决策树实践
官方文档:http://scikit-learn.org/stable/modules/tree.html
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
一、DecisionTreeClassifier

重要参数说明:其他自己去看文档。。
1、criterion:选择的分类度量方式,默认是gini系数,可选择的有:entropy(代表的是信息增益),一般默认就选择基尼系数就可以了
2、max_depth:决策树最大深度 用来防止过拟合
3、min_samples_split:最小的划分样本数,也就是如果样本数小于这个值就不划分了 用来防止过拟合
4、min_samples_leaf:最小划分的叶子节点样本数,如果样本数小于这个,就不划分了 用来防止过拟合
5、max_leaf_nodes:最多的叶子节点数:用来防止过拟合
二、DecisionTreeRegressor
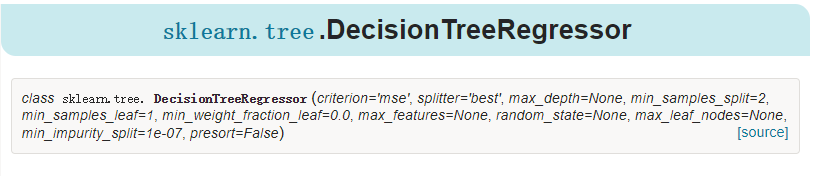
重要参数说明:其他自己去看文档。。
1、criterion:划分的标准:均方误差,另一个是mae,基本不用
2、其他基本与分类树一致
三、可视化

http://www.graphviz.org/
四、实战
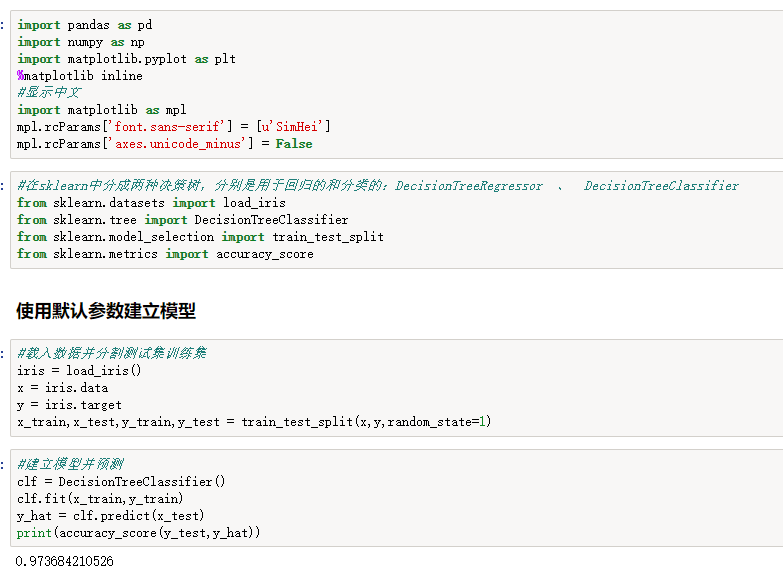
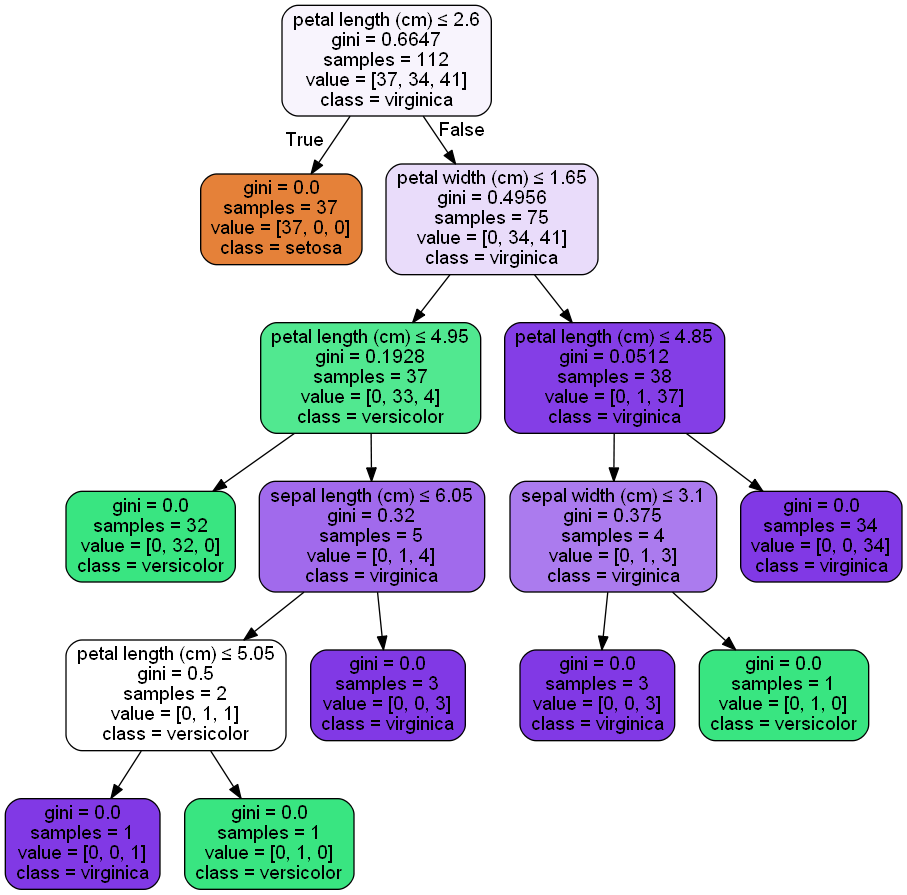
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline #显示中文 import matplotlib as mpl mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False #在sklearn中分成两种决策树,分别是用于回归的和分类的:DecisionTreeRegressor 、 DecisionTreeClassifier from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #载入数据并分割测试集训练集 iris = load_iris() x = iris.data y = iris.target x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=1) #建立模型并预测 clf = DecisionTreeClassifier() clf.fit(x_train,y_train) y_hat = clf.predict(x_test) print(accuracy_score(y_test,y_hat)) import os os.environ["PATH"] += os.pathsep + 'C:\software\Bin' from IPython.display import Image import pydotplus dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号