
线性回归实践
官方文档:http://scikit-learn.org/stable/modules/linear_model.html
一、线性回归实践
1、导入相关库,并查看数据情况

2、对于预测的变量,查看分布情况

3、对于几个特征,查看与因变量的关系


结论:三个特征,前两个与销量呈现明显的线性关系,第三个关系比较弱
4、建立模型,做预测
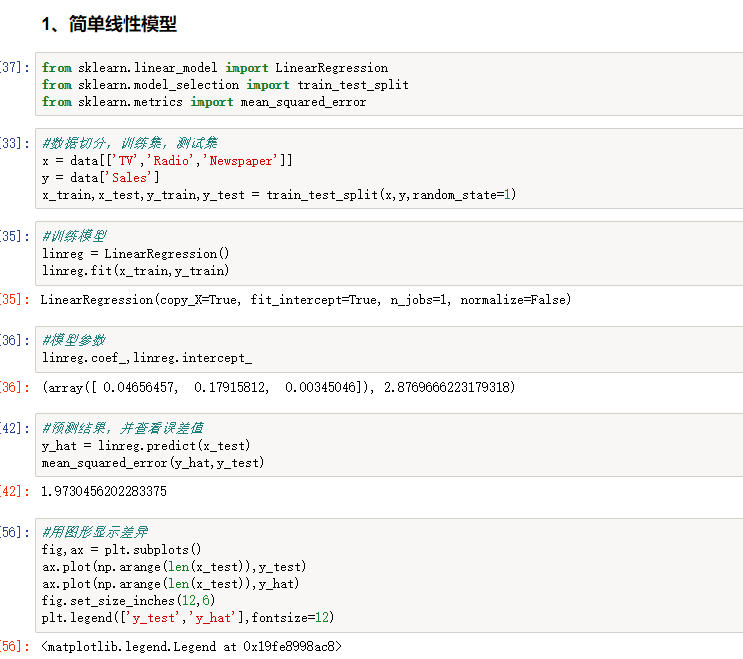


以下是所有的代码,这样比较好复制出来
#导入库 import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline #显示中文 import matplotlib as mpl mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False #读取数据 data = pd.read_csv('8.Advertising.csv',index_col=0) data.head() fig,ax = plt.subplots() ax.hist(data['Sales']) fig.set_size_inches(10,6) plt.title('销量分布直方图',size=20) fig,ax = plt.subplots(3,1) fig.set_size_inches(8,14) ax[0].scatter(data['TV'],data['Sales']) ax[0].set_xlabel('TV&Sales',size=16) ax[1].scatter(data['Radio'],data['Sales'],color='r') ax[1].set_xlabel('Radio&Sales',size=16) ax[2].scatter(data['Newspaper'],data['Sales'],color='y') ax[2].set_xlabel('Newspaper&Sales',size=16) from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error #数据切分,训练集,测试集 x = data[['TV','Radio','Newspaper']] y = data['Sales'] x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=1) #训练模型 linreg = LinearRegression() linreg.fit(x_train,y_train) #模型参数 linreg.coef_,linreg.intercept_ #预测结果,并查看误差值 y_hat = linreg.predict(x_test) mean_squared_error(y_hat,y_test) #用图形显示差异 fig,ax = plt.subplots() ax.plot(np.arange(len(x_test)),y_test) ax.plot(np.arange(len(x_test)),y_hat) fig.set_size_inches(12,6) plt.legend(['y_test','y_hat'],fontsize=12) from sklearn.linear_model import Ridge from sklearn.linear_model import Lasso from sklearn.model_selection import GridSearchCV #lasso 回归 lasso = Lasso() lasso_model = GridSearchCV(lasso,param_grid=({'alpha':[1,2,3,4,5]}),cv=10) #使用网格搜索确定lass回归的参数alpha,10折交叉验证 lasso_model.fit(x_train,y_train) lasso_model.best_params_ #输出最佳参数 #预测测试集,并输出误差 y_hat_lasso = lasso_model.predict(x_test) print(mean_squared_error(y_test,y_hat_lasso)) #ridge回归 ridge = Ridge() ridge_model = GridSearchCV(ridge,param_grid=({'alpha':np.linspace(0,5,10)}),cv=10) #从0到5等差数列一共十个数,等比数列np.logspace ridge_model.fit(x_train,y_train) print(ridge_model.best_params_) #预测测试集,并输出误差 y_hat_ridge = ridge_model.predict(x_test) print(mean_squared_error(y_test,y_hat_ridge))
二、Logistic回归实践
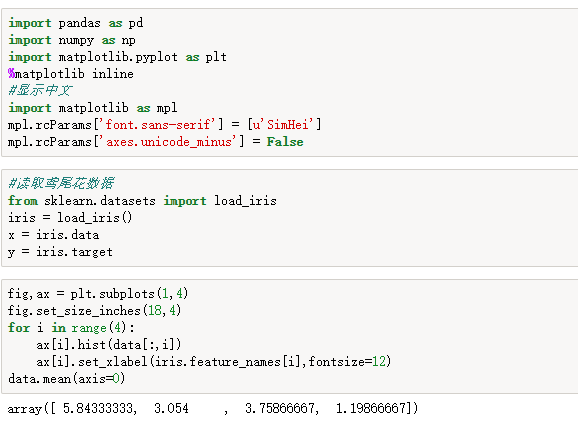

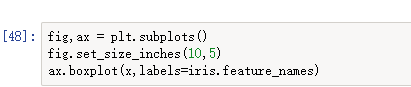
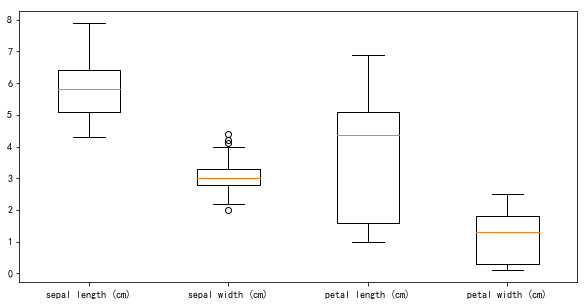

import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline #显示中文 import matplotlib as mpl mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False #读取鸢尾花数据 from sklearn.datasets import load_iris iris = load_iris() x = iris.data y = iris.target fig,ax = plt.subplots(1,4) fig.set_size_inches(18,4) for i in range(4): ax[i].hist(data[:,i]) ax[i].set_xlabel(iris.feature_names[i],fontsize=12) data.mean(axis=0) fig,ax = plt.subplots() fig.set_size_inches(10,5) ax.boxplot(x,labels=iris.feature_names) #建立模型 from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #切分数据,并训练模型 x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=1) lr = LogisticRegression() lr.fit(x_train,y_train) #预测数据,输出准确率 y_hat = lr.predict(x_test) print(accuracy_score(y_hat,y_test))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号