模型层总结
ORM简介
查询数据层次图解:如果操作mysql,ORM是在pymysq之上又进行了一层封装
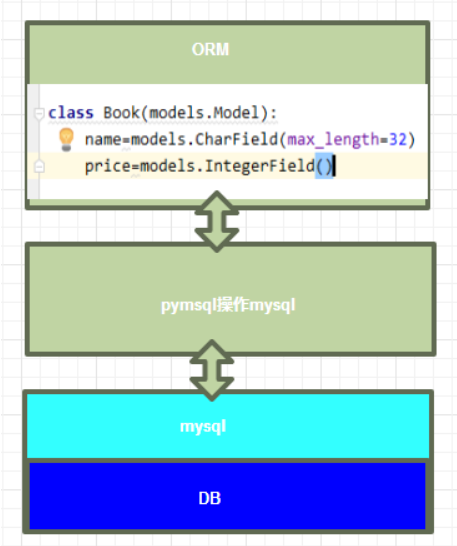
- MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。
#sql中的表
#创建表:
CREATE TABLE employee(
id INT PRIMARY KEY auto_increment ,
name VARCHAR (20),
gender BIT default 1,
birthday DATA ,
department VARCHAR (20),
salary DECIMAL (8,2) unsigned,
);
#sql中的表纪录
#添加一条表纪录:
INSERT employee (name,gender,birthday,salary,department)
VALUES ("alex",1,"1985-12-12",8000,"保洁部");
#查询一条表纪录:
SELECT * FROM employee WHERE age=24;
#更新一条表纪录:
UPDATE employee SET birthday="1989-10-24" WHERE id=1;
#删除一条表纪录:
DELETE FROM employee WHERE name="alex"
#python的类
class Employee(models.Model):
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
gender=models.BooleanField()
birthday=models.DateField()
department=models.CharField(max_length=32)
salary=models.DecimalField(max_digits=8,decimal_places=2)
#python的类对象
#添加一条表纪录:
emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部")
emp.save()
#查询一条表纪录:
Employee.objects.filter(age=24)
#更新一条表纪录:
Employee.objects.filter(id=1).update(birthday="1989-10-24")
#删除一条表纪录:
Employee.objects.filter(name="alex").delete()
一些说明:
- 表myapp_person的名称是自动生成的,如果你要自定义表名,需要在model的Meta类中指定 db_table 参数,强烈建议使用小写表名,特别是使用MySQL作为后端数据库时。
- id字段是自动添加的,如果你想要指定自定义主键,只需在其中一个字段中指定 primary_key=True 即可。如果Django发现你已经明确地设置了Field.primary_key,它将不会添加自动ID列。
- 本示例中的CREATE TABLE SQL使用PostgreSQL语法进行格式化,但值得注意的是,Django会根据配置文件中指定的数据库后端类型来生成相应的SQL语句。
- Django支持MySQL5.5及更高版本。
ORM常用字段
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存,)
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
这里需要知道的是Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,但是Django允许我们自定义新的字段,下面我来自定义对应于数据库的char类型

DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
ORM字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置索引。
default
为该字段设置默认值。
DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
关系字段
ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
db_constraint
是否在数据库中创建外键约束,默认为True。
其余字段参数
models.DO_NOTHING
删除关联数据,引发错误IntegrityError
models.PROTECT
删除关联数据,引发错误ProtectedError
models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。(参考上面的例子)
ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
symmetrical
仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
举个例子:
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self")
此时,person对象就没有person_set属性。
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self", symmetrical=False)
此时,person对象现在就可以使用person_set属性进行反向查询。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
through_fields
设置关联的字段。
db_table
默认创建第三张表时,数据库中表的名称。
多对多关联关系的三种方式
方式一:自行创建第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
# 自己创建第三张表,分别通过外键关联书和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
方式二:通过ManyToManyField自动创建第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 通过ORM自带的ManyToManyField自动创建第三张表
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", related_name="authors")
方式三:设置ManyTomanyField并指定自行创建的第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book"))
# through_fields接受一个2元组('field1','field2'):
# 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
注意:
当我们需要在第三张关系表中存储额外的字段时,就要使用第三种方式。
但是当我们使用第三种方式创建多对多关联关系时,就无法使用set、add、remove、clear方法来管理多对多的关系了,需要通过第三张表的model来管理多对多关系。
元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
db_table
ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
index_together
联合索引。
unique_together
联合唯一索引。
ordering
指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()。
class UserInfo(models.Model):
nid = models.AutoField(primary_key=True)
username = models.CharField(max_length=32)
class Meta:
# 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "table_name"
# 联合索引
index_together = [
("pub_date", "deadline"),
]
# 联合唯一索引
unique_together = (("driver", "restaurant"),)
ordering = ('name',)
# admin中显示的表名称
verbose_name='哈哈'
# verbose_name加s
verbose_name_plural=verbose_name
自定义字段(了解)
自定义字段在实际项目应用中可能会经常用到,这里需要对他留个印象!
自定义char类型字段:
from django.db import models
# Create your models here.
#Django中没有对应的char类型字段,但是我们可以自己创建
class FixCharField(models.Field):
'''
自定义的char类型的字段类
'''
def __init__(self,max_length,*args,**kwargs):
self.max_length=max_length
super().__init__(max_length=max_length,*args,**kwargs)
def db_type(self, connection):
'''
限定生成的数据库表字段类型char,长度为max_length指定的值
:param connection:
:return:
'''
return 'char(%s)'%self.max_length
#应用上面自定义的char类型
class Class(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
class_name=FixCharField(max_length=16)
gender_choice=((1,'男'),(2,'女'),(3,'保密'))
gender=models.SmallIntegerField(choices=gender_choice,default=3)
字段合集(争取记忆)
AutoField(Field)
- int自增列,必须填入参数 primary_key=True
BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True
注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models
class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32)
class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647
BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
BooleanField(Field)
- 布尔值类型
NullBooleanField(Field):
- 可以为空的布尔值
CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度
TextField(Field)
- 文本类型
EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制
IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both"
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL
SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字
UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证
FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]]
DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型
FloatField(Field)
- 浮点型
DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度
BinaryField(Field)
- 二进制类型
orm字段与MySQL字段对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
(1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
(5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
聚合查询与分组查询
聚合
aggregate(*args, **kwargs)
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。用到的内置函数:
from django.db.models import Avg, Sum, Max, Min, Count
示例:
res = models.Book.objects.all().aggregate(Avg('price'))#平均值
res1 = models.Book.objects.all().aggregate(Max('price'))#最大值
res2 = models.Book.objects.all().aggregate(Min('price'))#最小值
res3 = models.Book.objects.all().aggregate(Sum('price'))#求和
res4 = models.Book.objects.all().aggregate(Count('title'))#求总数,个数
根据最大值求其他的字段
res = models.Book.objects.all().aggregate(Max('price'))
print(res,type(res))
print(res.get('price__max'),type(res.get('price__max')))
res = models.Book.objects.filter(price=res.get('price__max'))
print(res.first().title)
如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
res = models.Book.objects.all().aggregate(Min('price'),Max('price'),Count('price'),sum=Sum('price'),ave=Avg('price'))
#给定名称的结果先输出
{'sum': Decimal('810.44'), 'ave': 162.088, 'price__min': Decimal('10.22'), 'price__max': Decimal('250.00'), 'price__count': 5}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
res5 = models.Book.objects.all().aggregate(Avg('price'),Max('price'),Min('price'),Sum('price'),Count('title'))
分组
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。可以跨表查询,使用双下划线方法。
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。 分组循环涉及到安全问题,因此有些查询需要设置非安全模式。
我这里是将mysql中的mode,注释就行了。
#sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
查询练习
练习1:统计每一本书作者个数
from django.db.models import Avg, Max, Sum, Min, Max, Count
res=models.Book.objects.annotate(author_num=Count('author')).values('author_num')
res1=models.Book.objects.all().annotate(author_num=Count('author')).values('author_num')
print(res)
print(res1)
###################################################################
< QuerySet[{'author_num': 3}, {'author_num': 1}, {'author_num': 0},{'author_num': 0}, {'author_num': 0}] >
< QuerySet[{'author_num': 3}, {'author_num': 1}, {'author_num': 0}, {'author_num': 0}, {'author_num': 0}] >
################################################################
book_list = models.Book.objects.all().annotate(author_num = Count('author'))
print(book_list)
for book_obj in book_list:
print(book_obj.title)
################################################################
<QuerySet [<Book: linux>, <Book: math>, <Book: python>, <Book: english>, <Book: english>]>
linux
math
python
english
english
################################################################
book_list=models.Book.objects.all().annotate(author_num=Count('author')).values('title','author_num')
print(book_list)
################################################################
<QuerySet [{'title': 'linux', 'author_num': 3}, {'title': 'math', 'author_num': 1}, {'title': 'python', 'author_num': 0}, {'title': 'english', 'author_num': 0}, {'title': 'english', 'author_num': 0}]>
练习2:统计每一个出版社的最便宜的书的价格,
publish=models.Publish.objects.all().annotate(book_price=Min('book__price')).values("name",'book_price')
print(publish)
################################################################
<QuerySet [{'name': '北极出版社', 'book_price': Decimal('10.22')}, {'name': '南极出版社', 'book_price': Decimal('100.22')}]>
################################################################
book_min = models.Book.objects.values('publish__name').annotate(book_min = Min('price'))
print(book_min)
################################################################
<QuerySet [{'publish__name': '北极出版社', 'book_min': Decimal('10.22')}, {'publish__name': '南极出版社', 'book_min': Decimal('100.22')}]>
annotate的返回值是querySet,如果不想遍历对象,可以用上valuelist:返回列表套元组
book_min=models.Publish.objects.all().annotate(book_price=Min('book__price')).values_list("name",'book_price')
print(book_min)
################################################################
<QuerySet [('北极出版社', Decimal('10.22')), ('南极出版社', Decimal('100.22'))]>
练习3:统计不止一个作者的图书:(作者数量大于一)
- 统计每本书对应的作者个数
- 基于上面的结果 筛选出作者个数大于1 的
res = models.Book.objects.all().annotate(author_count = Count('author')).filter(author_count__gt=1).values('title','author_count')
print(res)
################################################################
<QuerySet [{'title': 'linux', 'author_count': 3}]>
练习4:统计每一本以py开头的书籍的作者个数:
book_queryresult = models.Book.objects.filter(title__startswith='m').annotate(author_count=Count('author')).values('title','author__name','author_count')
print(book_queryresult)
################################################################
<QuerySet [{'title': 'math', 'author__name': 'sky', 'author_count': 2}]>
练习5:根据一本图书作者数量的多少对查询集 QuerySet进行排序:
res = models.Book.objects.all().annotate(author_count = Count('author')).order_by('author_count').values('title','author_count')
print(res)
################################################################
<QuerySet [{'title': 'english', 'author_count': 0}, {'title': 'english', 'author_count': 0}, {'title': 'python', 'author_count': 0}, {'title': 'math', 'author_count': 2}, {'title': 'linux', 'author_count': 3}]>
练习6:查询各个作者出的书的总价格:
res = models.Author.objects.all().annotate(book_price = Sum('book__price')).values_list('name','book_price')
print(res)
################################################################
<QuerySet [('ocean', Decimal('10.22')), ('sky', Decimal('110.44')), ('rock', Decimal('110.44')), ('json', None)]>
练习7:查询每个出版社的名称和书籍个数
res = models.Publish.objects.all().annotate(book_count =Count('book')).values('name','book_count')
print(res)
################################################################
<QuerySet [{'name': '北极出版社', 'book_count': 1}, {'name': '南极出版社', 'book_count': 4}]>
总结
value里面的参数对应的是sql语句中的select要查找显示的字段,
filter里面的参数相当于where或者having里面的筛选条件
annotate本身表示group by的作用,前面找寻分组依据,内部放置显示可能用到的聚合运算式,后面跟filter来增加限制条件,最后的value来表示分组后想要查找的字段值

F查询与Q查询
- 我们之前在查询数据库的时候条件都是我们自己手写的
- 但是现在出现了条件是从数据库里面获取的
from django.db.models import F,Q
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
示例1:
查询出卖出数大于库存数的商品
res = models.Book.objects.filter(maichu__gt=F('kucun'))
print(res)
################################################################
<QuerySet [<Book: math>, <Book: english>, <Book: english>]>
F可以帮我们取到表中某个字段对应的值来当作我的筛选条件,而不是我认为自定义常量的条件了,实现了动态比较的效果
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。基于此可以对表中的数值类型进行数学运算
示例2:
将每个商品的价格提高50块
res = models.Book.objects.update(price=F('price')+100)
print(res)
#################################
5
返回更新的数量
引申:
如果要修改char字段咋办(千万不能用上面对数值类型的操作!!!)?
如:把所有书名后面加上'新款',(这个时候需要对字符串进行拼接Concat操作,并且要加上拼接值Value)
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.filter(pk=2).update(title=Concat(F('title'),Value('新款')))
Concat表示进行字符串的拼接操作,参数位置决定了拼接是在头部拼接还是尾部拼接,Value里面是要新增的拼接值
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
示例1:
查询 卖出数大于100 或者 价格小于100块的
from django.db.models import Q
res=models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=100))
print(res)
##############################################
<QuerySet [<Book: math新款>, <Book: python>, <Book: english>]>
对条件包裹一层Q时候,filter即可支持交叉并的比较符
示例2:
查询 库存数是100 并且 卖出数不是0 的产品
res = models.Book.objects.filter(Q(kucun=100)&~Q(maichu=0))
print(res)
#####################
<QuerySet [<Book: linux>]>
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
我们可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。
同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
查询产品名包含新款, 并且库存数大于60的
models.Product.objects.filter(Q(kucun__gt=60), name__contains="新款")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017), title__icontains="python")
Q查询进阶用法
# Q查询进阶用法 用Q产生对象 然后再使用
q = Q()
q.connector='or'
q.children.append(('title__icontains','m'))
q.children.append(('kucun',100))
res = models.Book.objects.filter(q)
print(res)
##################################
<QuerySet [<Book: linux>, <Book: math新款>]>
"""
字符串的左边 跟你的变量名条件书写一模一样
"""
事务
事务的定义:将多个sql语句操作变成原子性操作,要么同时成功,有一个失败则里面回滚到原来的状态,保证数据的完整性和一致性(NoSQL数据库对于事务则是部分支持)
ACID
原子性
一致性
隔离性
持久性
# django中如何开启事务
from django.db import transaction
with transaction.atomic():
# 在该代码块中所写的orm语句 同属于一个事务
# 缩进出来之后自动结束
commit
rollback
要么同时成功要么同时失败
# 事务
# 买一本 跟老男孩学Linux 书
# 在数据库层面要做的事儿
# 1. 创建一条订单数据
# 2. 去产品表 将卖出数+1, 库存数-1
from django.db.models import F
from django.db import transaction
# 开启事务处理
try:
with transaction.atomic():
# 创建一条订单数据
models.Order.objects.create(num="110110111", product_id=1, count=1)
# 能执行成功
models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1)
except Exception as e:
print(e)
其他鲜为人知的操作
Django ORM执行原生SQL
条件假设:就拿博客园举例,我们写的博客并不是按照年月日来分档,而是按照年月来分的,而我们的DateField时间格式是年月日形式,也就是说我们需要对从数据库拿到的时间格式的数据再进行一次处理拿到我们想要的时间格式,这样的需求,Django是没有给我们提供方法的,需要我们自己去写处理语句了
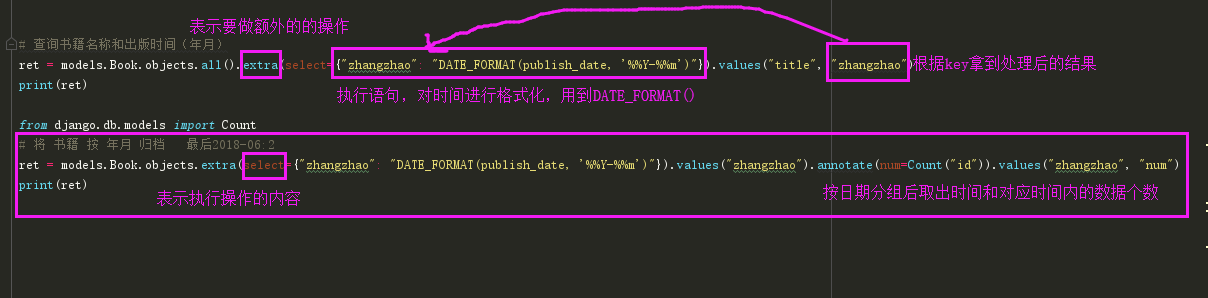
ORM 执行原生SQL的方法
事务
事务的定义:将多个sql语句操作变成原子性操作,要么同时成功,有一个失败则里面回滚到原来的状态,保证数据的完整性和一致性(NoSQL数据库对于事务则是部分支持)
复制代码
# 事务
# 买一本 跟老男孩学Linux 书
# 在数据库层面要做的事儿
# 1. 创建一条订单数据
# 2. 去产品表 将卖出数+1, 库存数-1
from django.db.models import F
from django.db import transaction
# 开启事务处理
try:
with transaction.atomic():
# 创建一条订单数据
models.Order.objects.create(num="110110111", product_id=1, count=1)
# 能执行成功
models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1)
except Exception as e:
print(e)
复制代码
其他鲜为人知的操作
Django ORM执行原生SQL
条件假设:就拿博客园举例,我们写的博客并不是按照年月日来分档,而是按照年月来分的,而我们的DateField时间格式是年月日形式,也就是说我们需要对从数据库拿到的时间格式的数据再进行一次处理拿到我们想要的时间格式,这样的需求,Django是没有给我们提供方法的,需要我们自己去写处理语句了
ORM 执行原生SQL的方法
QuerySet方法大全
几个比较重要的方法:
update()与save()的区别
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,而update()则是针对修改的项进行针对的更新效率高耗时少
所以以后对数据的修改保存用update()
select_related和prefetch_related
复制代码
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
复制代码
bulk_create批量插入数据
要求:一次性插入多条数据
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)]
obj_list = [models.A(name=i) for i in data]
models.A.objects.bulk_create(obj_list)
QuerySet方法大全
几个比较重要的方法:
update()与save()的区别
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,而update()则是针对修改的项进行针对的更新效率高耗时少
所以以后对数据的修改保存用update()
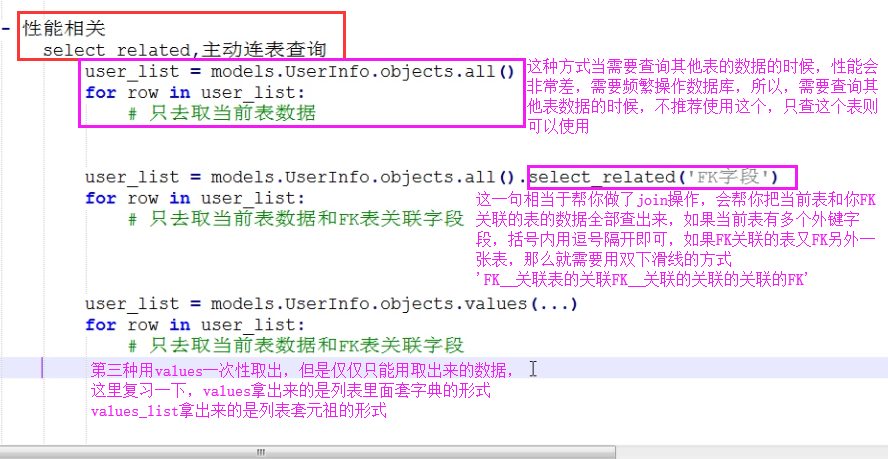
**select_related和prefetch_related
只针对一对多的表格,和一对一的表格,返回的对象区别
- select_related内部自动连表 消耗的资源就在连表上 但是走数据库的次数较少
- prefetch_related 内部不做连表 消耗的资源就在查询次数上 但是给用户的感觉跟连表操作一样,
select_related
res = models.Book.objects.select_related('publish')
print(res)
res1 = models.Book.objects.all()
res2 = models.Author.objects.select_related('author_detail')
for r in res2:
print(r.author_detail)
"""
select_related 会自动帮你做连表操作 然后将连表之后的数据全部查询出来封装给对象
select_related括号内只能放外键字段
并且多对多字段不能放
如果括号内外键字段所关联的表中还有外键字段 还可以继续连表
select_related(外键字段__外键字段__外键字段...)
"""
prefetch_related
res = models.Book.objects.prefetch_related('publish')
# print(res)
for r in res:
print(r.publish.name)
"""
prefetch_related 看似连表操作 其实是类似于子查询
prefetch_related括号内只能放外键字段
并且多对多字段不能放
如果括号内外键字段所关联的表中还有外键字段 还可以继续连表
select_related(外键字段__外键字段__外键字段...)
"""
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
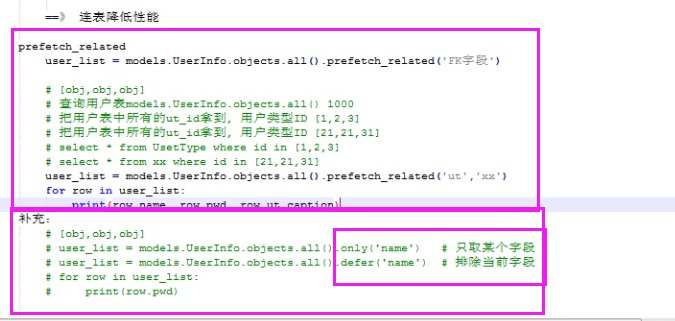
defer和only
only
- only会将括号内的字段对应的值 直接封装到返回给你的对象中 点该字段 不需要再走数据库
- 一旦你点了不是括号内的字段 就会频繁的去走数据库查询
"""
only会将括号内的字段对应的值 直接封装到返回给你的对象中 点该字段 不需要再走数据库
一旦你点了不是括号内的字段 就会频繁的去走数据库查询
"""
res = models.Book.objects.all()
res = models.Book.objects.values('title')
res = models.Book.objects.only('title')
for r in res:
print(r.title)
print(r.price)#查询不在的字段,会再次查询数据库,造成数据库压力大,要不断的重复查找
defer
- defer会将括号内的字段排除之外将其他字段对应的值 直接封装到返回给你的对象中 点该其他字段 不需要再走数据库
- 一旦你点了括号内的字段 就会频繁的去走数据库查询
"""
defer会将括号内的字段排除之外将其他字段对应的值 直接封装到返回给你的对象中 点该其他字段 不需要再走数据库
一旦你点了括号内的字段 就会频繁的去走数据库查询
"""
res = models.Book.objects.defer('title') # defer和only互为反关系
for r in res:
print(r.author_detail)
print(r.title)# 查询在的字段,会再次查询数据库,造成数据库压力大
bulk_create批量插入数据
要求:一次性插入多条数据
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)]
obj_list = [models.A(name=i) for i in data]
models.A.objects.bulk_create(obj_list)

Querset方法大全
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 获取所有的数据对象
def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct进行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
"""
def none(self):
# 空QuerySet对象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 获取个数
def get(self, *args, **kwargs):
# 获取单个对象
def create(self, **kwargs):
# 创建对象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 获取第一个
def last(self):
# 获取最后一个
def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 删除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有结果
QuerySet对象
可切片
使用Python 的切片语法来限制查询集记录的数目 。它等同于SQL 的LIMIT 和OFFSET 子句。
Entry.objects.all()[:5] # (LIMIT 5)
Entry.objects.all()[5:10] # (OFFSET 5 LIMIT 5)
不支持负的索引(例如Entry.objects.all()[-1])。通常,查询集 的切片返回一个新的查询集 —— 它不会执行查询。
可迭代
articleList=models.Article.objects.all()
for article in articleList:
print(article.title)
惰性查询
查询集 是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天,直到查询集 需要求值时,Django 才会真正运行这个查询。
queryResult=models.Article.objects.all() # not hits database
print(queryResult) # hits database
for article in queryResult:
print(article.title) # hits database
一般来说,只有在“请求”查询集 的结果时才会到数据库中去获取它们。当你确实需要结果时,查询集 通过访问数据库来求值
缓存机制
每个查询集都包含一个缓存来最小化对数据库的访问。理解它是如何工作的将让你编写最高效的代码。
在一个新创建的查询集中,缓存为空。首次对查询集进行求值 —— 同时发生数据库查询 ——Django 将保存查询的结果到查询集的缓存中并返回明确请求的结果(例如,如果正在迭代查询集,则返回下一个结果)。接下来对该查询集 的求值将重用缓存的结果。
请牢记这个缓存行为,因为对查询集使用不当的话,它会坑你的。例如,下面的语句创建两个查询集,对它们求值,然后扔掉它们:
print([a.title for a in models.Article.objects.all()])
print([a.create_time for a in models.Article.objects.all()])
这意味着相同的数据库查询将执行两次,显然倍增了你的数据库负载。同时,还有可能两个结果列表并不包含相同的数据库记录,因为在两次请求期间有可能有Article被添加进来或删除掉。为了避免这个问题,只需保存查询集并重新使用它:
queryResult=models.Article.objects.all()
print([a.title for a in queryResult])
print([a.create_time for a in queryResult])
何时查询集不会被缓存?
查询集不会永远缓存它们的结果。当只对查询集的部分进行求值时会检查缓存, 如果这个部分不在缓存中,那么接下来查询返回的记录都将不会被缓存。所以,这意味着使用切片或索引来限制查询集将不会填充缓存。
例如,重复获取查询集对象中一个特定的索引将每次都查询数据库:
queryset = Entry.objects.all()
print queryset[5] # Queries the database
print queryset[5] # Queries the database again
然而,如果已经对全部查询集求值过,则将检查缓存:
queryset = Entry.objects.all()
[entry for entry in queryset] # Queries the database
print queryset[5] # Uses cache
print queryset[5] # Uses cache
下面是一些其它例子,它们会使得全部的查询集被求值并填充到缓存中:
[entry for entry in queryset]
bool(queryset)
entry in queryset
list(queryset)
注:简单地打印查询集不会填充缓存。
queryResult=models.Article.objects.all()
print(queryResult) # hits database
print(queryResult) # hits database
exists()与iterator()方法
exists:
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些 数据!为了避免这个,可以用exists()方法来检查是否有数据:
if queryResult.exists():
#SELECT (1) AS "a" FROM "blog_article" LIMIT 1; args=()
print("exists...")
iterator:
当queryset非常巨大时,cache会成为问题。
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统 进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法 来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.title)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.title)
当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使 #用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询。
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。 使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能 会造成额外的数据库查询。
中介模型
处理类似搭配 pizza 和 topping 这样简单的多对多关系时,使用标准的ManyToManyField 就可以了。但是,有时你可能需要关联数据到两个模型之间的关系上。
例如,有这样一个应用,它记录音乐家所属的音乐小组。我们可以用一个ManyToManyField 表示小组和成员之间的多对多关系。但是,有时你可能想知道更多成员关系的细节,比如成员是何时加入小组的。
对于这些情况,Django 允许你指定一个中介模型来定义多对多关系。 你可以将其他字段放在中介模型里面。源模型的ManyToManyField 字段将使用through 参数指向中介模型。对于上面的音乐小组的例子,代码如下:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self): # __unicode__ on Python 2
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through='Membership')
def __str__(self): # __unicode__ on Python 2
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person)
group = models.ForeignKey(Group)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
既然你已经设置好ManyToManyField 来使用中介模型(在这个例子中就是Membership),接下来你要开始创建多对多关系。你要做的就是创建中介模型的实例:
>>> ringo = Person.objects.create(name="Ringo Starr")
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(person=ringo, group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason="Needed a new drummer.")
>>> m1.save()
>>> beatles.members.all()
[<Person: Ringo Starr>]
>>> ringo.group_set.all()
[<Group: The Beatles>]
>>> m2 = Membership.objects.create(person=paul, group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason="Wanted to form a band.")
>>> beatles.members.all()
[<Person: Ringo Starr>, <Person: Paul McCartney>]
与普通的多对多字段不同,你不能使用add、 create和赋值语句(比如,beatles.members = [...])来创建关系:
# THIS WILL NOT WORK
>>> beatles.members.add(john)
# NEITHER WILL THIS
>>> beatles.members.create(name="George Harrison")
# AND NEITHER WILL THIS
>>> beatles.members = [john, paul, ringo, george]
为什么不能这样做? 这是因为你不能只创建 Person和 Group之间的关联关系,你还要指定 Membership模型中所需要的所有信息;而简单的add、create 和赋值语句是做不到这一点的。所以它们不能在使用中介模型的多对多关系中使用。此时,唯一的办法就是创建中介模型的实例。
remove()方法被禁用也是出于同样的原因。但是clear() 方法却是可用的。它可以清空某个实例所有的多对多关系:
>>> # Beatles have broken up
>>> beatles.members.clear()
>>> # Note that this deletes the intermediate model instances
>>> Membership.objects.all()
[]
表数据
class UserInfo(AbstractUser):
"""
用户信息
"""
nid = models.BigAutoField(primary_key=True)
nickname = models.CharField(verbose_name='昵称', max_length=32)
telephone = models.CharField(max_length=11, blank=True, null=True, unique=True, verbose_name='手机号码')
avatar = models.FileField(verbose_name='头像',upload_to = 'avatar/',default="/avatar/default.png")
create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True)
fans = models.ManyToManyField(verbose_name='粉丝们',
to='UserInfo',
through='UserFans',
related_name='f',
through_fields=('user', 'follower'))
def __str__(self):
return self.username
class UserFans(models.Model):
"""
互粉关系表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey(verbose_name='博主', to='UserInfo', to_field='nid', related_name='users')
follower = models.ForeignKey(verbose_name='粉丝', to='UserInfo', to_field='nid', related_name='followers')
class Blog(models.Model):
"""
博客信息
"""
nid = models.BigAutoField(primary_key=True)
title = models.CharField(verbose_name='个人博客标题', max_length=64)
site = models.CharField(verbose_name='个人博客后缀', max_length=32, unique=True)
theme = models.CharField(verbose_name='博客主题', max_length=32)
user = models.OneToOneField(to='UserInfo', to_field='nid')
def __str__(self):
return self.title
class Category(models.Model):
"""
博主个人文章分类表
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='分类标题', max_length=32)
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid')
class Article(models.Model):
nid = models.BigAutoField(primary_key=True)
title = models.CharField(max_length=50, verbose_name='文章标题')
desc = models.CharField(max_length=255, verbose_name='文章描述')
read_count = models.IntegerField(default=0)
comment_count= models.IntegerField(default=0)
up_count = models.IntegerField(default=0)
down_count = models.IntegerField(default=0)
category = models.ForeignKey(verbose_name='文章类型', to='Category', to_field='nid', null=True)
create_time = models.DateField(verbose_name='创建时间')
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid')
tags = models.ManyToManyField(
to="Tag",
through='Article2Tag',
through_fields=('article', 'tag'),
)
class ArticleDetail(models.Model):
"""
文章详细表
"""
nid = models.AutoField(primary_key=True)
content = models.TextField(verbose_name='文章内容', )
article = models.OneToOneField(verbose_name='所属文章', to='Article', to_field='nid')
class Comment(models.Model):
"""
评论表
"""
nid = models.BigAutoField(primary_key=True)
article = models.ForeignKey(verbose_name='评论文章', to='Article', to_field='nid')
content = models.CharField(verbose_name='评论内容', max_length=255)
create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True)
parent_comment = models.ForeignKey('self', blank=True, null=True, verbose_name='父级评论')
user = models.ForeignKey(verbose_name='评论者', to='UserInfo', to_field='nid')
up_count = models.IntegerField(default=0)
def __str__(self):
return self.content
class ArticleUpDown(models.Model):
"""
点赞表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey('UserInfo', null=True)
article = models.ForeignKey("Article", null=True)
models.BooleanField(verbose_name='是否赞')
class CommentUp(models.Model):
"""
点赞表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey('UserInfo', null=True)
comment = models.ForeignKey("Comment", null=True)
class Tag(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='标签名称', max_length=32)
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid')
class Article2Tag(models.Model):
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid')
tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid')
查询优化select_related
简单使用
对于一对一字段(OneToOneField)和外键字段(ForeignKey),可以使用select_related 来对QuerySet进行优化。
select_related 返回一个QuerySet,当执行它的查询时它沿着外键关系查询关联的对象的数据。它会生成一个复杂的查询并引起性能的损耗,但是在以后使用外键关系时将不需要数据库查询。
简单说,在对QuerySet使用select_related()函数后,Django会获取相应外键对应的对象,从而在之后需要的时候不必再查询数据库了。
下面的例子解释了普通查询和select_related() 查询的区别。
查询id=2的文章的分类名称,下面是一个标准的查询:
# Hits the database.
article=models.Article.objects.get(nid=2)
# Hits the database again to get the related Blog object.
print(article.category.title)
'''
SELECT
"blog_article"."nid",
"blog_article"."title",
"blog_article"."desc",
"blog_article"."read_count",
"blog_article"."comment_count",
"blog_article"."up_count",
"blog_article"."down_count",
"blog_article"."category_id",
"blog_article"."create_time",
"blog_article"."blog_id",
"blog_article"."article_type_id"
FROM "blog_article"
WHERE "blog_article"."nid" = 2; args=(2,)
SELECT
"blog_category"."nid",
"blog_category"."title",
"blog_category"."blog_id"
FROM "blog_category"
WHERE "blog_category"."nid" = 4; args=(4,)
'''
如果我们使用select_related()函数:
articleList=models.Article.objects.select_related("category").all()
for article_obj in articleList:
# Doesn't hit the database, because article_obj.category
# has been prepopulated in the previous query.
#不再查询数据库,因为第一次查询,数据已经填充进去了
print(article_obj.category.title)
多外键查询
这是针对category的外键查询,如果是另外一个外键呢?让我们一起看下:
article=models.Article.objects.select_related("category").get(nid=1)
print(article.articledetail)
观察logging结果,发现依然需要查询两次,所以需要改为:
article=models.Article.objects.select_related("category","articledetail").get(nid=1)
print(article.articledetail)
或者:1.7以后支持链式操作
article=models.Article.objects
.select_related("category")
.select_related("articledetail")
.get(nid=1) # django 1.7 支持链式操作
print(article.articledetail)
SELECT
"blog_article"."nid",
"blog_article"."title",
......
"blog_category"."nid",
"blog_category"."title",
"blog_category"."blog_id",
"blog_articledetail"."nid",
"blog_articledetail"."content",
"blog_articledetail"."article_id"
FROM "blog_article"
LEFT OUTER JOIN "blog_category" ON ("blog_article"."category_id" = "blog_category"."nid")
LEFT OUTER JOIN "blog_articledetail" ON ("blog_article"."nid" = "blog_articledetail"."article_id")
WHERE "blog_article"."nid" = 1; args=(1,)
深层查询
# 查询id=1的文章的用户姓名
article=models.Article.objects.select_related("blog").get(nid=1)
print(article.blog.user.username)
依然需要查询两次:
SELECT
"blog_article"."nid",
"blog_article"."title",
......
"blog_blog"."nid",
"blog_blog"."title",
FROM "blog_article" INNER JOIN "blog_blog" ON ("blog_article"."blog_id" = "blog_blog"."nid")
WHERE "blog_article"."nid" = 1;
SELECT
"blog_userinfo"."password",
"blog_userinfo"."last_login",
......
FROM "blog_userinfo"
WHERE "blog_userinfo"."nid" = 1;
这是因为第一次查询没有query到userInfo表,所以,修改如下:
article=models.Article.objects.select_related("blog__user").get(nid=1)
print(article.blog.user.username)
SELECT
"blog_article"."nid", "blog_article"."title",
......
"blog_blog"."nid", "blog_blog"."title",
......
"blog_userinfo"."password", "blog_userinfo"."last_login",
......
FROM "blog_article"
INNER JOIN "blog_blog" ON ("blog_article"."blog_id" = "blog_blog"."nid")
INNER JOIN "blog_userinfo" ON ("blog_blog"."user_id" = "blog_userinfo"."nid")
WHERE "blog_article"."nid" = 1;
总结
- select_related主要针一对一和多对一关系进行优化。
- select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
- 可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。
- 没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
- 也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
- 也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
- Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个。
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。
# 查询所有文章关联的所有标签
article_obj=models.Article.objects.all()
for i in article_obj:
print(i.tags.all()) #4篇文章: hits database 5
改为prefetch_related:
# 查询所有文章关联的所有标签
article_obj=models.Article.objects.prefetch_related("tags").all()
for i in article_obj:
print(i.tags.all()) #4篇文章: hits database 2
SELECT "blog_article"."nid",
"blog_article"."title",
......
FROM "blog_article";
SELECT
("blog_article2tag"."article_id") AS "_prefetch_related_val_article_id",
"blog_tag"."nid",
"blog_tag"."title",
"blog_tag"."blog_id"
FROM "blog_tag"
INNER JOIN "blog_article2tag" ON ("blog_tag"."nid" = "blog_article2tag"."tag_id")
WHERE "blog_article2tag"."article_id" IN (1, 2, 3, 4);
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related('外键字段')
model.tb.objects.all().select_related('外键字段__外键字段')
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type='Excused', then=1),
default=0,
output_field=models.IntegerField()
)))
# 加select_related 主动做链表,相当于直接链表把数据全取出来了,
# 不加:for循环几次,就再次查几次数据库
# select_related('author_detail')参数是fk的字段,可能有多个外键,所以可以写多个
ret=models.Author.objects.all().select_related('author_detail')
for i in ret:
print(i.author_detail.addr)
ret = models.Author.objects.all()
for i in ret:
print(i.author_detail.addr)
# 用了fk,但是不做链表,做多次查询,把结果集都放到对象中
# 两次查询,相当于select * from author_detail where nid in [1,2]
ret=models.Author.objects.all().prefetch_related('author_detail')
for i in ret:
print(i.author_detail.addr)
# 总结:数据量少,可以用select_related
# 数据量比较多用prefetch_related
查询优化extra
extra(select=None, where=None, params=None,
tables=None, order_by=None, select_params=None)
有些情况下,Django的查询语法难以简单的表达复杂的 WHERE 子句,对于这种情况, Django 提供了 extra() QuerySet修改机制 — 它能在 QuerySet生成的SQL从句中注入新子句
extra可以指定一个或多个 参数,例如 select, where or tables. 这些参数都不是必须的,但是你至少要使用一个!要注意这些额外的方式对不同的数据库引擎可能存在移植性问题.(因为你在显式的书写SQL语句),除非万不得已,尽量避免这样做
参数之select
The select 参数可以让你在 SELECT 从句中添加其他字段信息,它应该是一个字典,存放着属性名到 SQL 从句的映射。
queryResult=models.Article
.objects.extra(select={'is_recent': "create_time > '2017-09-05'"})
结果集中每个 Entry 对象都有一个额外的属性is_recent, 它是一个布尔值,表示 Article对象的create_time 是否晚于2017-09-05.
练习:
# in sqlite:
article_obj=models.Article.objects
.filter(nid=1)
.extra(select={"standard_time":"strftime('%%Y-%%m-%%d',create_time)"})
.values("standard_time","nid","title")
print(article_obj)
# <QuerySet [{'title': 'MongoDb 入门教程', 'standard_time': '2017-09-03', 'nid': 1}]>
参数之where / tables
您可以使用where定义显式SQL WHERE子句 - 也许执行非显式连接。您可以使用tables手动将表添加到SQL FROM子句。
where和tables都接受字符串列表。所有where参数均为“与”任何其他搜索条件。
举例来讲:
queryResult=models.Article
.objects.extra(where=['nid in (1,3) OR title like "py%" ','nid>2'])
extra, 额外查询条件以及相关表,排序
models.UserInfo.objects.filter(id__gt=1)
models.UserInfo.objects.all()
# id name age ut_id
models.UserInfo.objects.extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# a. 映射
# select
# select_params=None
# select 此处 from 表
# b. 条件
# where=None
# params=None,
# select * from 表 where 此处
# c. 表
# tables
# select * from 表,此处
# c. 排序
# order_by=None
# select * from 表 order by 此处
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
"""
result = models.UserInfo.objects.filter(id__gt=1).extra(
where=['app01_userinfo.id < %s'],
params=[100,],
tables=['app01_usertype'],
order_by=['-app01_userinfo.id'],
select={'uid':1,'sw':"select count(1) from app01_userinfo"}
)
print(result.query)
# SELECT (1) AS "uid", (select count(1) from app01_userinfo) AS "sw", "app01_userinfo"."id", "app01_userinfo"."name", "app01_userinfo"."age", "app01_userinfo"."ut_id" FROM "app01_userinfo" , "app01_usertype" WHERE ("app01_userinfo"."id" > 1 AND (app01_userinfo.id < 100)) ORDER BY ("app01_userinfo".id) DESC
# 在对象中加入字段
ret=models.Author.objects.all().filter(nid__gt=1).extra(select={'n':'select count(*) from app01_book where nid>%s'},select_params=[1])
print(ret[0].n)
print(ret.query)
# 给字段重命名
ret=models.Author.objects.all().filter(author_detail__telephone=132234556).extra(select={'bb':"app01_authordatail.telephone"}).values('bb')
print(ret)
print(ret.query)
原生sql
from django.db import connection, connections
cursor = connection.cursor() # connection=default数据
cursor = connections['db2'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone()
row = cursor.fetchall()
ret=models.Author.objects.raw('select * from app01_author where nid>1')
print(ret)
for i in ret:
print(i)
print(ret.query)
# 会把book的字段放到author对象中
ret=models.Author.objects.raw('select * from app01_book where nid>1')
print(ret)
for i in ret:
print(i.price)
print(type(i))
整体插入
创建对象时,尽可能使用bulk_create()来减少SQL查询的数量。例如:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
...更优于:
Entry.objects.create(headline="Python 3.0 Released")
Entry.objects.create(headline="Python 3.1 Planned")
注意该方法有很多注意事项,所以确保它适用于你的情况。
这也可以用在ManyToManyFields中,所以:
my_band.members.add(me, my_friend)
...更优于:
my_band.members.add(me)
my_band.members.add(my_friend)
...其中Bands和Artists具有多对多关联。
一般操作
在进行一般操作时先配置一下参数,使得我们可以直接在Django页面中运行我们的测试脚本
在Python脚本中调用Django环境
模型转为mysql数据库中的表settings配置
需要在settings中配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'tabledatabase',
'USER':'root',
'PASSWORD':'root',
'HOST':'127.0.0.1',
'PORT':3306,
'CHARSET':'utf8',
'ATOMIC_REQUEST': True,
'OPTIONS': {
"init_command": "SET storage_engine=MyISAM",
}
}
}
'''
'NAME':要连接的数据库,连接前需要创建好
'USER':连接数据库的用户名
'PASSWORD':连接数据库的密码
'HOST':连接主机,默认本机
'PORT':端口 默认3306
'CHARSET':'utf8',字符编码默认utf8
'ATOMIC_REQUEST': True,
设置为True统一个http请求对应的所有sql都放在一个事务中执行(要么所有都成功,要么所有都失败)。
是全局性的配置, 如果要对某个http请求放水(然后自定义事务),可以用non_atomic_requests修饰器
'OPTIONS': {
"init_command": "SET storage_engine=MyISAM",
}
设置创建表的存储引擎为MyISAM,INNODB
'''
注意1:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb 。这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入:
import pymysql
pymysql.install_as_MySQLdb()
最后通过两条数据库迁移命令即可在指定的数据库中创建表 :
python manage.py makemigrations
python manage.py migrate
注意2:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"app01"
]
注意3:如果报错如下:
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
MySQLclient目前只支持到python3.4,因此如果使用的更高版本的python,需要修改如下:
通过查找路径C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql
这个路径里的文件把
if version < (1, 3, 3):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__)
注释掉就可以了
测试文件tests.py的使用和配置

import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "untitled15.settings")
import django
django.setup()
from app01 import models
books = models.Book.objects.all()
print(books)
这样就可以直接运行你的test.py文件来运行测试
Django终端打印SQL语句settings中配置
如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上
补充:
除了配置外,还可以通过一点.query即可查看查询语句,具体操作如下:

单表的数据准备
操作下面的操作之前,我们实现创建好了数据表,这里主要演示下面的操作,不再细讲创建准备过程
python manage.py makemigrations
python manage.py migrate
.models.py
from django.db import models
# Create your models here.
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_data = models.DateField()
def __str__(self):
return self.title
tests.py
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "onetable.settings")
import django
django.setup()
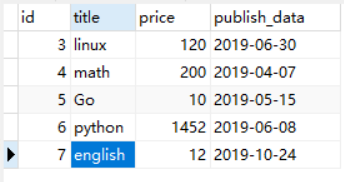
单表操作增删改
from oneapp import models
import datetime
增加
res = models.Book.objects.create(title='python',price=121,publish_data=datetime.datetime.now())
print(res)
res1 = models.Book.objects.create(title='python',price=121,publish_data='2019-5-4')
print(res1)
book_obj = models.Book(title='math',price=120,publish_data='2019-4-7')
book_obj.save()
删除
res = models.Book.objects.filter(title='python').delete()
print(res)
修改
res = models.Book.objects.filter(pk=3).update(title='linux')
print(res)
book_obj= models.Book.objects.filter(pk=5).first()
book_obj.title = 'Go'
book_obj.save()
必知必会单表查询13条
<1> all(): 查询所有结果
1
res = models.Book.objects.all()
print(res)
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
2
res = models.Book.objects.filter()
print(res)
res = models.Book.objects.filter(title='python')
print(res.first().price)
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
3
res = models.Book.objects.get(title='python')
print(res)
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
4
res = models.Book.objects.exclude(id=4)
print(res)
<5> values(*field): 返回一个ValueQuerySet——一个特殊的
QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
5
res = models.Book.objects.values('title')
print(res)
<6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
6
res = models.Book.objects.values_list('title')
print(res,type(res.first()))
<7> order_by(*field): 对查询结果排序
7
res = models.Book.objects.order_by('price')#默认是升序
print(res)
res = models.Book.objects.order_by('-price')
print(res)
<8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。不能传值
8
print(models.Book.objects.order_by('price'))
res = models.Book.objects.order_by('price').reverse()
print(res)
<9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。不能传值
9
res = models.Book.objects.all().distinct()
print(res)
<10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。不能传值
10
res = models.Book.objects.all().count()
print(res)
<11> first(): 返回第一条记录
11
res = models.Book.objects.all().first()
print(res)
<12> last(): 返回最后一条记录
12
res = models.Book.objects.all().last()
print(res)
<13> exists(): 如果QuerySet包含数据,就返回True,否则返回False,不能传值
13
res = models.Book.objects.all().exists()
print(res)
13个必会单表操作方法总结
查询API
返回QuerySet对象的方法有
all()查询所有结果
filter()它包含了与所给筛选条件相匹配的对象,不加条件的时候返回所有。和all()相同。
exclude()它包含了与所给筛选条件不匹配的对象
order_by()对查询结果排序('-id')
reverse()对查询结果反向排序,对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。
distinct()从返回结果中剔除重复纪录
特殊的QuerySet
values() 返回一个可迭代的字典序列,返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列,获取所有的值,以字典的形式打印
values_list() 返回一个可迭代的元祖序列,它与values()非常相似,它返回的是一个元组序列。
返回具体对象的
get() 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
first() 返回第一条记录
last()返回最后一条记录
返回数字的方法有
count()返回数据库中匹配查询(QuerySet)的对象数量。
返回布尔值的方法有:
exists()如果QuerySet包含数据,就返回True,否则返回False
不能传值的有
count(),first(),last(),exists(),distinct(),all()
单表查询之神奇的双下划线
查询价格大于200的书籍
res = models.Book.objects.filter(price__gt=200)
查询价格小于200的书籍
res = models.Book.objects.filter(price__lt=200)
查询价格大于或者等于200的书籍
res = models.Book.objects.filter(price__gte=200)
res1 = models.Book.objects.filter(price__lte=200)
价格是200 或者是123.23 或者666.66
res = models.Book.objects.filter(price__in=[200,123.23,666.66])
价格在200 到700之间的书籍
res = models.Book.objects.filter(price__range=(200,666.66))# 顾头不顾尾
res = models.Book.objects.filter(price__range=[10, 200])
模糊匹配
# 模糊匹配
"""
like
%
_
"""
查询书籍名称中包含p的
res = models.Book.objects.filter(title__contains='p') # 区分大小写
忽略大小写
res = models.Book.objects.filter(title__icontains='p') # 忽略大小写
查询书籍名称是以三开头的书籍
res = models.Book.objects.filter(title__startswith='p')
res1 = models.Book.objects.filter(title__endswith='h')
print(res1)
查询出版日期是2019年的书籍
res = models.Book.objects.filter(publish_date__year='2019')
查询出版日期是10月的书籍
res = models.Book.objects.filter(publish_date__month='10')
date时间操作
Book.objects.filter(pub_date__year=2012)
date字段还可以:
models.Book.objects.filter(first_day__year=2017)
date字段可以通过在其后加__year,__month,__day等来获取date的特点部分数据
# date
# Book.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Book.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
# year
#
# Book.objects.filter(pub_date__year=2005)
# Book.objects.filter(pub_date__year__gte=2005)
# month
#
# Book.objects.filter(pub_date__month=12)
# Book.objects.filter(pub_date__month__gte=6)
# day
#
# Book.objects.filter(pub_date__day=3)
# Book.objects.filter(pub_date__day__gte=3)
# week_day
#
# Book.objects.filter(pub_date__week_day=2)
# Book.objects.filter(pub_date__week_day__gte=2)
需要注意的是在表示一年的时间的时候,我们通常用52周来表示,因为天数是不确定的,老外就是按周来计算薪资的哦~
ForeignKey操作
正向查找(两种方式)
1.对象查找(跨表)
语法:
对象.关联字段.字段
要点:先拿到对象,再通过对象去查对应的外键字段,分两步
示例:
book_obj = models.Book.objects.first() # 第一本书对象(第一步)
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称
2.字段查找(跨表)
语法:
关联字段__字段
要点:利用Django给我们提供的神奇的双下划线查找方式
示例:
models.Book.objects.all().values("publisher__name")
#拿到所有数据对应的出版社的名字,神奇的下划线帮我们夸表查询
反向操作(两种方式)
1.对象查找
语法:
obj.表名_set
要点:先拿到外键关联多对一,一中的某个对象,由于外键字段设置在多的一方,所以这里还是借用Django提供的双下划线来查找
示例:
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
结论:如果想通过一的那一方去查找多的一方,由于外键字段不在一这一方,所以用__set来查找即可
2.字段查找
语法:
表名__字段
要点:直接利用双下滑线完成夸表操作
titles = models.Publisher.objects.values("book__title")
ManyToManyField
class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是在多对多表关系并且这一张多对多的关系表是有Django自动帮你建的情况下,下面的方法才可使用。
方法,add(),set(),remove(),clear()
create()
创建一个关联对象,并自动写入数据库,且在第三张双方的关联表中自动新建上双方对应关系。
models.Author.objects.first().book_set.create(title="偷塔秘籍")
上面这一句干了哪些事儿:
1.由作者表中的一个对象跨到书籍比表
2.新增名为偷塔秘籍的书籍并保存
3.到作者与书籍的第三张表中新增两者之间的多对多关系并保存
add()
add() 括号内既可以传数字也可以传数据对象,并且都支持传多个
把指定的model对象添加到第三张关联表中。
添加对象,添加id
book_obj = models.Book.objects.filter(pk=3).first()
print(book_obj.authors) # 就相当于 已经在书籍和作者的关系表了
book_obj.authors.add(1)
book_obj.authors.add(2,3)
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj)
book_obj.authors.add(author_obj,author_obj1)
set()
set() 括号内 既可以传数字也传对象
并且也是支持传多个的
但是需要注意 括号内必须是一个可迭代对象
更新某个对象在第三张表中的关联对象。不同于上面的add是添加,set相当于重置,可以添加对象和id
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.set([3,])
book_obj.authors.set([1,3])
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.set((author_obj,))
book_obj.authors.set((author_obj,author_obj1))
remove()
remove() 括号内 既可以传数字也传对象 并且也是支持传多个的
从关联对象集中移除执行的model对象(移除对象在第三张表中与某个关联对象的关系)
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.remove(2)
book_obj.authors.remove(1,2)
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.remove(author_obj)
book_obj.authors.remove(author_obj,author_obj1)
clear()
clear()括号内不需要传任何参数 直接清空当前书籍对象所有的记录
从关联对象集中移除一切对象。(移除所有与对象相关的关系信息)
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在。
举个例子:
ForeignKey字段没设置null=True时,
class Book(models.Model):
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher)
没有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'RelatedManager' object has no attribute 'clear'
当ForeignKey字段设置null=True时,
class Book(models.Model):
name = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Class, null=True)
此时就有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
再次强调:
- 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
注意:关联字段与外键约束没有必然的联系(建管理字段是为了进行查询,建约束是为了不出现脏数据)
在Models创建如下模型
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
# 阅读数
# reat_num=models.IntegerField(default=0)
# 评论数
# commit_num=models.IntegerField(default=0)
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.name
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE)
class AuthorDatail(models.Model):
nid = models.AutoField(primary_key=True)
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加
"_id"来创建数据库中的列名 - 这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
- 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
二 添加表记录
一对多的
方式1:
publish_obj=Publish.objects.get(nid=1)
book_obj=Book.objects.create(title="",publishDate="2012-12-12",price=100,publish=publish_obj)
方式2:
book_obj=Book.objects.create(title="",publishDate="2012-12-12",price=100,publish_id=1)
核心:book_obj.publish与book_obj.publish_id是什么?
关键点:
一 book_obj.publish=Publish.objects.filter(id=book_obj.publish_id).first()
二 book_obj.authors.all()
关键点:book.authors.all() # 与这本书关联的作者集合
1 book.id=3
2 book_authors
id book_id author_ID
3 3 1
4 3 2
3 author
id name
1 alex
2 egon
book_obj.authors.all() -------> [alex,egon]
# -----一对多添加
pub=Publish.objects.create(name='egon出版社',email='445676@qq.com',city='山东')
print(pub)
# 为book表绑定和publish的关系
import datetime,time
now=datetime.datetime.now().__str__()
now = datetime.datetime.now().strftime('%Y-%m-%d')
print(type(now))
print(now)
# 日期类型必须是日期对象或者字符串形式的2018-09-12(2018-9-12),其它形式不行
Book.objects.create(name='海燕3',price=333.123,publish_date=now,publish_id=2)
Book.objects.create(name='海3燕3',price=35.123,publish_date='2018/02/28',publish=pub)
pub=Publish.objects.filter(nid=1).first()
book=Book.objects.create(name='测试书籍',price=33,publish_date='2018-7-28',publish=pub)
print(book.publish.name)
# 查询出版了红楼梦这本书出版社的邮箱
book=Book.objects.filter(name='红楼梦').first()
print(book.publish.email)
多对多
# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的做作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录
# 绑定多对多关系,即向关系表book_authors中添加纪录
book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
book = Book.objects.filter(name='红楼梦').first()
egon=Author.objects.filter(name='egon').first()
lqz=Author.objects.filter(name='lqz').first()
# 1 没有返回值,直接传对象
book.authors.add(lqz,egon)
# 2 直接传作者id
book.authors.add(1,3)
# 3 直接传列表,会打散
book.authors.add(*[1,2])
# 解除多对多关系
book = Book.objects.filter(name='红楼梦').first()
# 1 传作者id
book.authors.remove(1)
# 2 传作者对象
egon = Author.objects.filter(name='egon').first()
book.authors.remove(egon)
#3 传*列表
book.authors.remove(*[1,2])
#4 删除所有
book.authors.clear()
# 5 拿到与 这本书关联的所有作者,结果是queryset对象,作者列表
ret=book.authors.all()
# print(ret)
# 6 queryset对象,又可以继续点(查询红楼梦这本书所有作者的名字)
ret=book.authors.all().values('name')
print(ret)
# 以上总结:
# (1)
# book=Book.objects.filter(name='红楼梦').first()
# print(book)
# 在点publish的时候,其实就是拿着publish_id又去app01_publish这个表里查数据了
# print(book.publish)
# (2)book.authors.all()
核心:book_obj.authors.all()是什么?
多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
book_obj.authors.clear() #清空被关联对象集合
book_obj.authors.set() #先清空再设置
三 基于对象的跨表查询
ORM跨表查询
1.子查询
2.连表查询
正反向的概念
外键字段在谁那儿 由谁查谁就是正向
谁手里有外键字段 谁就是正向查
没有外键字段的就是反向
书籍对象 查 出版社 外键字段在书籍 正向查询
出版社 查 书籍 外键字段在书籍 反向查询
正向查询按字段
反向查询按表名小写 ...
# 1.基于对象的跨表查询 子查询
# 1.查询书籍是python入门的出版社名称
# book_obj = models.Book.objects.filter(title='python入门').first()
# # 正向查询按字段
# print(book_obj.publish.name)
# print(book_obj.publish.addr)
# 2.查询书籍主键是6的作者姓名
# book_obj = models.Book.objects.filter(pk=6).first()
# # print(book_obj.authors) # app01.Author.None
# print(book_obj.authors.all())
# 3.查询作者是jason的手机号
# author_obj = models.Author.objects.filter(name='jason').first()
# print(author_obj.author_detail.phone)
# print(author_obj.author_detail.addr)
"""
正向查询 按字段
当该字段所对应的数据有多个的时候 需要加.all()
否者点外键字段直接就能够拿到数据对象
"""
# 4.查询出版社是东方出版社出版过的书籍
# publish_obj = models.Publish.objects.filter(name='东方出版社').first()
# # print(publish_obj.book_set) # app01.Book.None
# print(publish_obj.book_set.all())
# 5.查询作者是jason写过的所有的书
# author_obj = models.Author.objects.filter(name='jason').first()
# # print(author_obj.book_set) # app01.Book.None
# print(author_obj.book_set.all())
# 6.查询手机号是110的作者
# author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
# print(author_detail_obj.author)
# print(author_detail_obj.author.name)
# print(author_detail_obj.author.age)
"""
反向查询按表名小写
什么时候需要加_set
当查询的结果可以是多个的情况下 需要加_set.all()
什么时候不需要加_set
当查询的结果有且只有一个的情况下 不需要加任何东西 直接表名小写即可
"""
# 7.查询书籍是python入门的作者的手机号
# book_obj = models.Book.objects.filter(title='python入门').first()
# print(book_obj.authors.all())
# 2.基于双下划綫的跨表查询 连表查询
"""
MySQL
left join
inner join
right join
union
"""
# 1.查询书籍是python入门的出版社名称
# 正向
# res = models.Book.objects.filter(title='python入门').values('publish__name')
# print(res)
# 反向
# res = models.Publish.objects.filter(book__title='python入门').values('name')
# print(res)
# 2.查询作者是jason的手机号码
# 正向
# res1 = models.Author.objects.filter(name='jason').values('author_detail__phone')
# print(res1)
# 反向
# res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__age')
# print(res)
# 3.查询手机号是120的作者姓名
# res2 = models.AuthorDetail.objects.filter(phone=120).values('author__name')
# print(res2)
# res = models.Author.objects.filter(author_detail__phone=120).values('name','author_detail__addr')
# print(res)
# 4.查询出版社是东方出版社出版的书籍名称
# res = models.Publish.objects.filter(name='东方出版社').values('book__title','addr')
# print(res)
# 5.查询作者是jason的写过的书的名字和价格
# res = models.Author.objects.filter(name='jason').values('book__title','book__price')
# print(res)
# 7.查询书籍是python入门的作者的手机号
# res = models.Book.objects.filter(title='python入门').values('authors__author_detail__phone')
# print(res)
一对多查询(publish与book)
正向查询(按字段:publish)
# 查询主键为1的书籍的出版社所在的城市
book_obj=Book.objects.filter(pk=1).first()
# book_obj.publish 是主键为1的书籍对象关联的出版社对象
print(book_obj.publish.city)
反向查询(按表名:book_set)
publish=Publish.objects.get(name="苹果出版社")
#publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合
book_list=publish.book_set.all()
for book_obj in book_list:
print(book_obj.title)
# 一对多正向查询
book=Book.objects.filter(name='红楼梦').first()
print(book.publish)#与这本书关联的出版社对象
print(book.publish.name)
# 一对多反向查询
# 人民出版社出版过的书籍名称
pub=Publish.objects.filter(name='人民出版社').first()
ret=pub.book_set.all()
print(ret)
一对一查询(Author 与 AuthorDetail)
正向查询(按字段:authorDetail):
egon=Author.objects.filter(name="egon").first()
print(egon.authorDetail.telephone)
反向查询(按表名:author):
# 查询所有住址在北京的作者的姓名
authorDetail_list=AuthorDetail.objects.filter(addr="beijing")
for obj in authorDetail_list:
print(obj.author.name)
# 一对一正向查询
# lqz的手机号
lqz=Author.objects.filter(name='lqz').first()
tel=lqz.author_detail.telephone
print(tel)
# 一对一反向查询
# 地址在北京的作者姓名
author_detail=AuthorDatail.objects.filter(addr='北京').first()
name=author_detail.author.name
print(name)
多对多查询 (Author 与 Book)
正向查询(按字段:authors):
# 眉所有作者的名字以及手机号
book_obj=Book.objects.filter(title="眉").first()
authors=book_obj.authors.all()
for author_obj in authors:
print(author_obj.name,author_obj.authorDetail.telephone)
反向查询(按表名:book_set):
# 查询egon出过的所有书籍的名字
author_obj=Author.objects.get(name="egon")
book_list=author_obj.book_set.all() #与egon作者相关的所有书籍
for book_obj in book_list:
print(book_obj.title)
# 正向查询----查询红楼梦所有作者名称
book=Book.objects.filter(name='红楼梦').first()
ret=book.authors.all()
print(ret)
for auth in ret:
print(auth.name)
# 反向查询 查询lqz这个作者写的所有书
author=Author.objects.filter(name='lqz').first()
ret=author.book_set.all()
print(ret)
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改:
publish = ForeignKey(Book, related_name='bookList')
那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍
publish=Publish.objects.get(name="人民出版社")
book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
'''
一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects.filter(publish__name="苹果出版社").values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects.filter(name="苹果出版社").values_list("book__title","book__price")查询的本质一样,就是select from的表不一样
# 正向查询按字段,反向查询按表名小写
# 查询红楼梦这本书出版社的名字
# select * from app01_book inner join app01_publish
# on app01_book.publish_id=app01_publish.nid
ret=Book.objects.filter(name='红楼梦').values('publish__name')
print(ret)
ret=Publish.objects.filter(book__name='红楼梦').values('name')
print(ret)
多对多查询
# 练习: 查询alex出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects.filter(authors__name="yuan").values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects.filter(name="yuan").values_list("book__title","book__price")
# 正向查询按字段,反向查询按表名小写
# 查询红楼梦这本书出版社的名字
# select * from app01_book inner join app01_publish
# on app01_book.publish_id=app01_publish.nid
ret=Book.objects.filter(name='红楼梦').values('publish__name')
print(ret)
ret=Publish.objects.filter(book__name='红楼梦').values('name')
print(ret)
# sql 语句就是from的表不一样
# -------多对多正向查询
# 查询红楼梦所有的作者
ret=Book.objects.filter(name='红楼梦').values('authors__name')
print(ret)
# ---多对多反向查询
ret=Author.objects.filter(book__name='红楼梦').values('name')
ret=Author.objects.filter(book__name='红楼梦').values('name','author_detail__addr')
print(ret)
一对一查询
# 查询alex的手机号
# 正向查询
ret=Author.objects.filter(name="alex").values("authordetail__telephone")
# 反向查询
ret=AuthorDetail.objects.filter(author__name="alex").values("telephone")
# 查询lqz的手机号
# 正向查
ret=Author.objects.filter(name='lqz').values('author_detail__telephone')
print(ret)
# 反向查
ret= AuthorDatail.objects.filter(author__name='lqz').values('telephone')
print(ret)
进阶练习(连续跨表)
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects.filter(publish__name="人民出版社")values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects.filter(name="人民出版社").values_list("book__title","book__authors__age","book__authors__name")
# 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
# 方式1:
queryResult=Book.objects.filter(authors__authorDetail__telephone__regex="151")
.values_list("title","publish__name")
# 方式2:
ret=Author.objects.filter(authordetail__telephone__startswith="151").values("book__title","book__publish__name")
# ----进阶练习,连续跨表
# 查询手机号以33开头的作者出版过的书籍名称以及书籍出版社名称
# author_datail author book publish
# 基于authorDatail表
ret=AuthorDatail.objects.filter(telephone__startswith='33').values('author__book__name','author__book__publish__name')
print(ret)
# 基于Author表
ret=Author.objects.filter(author_detail__telephone__startswith=33).values('book__name','book__publish__name')
print(ret)
# 基于Book表
ret=Book.objects.filter(authors__author_detail__telephone__startswith='33').values('name','publish__name')
print(ret)
# 基于Publish表
ret=Publish.objects.filter(book__authors__author_detail__telephone__startswith='33').values('book__name','name')
print(ret)
related_name
publish = ForeignKey(Blog, related_name='bookList')
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")

