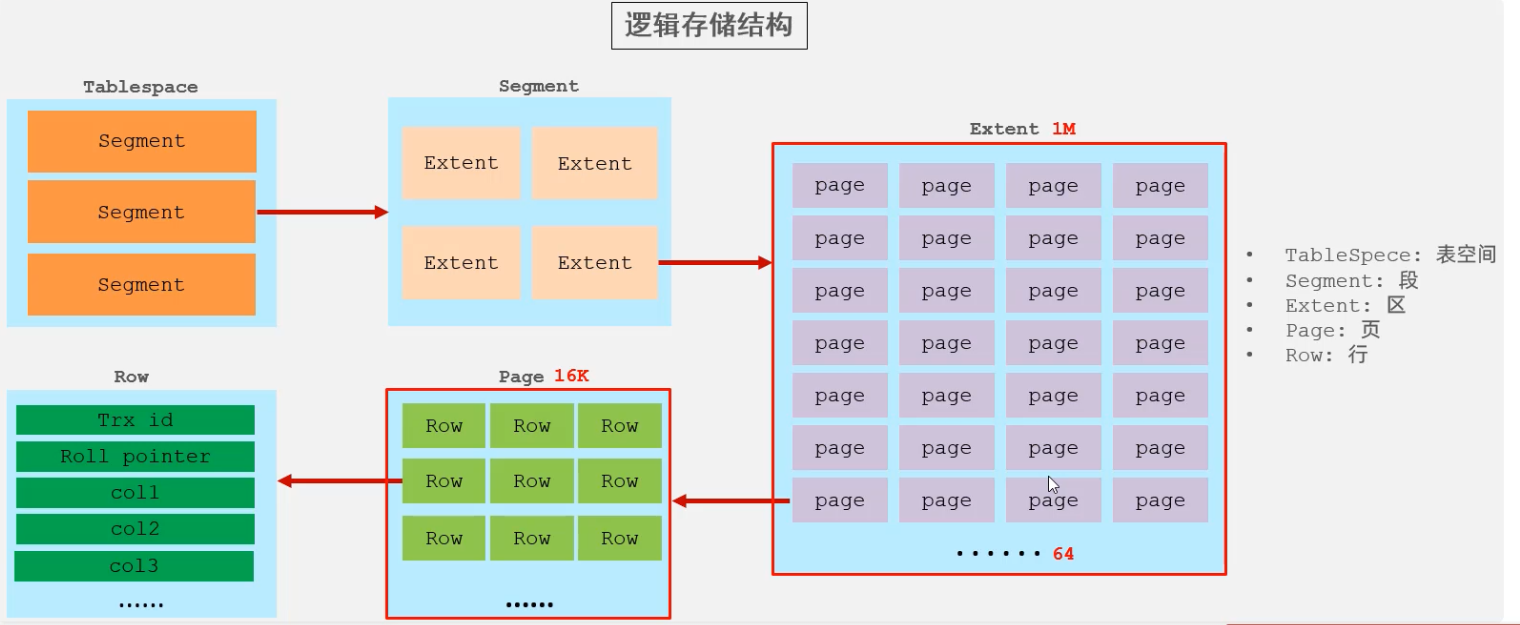
> InnoDB 引擎

> 逻辑结构
02.索引

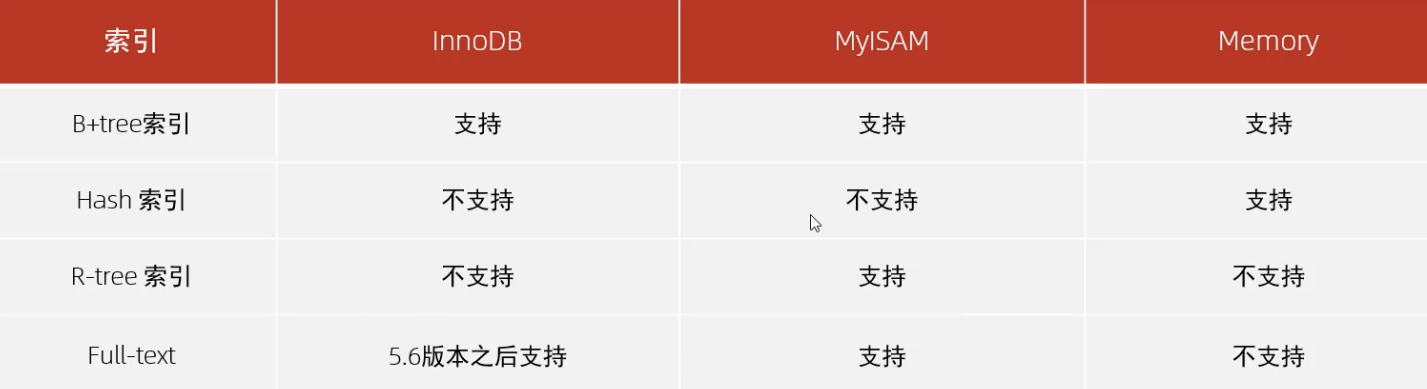
> 索引结构

>> 二叉树缺点:
顺序插入时,会形成一个链表,查询性能大大降低。大数据量情况下,层级较深,检索速度慢;
>> 红黑树: 大数据量情况下,层级较深,检索速度慢;
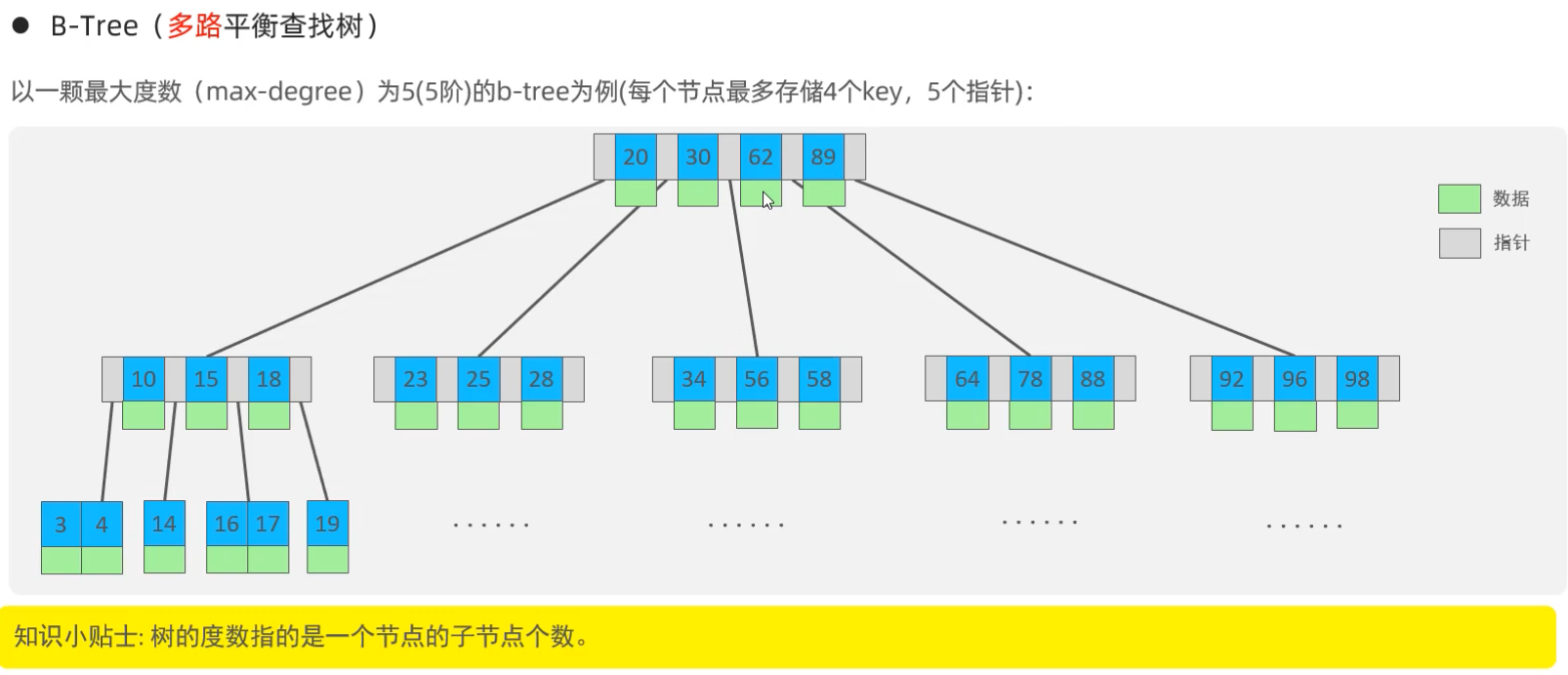
>> 多路平衡查找树
>> 数据结构可视化网站:http://www.rmboot.com/
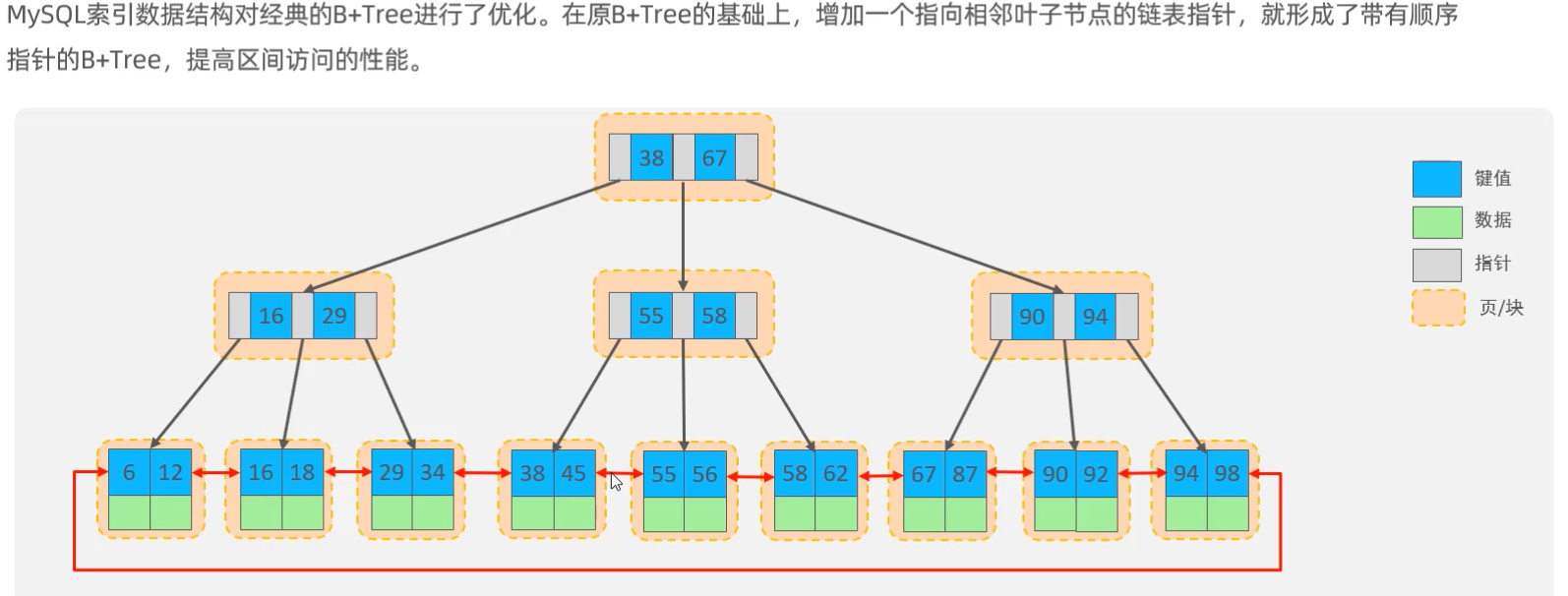
>> B+ Tree
* 所有数据都会出现在叶子节点上;
* 叶子节点形成一个单向链表;
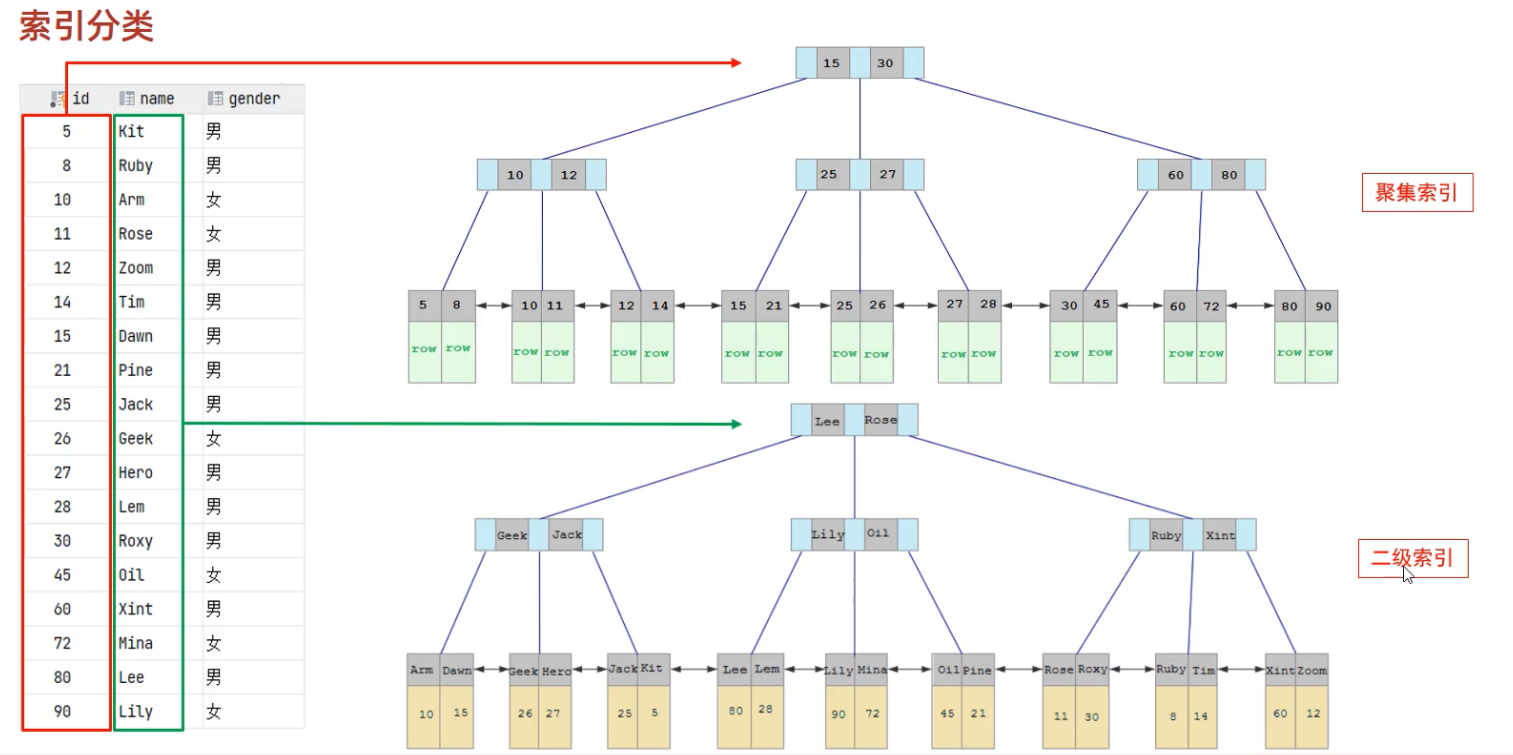
> 索引分类


> 聚集索引选取规则
a. 如果存在主键,主键索引就是聚集索引;
b. 如果不存在主键,将使用第一个唯一(unique)索引作为聚集索引;
c. 如果表没有主键,也没有配置唯一索引,系统将自动构建一个 rowid 做为隐藏的聚集索引;
> 聚集索引与二级索引存储内容的区别
> 创建索引:create [ unique | fulltext ] index 索引名称 on 表名 (字段1,....)
> 查看索引:show index from 表名;
> 删除索引: drop index 索引名 on 表名;
03. SQL执行频率
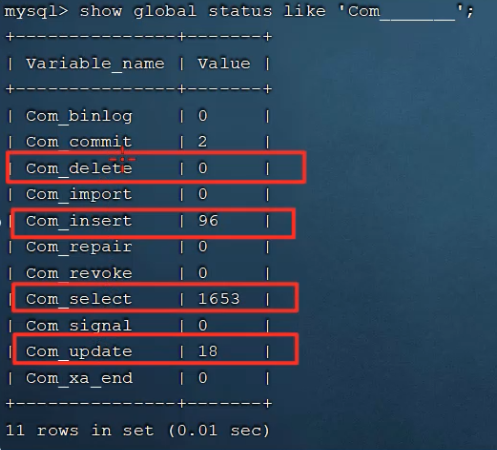
mysql连接成功后,可以通过 show [session | global ] status 命令,获取服务器状态;
通过命令可以获取当前数据库的 insert , update , delete , seelct 的访问频次;
>> 慢查询日志
慢查询日志,记录了所有执行时间超过指定参数(long_query_time, 单位:秒,默认10秒)的所有SQL语句的日志;
mysql的慢查询日志默认没有开启,需要在mysql的配置文件 (/etc/my.cnf)夹中配置:
> 查询数据库的慢查询状态: show variables like 'slow_query_log';
> 开启方式

日志位置: /var/lib/mysql/localhost-slow.log
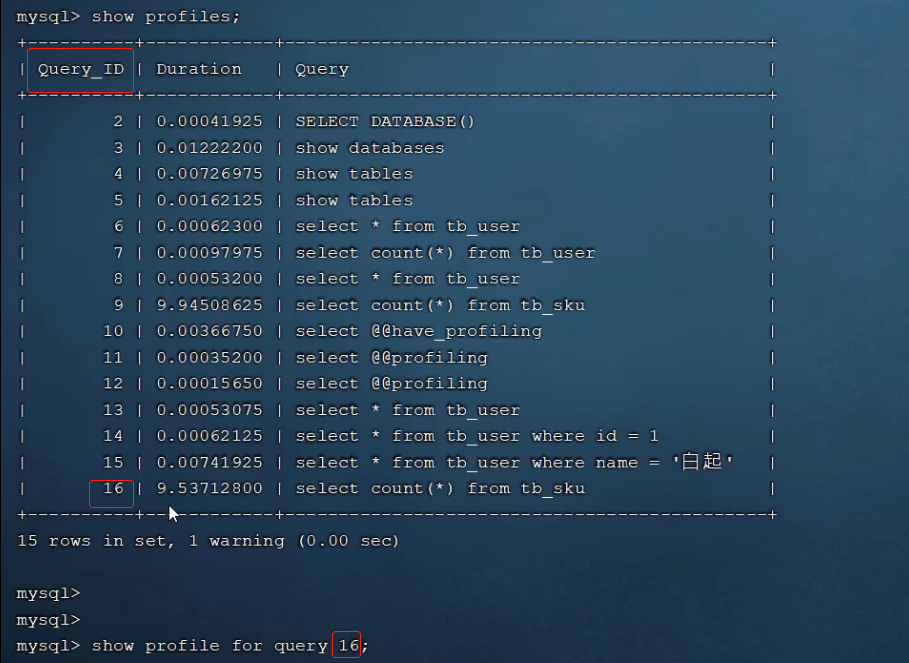
>> profile 详情
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了,
通过 have_profiling 参数,能够看到当前mysql是否支持 profile 操作;
> select @@have_profiling
> 默认 profiling 是关闭的;通过 set 语句 在 session/global 级别开启 profiling;
set profiling =1;
> 在开启 profiling 参数后,通过 show profiles 查看每一条SQL的耗时情况;

>> explain执行计划
explain 或者 des 命令获取 mysql 如何执行 select 语句的信息,包括在 select 语句执行过程中表如何连接和连接的顺序;
语法:



04.索引的使用
>> 最左前缀法则: 如果索引了多列(联合索引),要遵守最左前缀法则;指的是查询从索引的最左列开始,并且不跳过索引中的列;
如果跳开了某一列,索引将部分失败 (后面的字段索引失效);
(与查询条件中,索引列放的位置是没关系的, 只要条件中存在索引相应的字段,即可)
>> 范围查询: 联合索引中,出现范围查询 (>, < 等范围判断),范围查询右侧的列索引失效;
>> 索引列运算:不要在索引列上做运算,否则索引失败;
>>字符串不加引用:字符串类型字段使用时,不加引号;索引将失效;
>>模糊查询: 如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊匹配,索引失效;
>> or 连接条件:用 or 分开的条件,如果 or 前的条件中的列有索引,而后面的列没有索引,那么涉及到的索引都不会被用到;
>> 数据分布影响:如果 mysql 评估使用索引比全表更慢,则不会使用索引;
>> SQL提示,当列参与多个索引时,mysql会自动分析使用某个索引,在sql语句中,可以加入一些人为的提示来达到SQL语句的优化;

>> 覆盖索引: 尽量使用覆盖索引 (查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到), 减少 select * 的使用;
>> 前缀索引:为字段的前N个字节做索引
create index idx_xxx on table_name(column(字节数));

05.索引的设计原则

06.视图
07.存储过程
> Create Procedure 存储过程名称([参数列表])
begin
SQL语句;
end;
> 调用: Call 存储过程名称([参数])
> 查看
a. select * from Information_schema.routines where routine_schema='xxx'
b. show create procedure 存储过程名称
> 删除
drop procedure [if exists] 存储过程名称
> 关于命令行中对存储过程的创建处理
默认情况下,命令行中是识别 ; 做为结束符,这样无法完整的执行存储过程语句;
可以通过 delimiter 来自定义结束符,如: delimiter $$, 只有检测到 $$ 时才认为是结束符;
> 系统变量
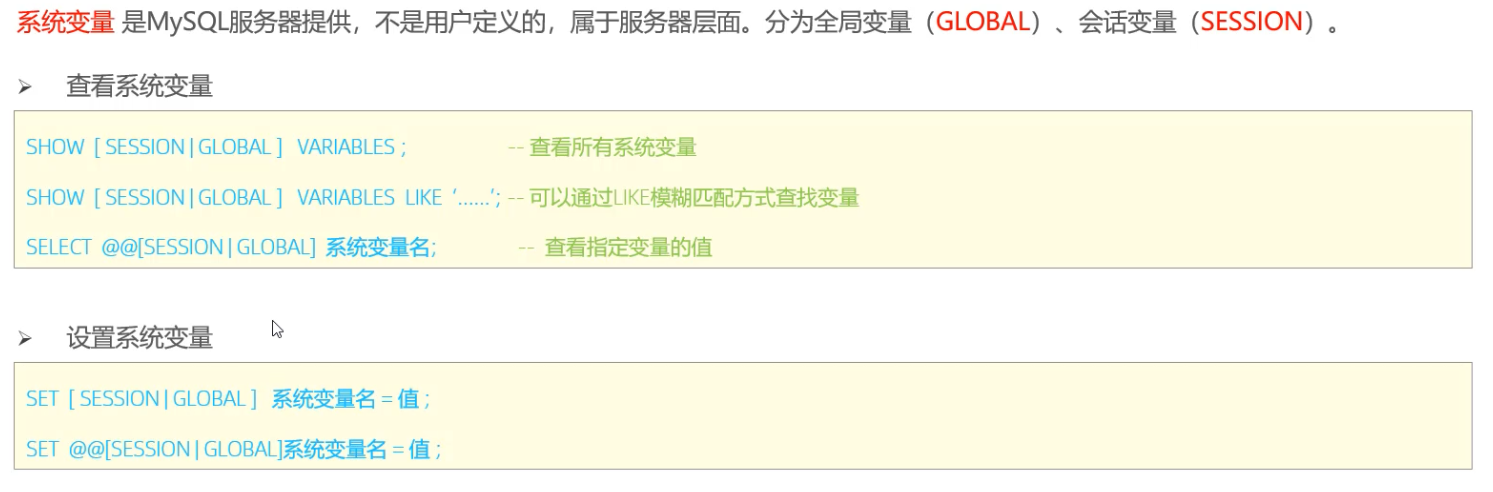
如果没有指定 Session / Global ,默认是 Session;
mysql 服务器重启之后,所设置的全局参数会失效;若想不失效,可以在 /etc/my.conf 中进行配置;
> 自定义变量
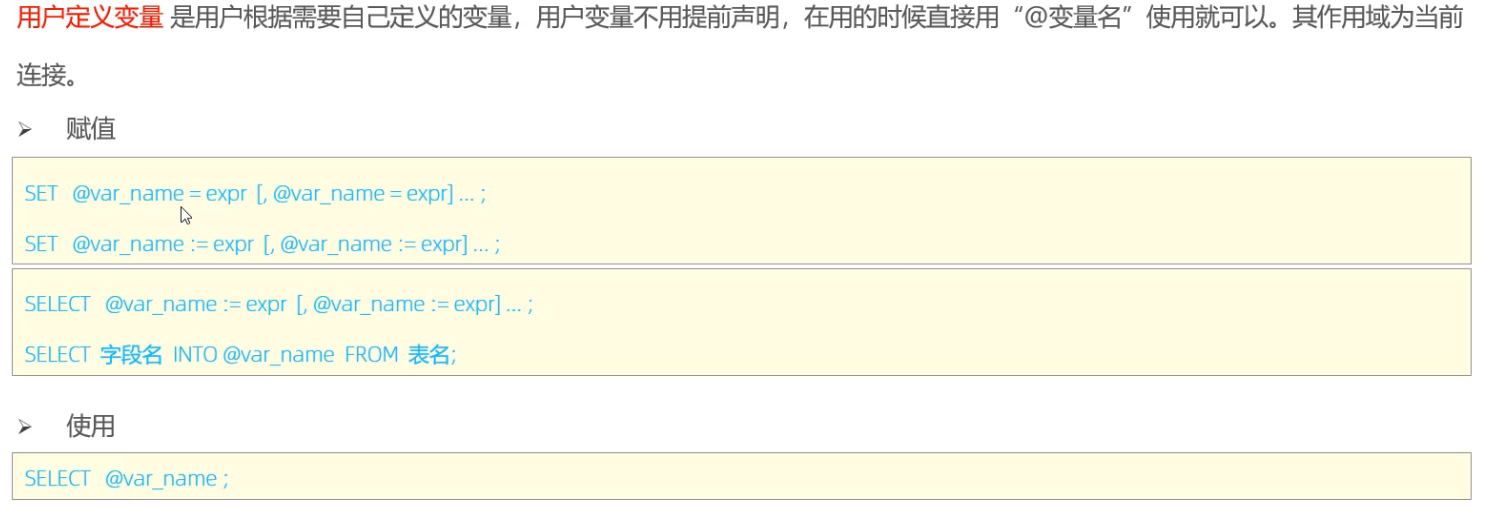
自定义变量无需进行声明和初始话,若直接调用,取值为 null 而已;
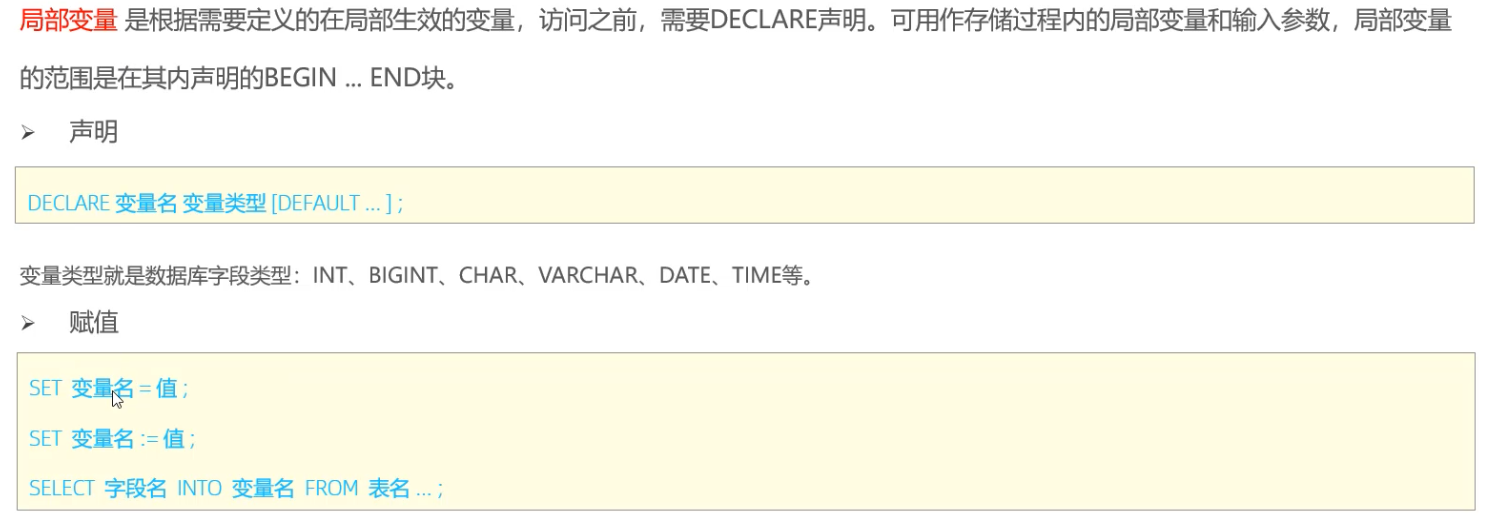
> 局部变量
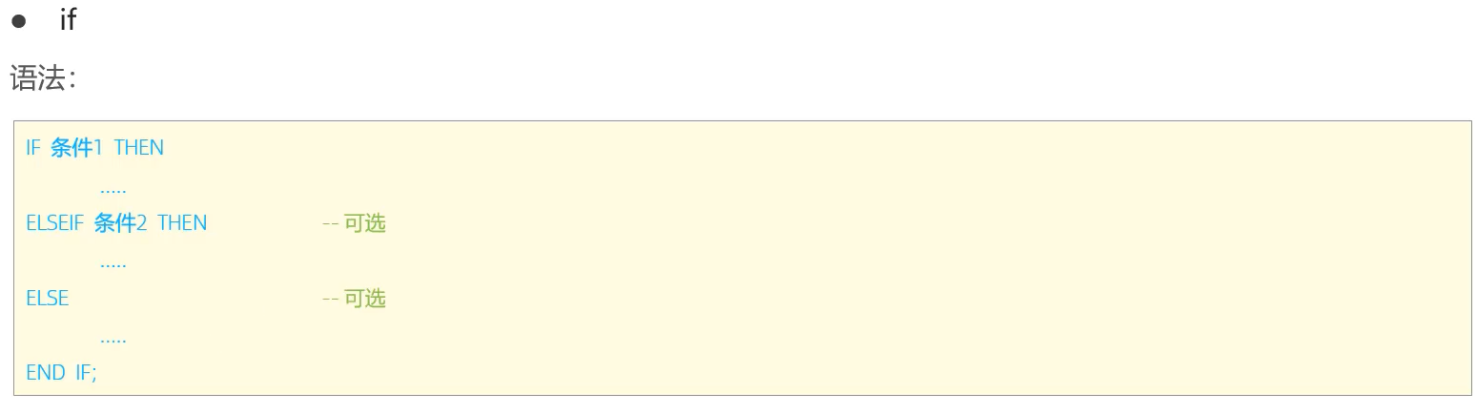
> if 语法
> 参数


> Case

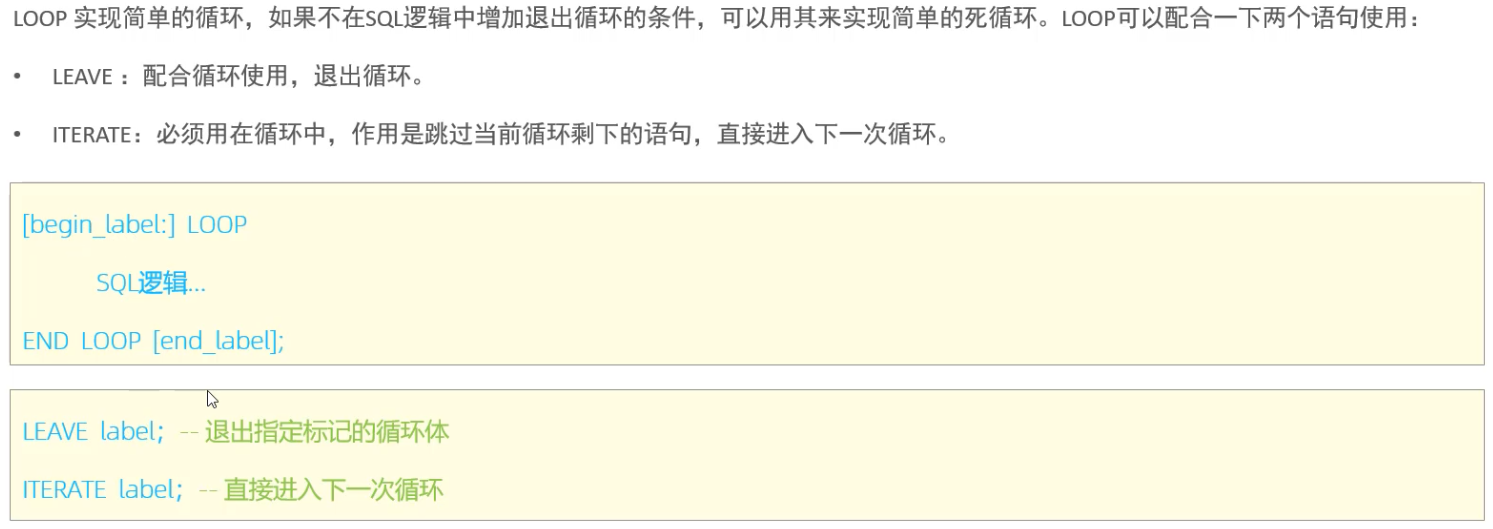
> 循环



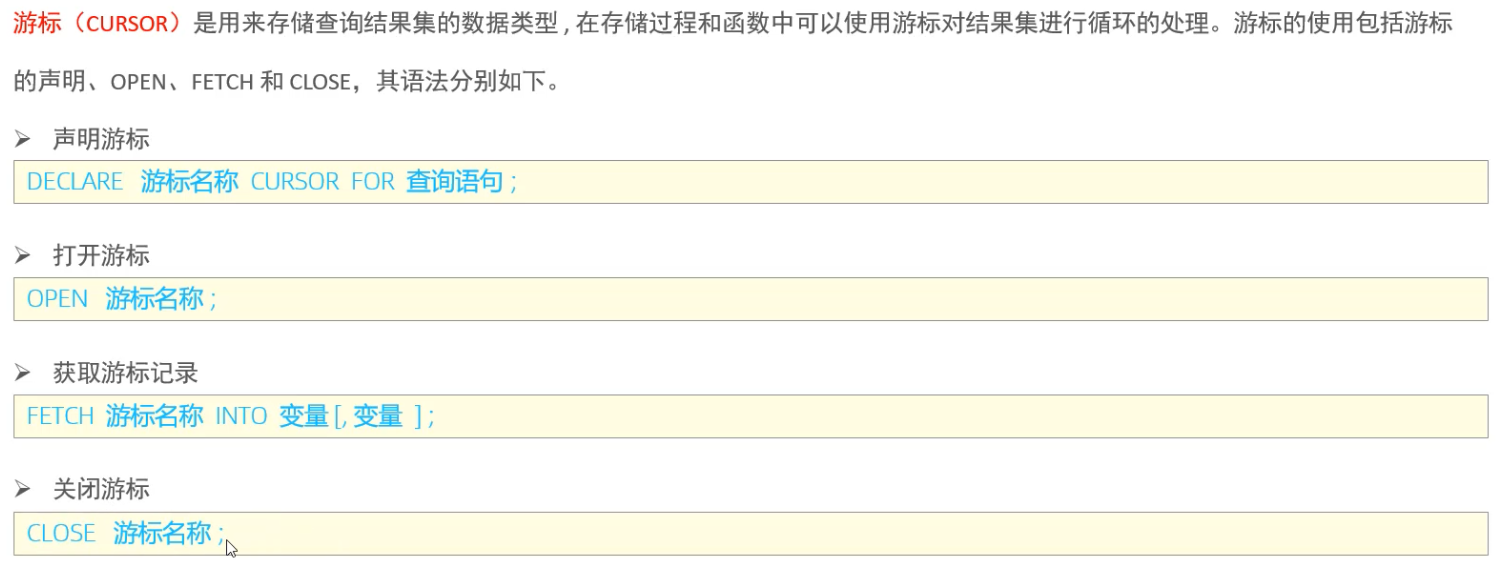
> 游标
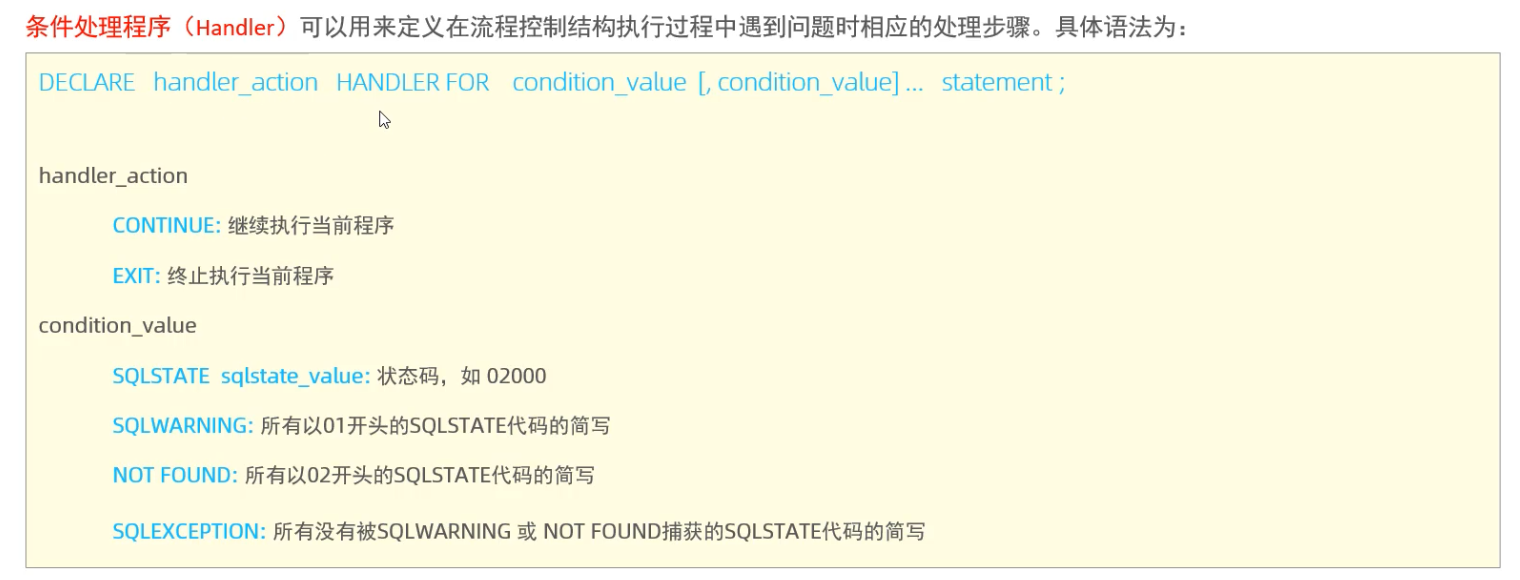
> 条件处理
> 存储函数

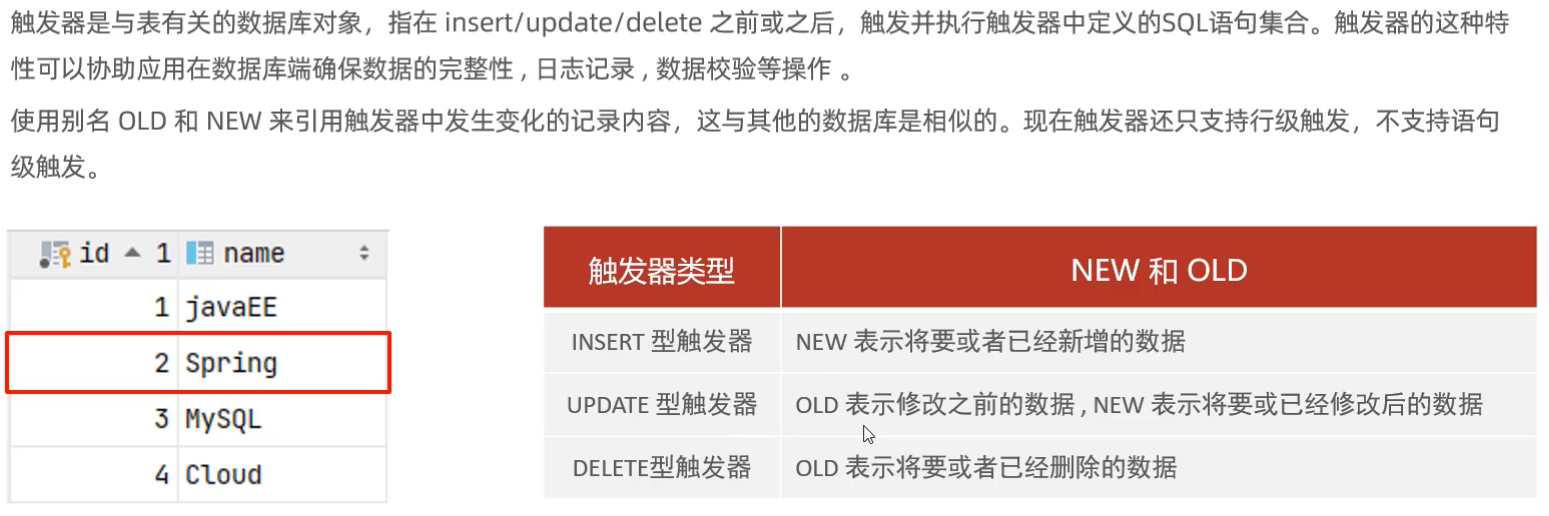
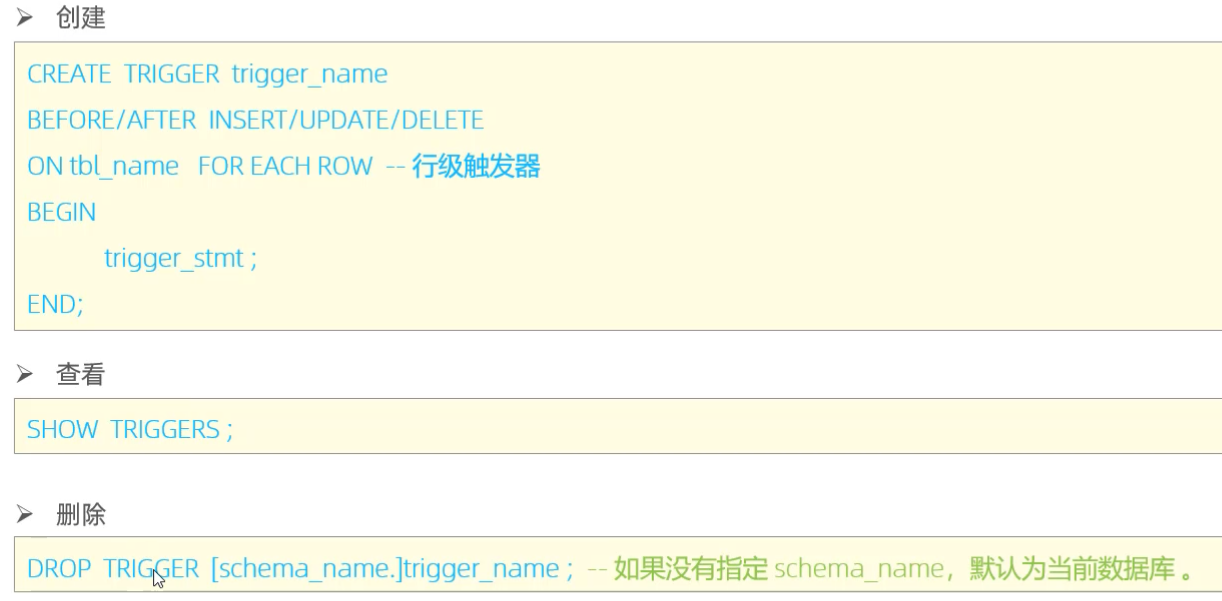
> 触发器
08. 锁
> 全局锁

>> 设置全局锁 : flush tables with read lock;
>> 数据库备份: mysqldump -u账号 -p密码 数据库名 > 存储文件
>> 解锁 : unlock tables;
>> 全局锁的特点


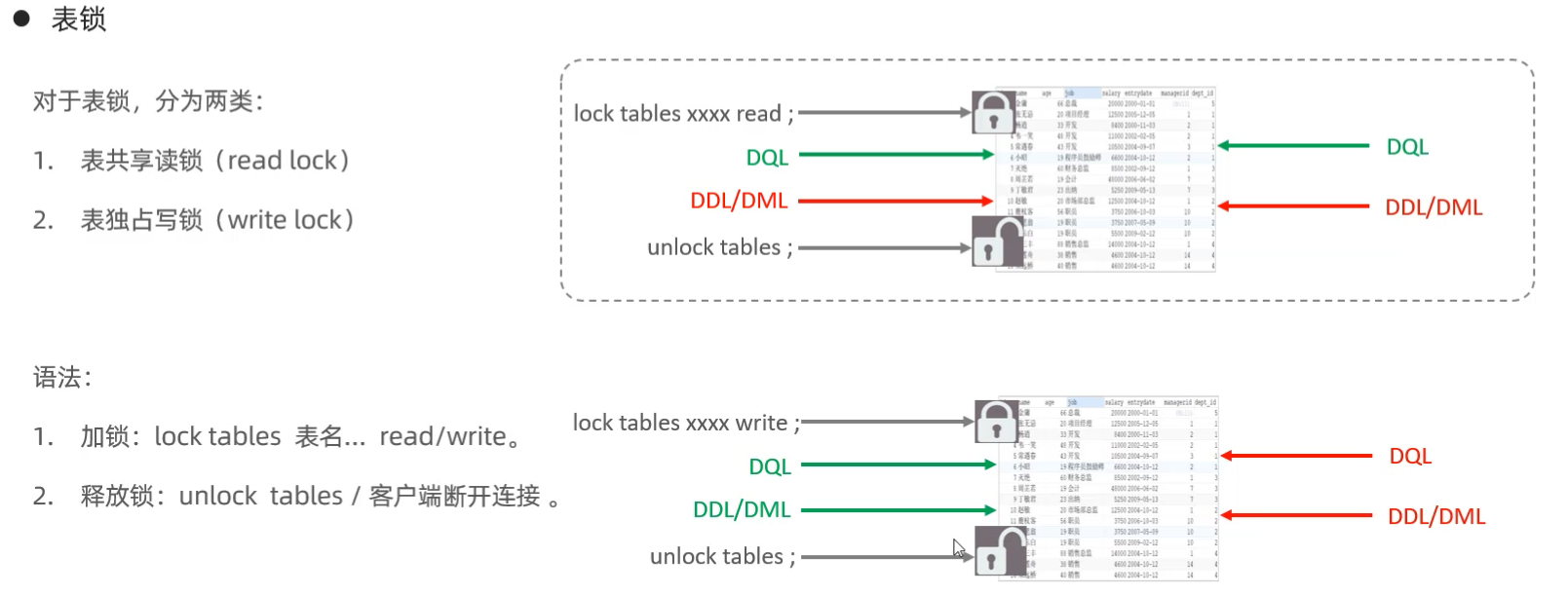
>> 表级锁
![]()
表级锁分为:表锁,元数据锁(MDL),意向锁;
元数据锁:

意向锁
意向共享锁(IS):由语句 select .. lock in share model 添加;
> 与表锁共享锁(read)兼容,与表锁排他锁(write)互斥;
意向排他锁(IX) : 由 insert , update, delete, select ... for update 添加;
>与表锁共享锁(read)及排它锁(write)都互斥,意向锁之间不会互斥;
** 通过如下SQL查看意向锁及行锁的加锁情况
> select object)schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
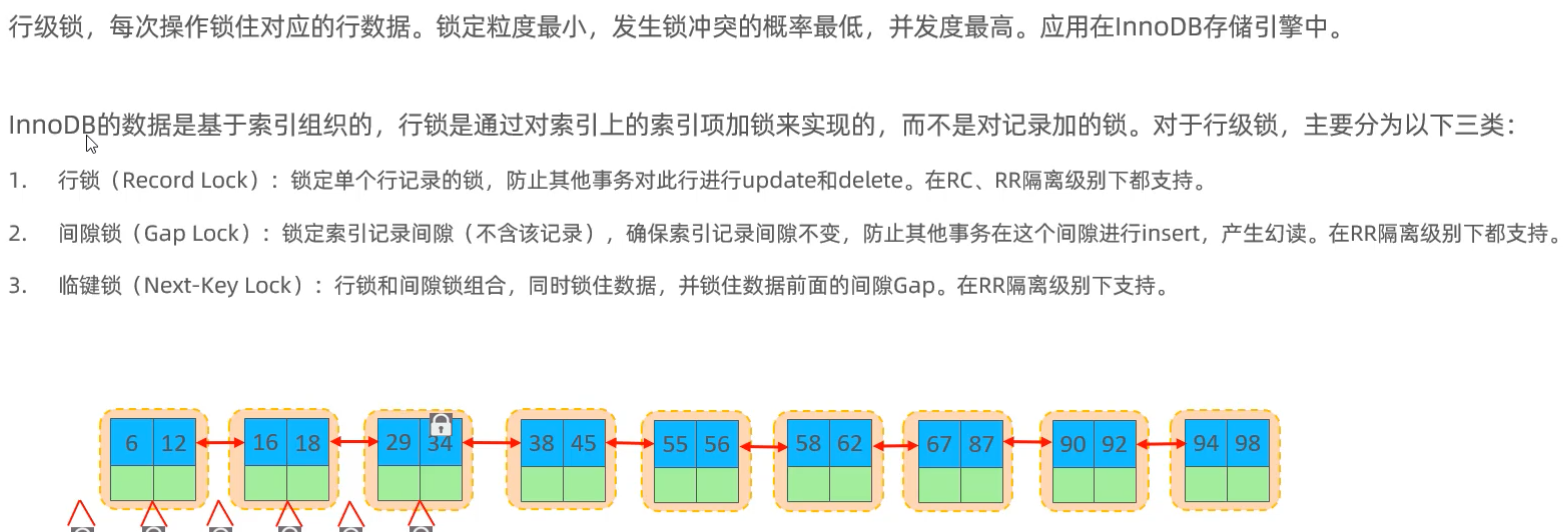
>>行级锁



 浙公网安备 33010602011771号
浙公网安备 33010602011771号