【CV论文阅读】Detecting events and key actors in multi-person videos
论文主要介绍一种多人协作的视频事件识别的方法,使用attention模型+RNN网络,最近粗浅地学习了RNN网络,它比较适合用于处理序列的存在上下文作用的数据。
NCAA Basketball数据集
这个数据集是作者新构建的,一个事件4秒长度,在论文中共需识别11个事件。而且从训练集子集通过标注人物的bounding box学习了一个multibox detector,来识别所有帧中的人物bounding box。
RNN模型
论文使用了RNN模型中的LSTM来处理帧序列。网络的结构如下图,其中BLSTM代表双向的LSTM结构
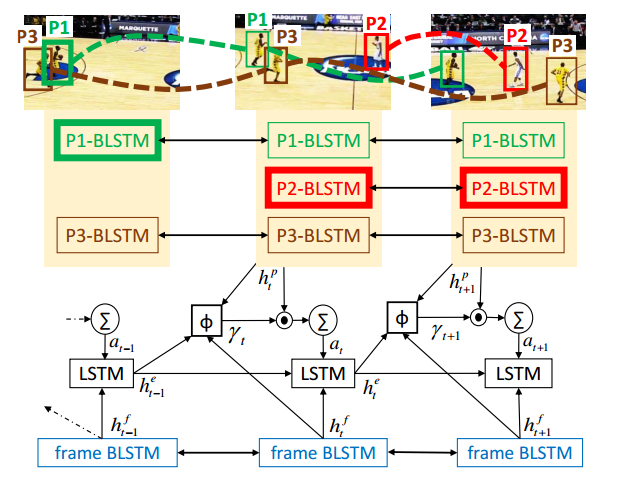
每个Pi-BLSTM跟踪每个人物帧序列中的状态,方框的厚度代表attention作为key人物的权值。
首先,每一帧提取1024维度的特征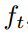 ,而对于每帧的每一个player,提取2805维特征(1440维位置spatial的信息以及1365维appearance信息)
,而对于每帧的每一个player,提取2805维特征(1440维位置spatial的信息以及1365维appearance信息)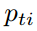 。首先使用BLSTM计算hidden state
。首先使用BLSTM计算hidden state 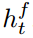 ,它保存了全局上下文的信息。计算式子如下
,它保存了全局上下文的信息。计算式子如下
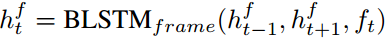
然后可以利用单向的LSTM计算事件状态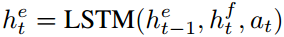
最后,对于每个事件k,都定义一个权向量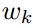 ,计算它们的内积
,计算它们的内积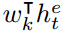 来确定事件的分类。误差函数可以定义:
来确定事件的分类。误差函数可以定义: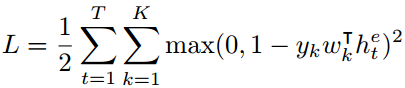
其中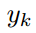 是对于视频原label,如果属于k则为1,否则为-1。
是对于视频原label,如果属于k则为1,否则为-1。
Attention 模型
Attention模型的主要作用在于识别主人物并增大他在计算event state中所起的作用,在这里会利用一个softmax函数来实现上述的功能。论文提出了两种思路,分别是对每个人物进行跟踪的模型以及不跟踪的模型。
跟踪模型
利用KTL tracker和图匹配找到每帧对应的人物,并为每个人物建立一个BLSTM网络,用于计算hidden state 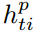 ,得
,得![]() 。计算softmax函数分配每个人物在每一帧的权重,从而识别关键人物,如下计算
。计算softmax函数分配每个人物在每一帧的权重,从而识别关键人物,如下计算
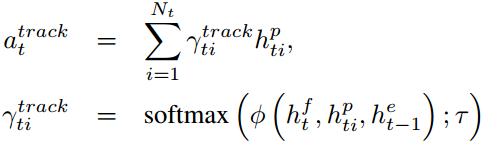
其中![]() 是一个多层感知机。
是一个多层感知机。
非跟踪模型
直接使用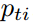 替代
替代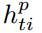 ,可以得到计算方法为
,可以得到计算方法为
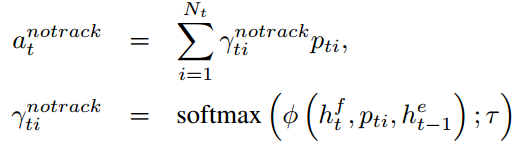

 浙公网安备 33010602011771号
浙公网安备 33010602011771号