【CV论文阅读】Going deeper with convolutions(GoogLeNet)
目的:
提升深度神经网络的性能。
一般方法带来的问题:
增加网络的深度与宽度。
带来两个问题:
(1)参数增加,数据不足的情况容易导致过拟合
(2)计算资源要求高,而且在训练过程中会使得很多参数趋向于0,浪费计算资源。
解决方法:
使用稀疏连接替代稠密结构。
理论依据(Arora):一个概率分布可以用一个大的稀疏的深度神经网络表示,最优的结构的构建通过分析上层的激活状态的统计相关性,并把输出高度相关的神经元聚合。这与生物学中Hebbian法则“有些神经元响应基本一致,即同时兴奋或抑制”一致。
存在问题:计算机的基础结构在遇到稀疏数据计算时会很不高效,使用稀疏矩阵会使得效率大大降低。
目标:设计一种既能利用稀疏性,又可以利用稠密计算的网络结构。
Inception 模型:
究竟模型中是怎样利用稀疏性的呢?我也说不清楚,但估计是在同一层利用了不同的核去对输入的feature进行卷积把,分散成几个小任务进行,然后再汇聚。如下图:
@2016/08/24 更新对稀疏性的理解
知乎上摘自 段石石的解答:
对的 channel的意思其实就是神经元的个数,这里降维的意思其实就是减少神经元的个数,比如原先的28*28*512 在1*1*256 之后 就是28*28*256(stride为1的情况), 这样在整个网络结构这一层就降维了,原作者发现在没有1*1之前的参数空间存在很多稀疏的数据,这里降维之后,参数空间会更dense,这样就解决了文章说的痛点(也就是稀疏性增大计算困难的问题)
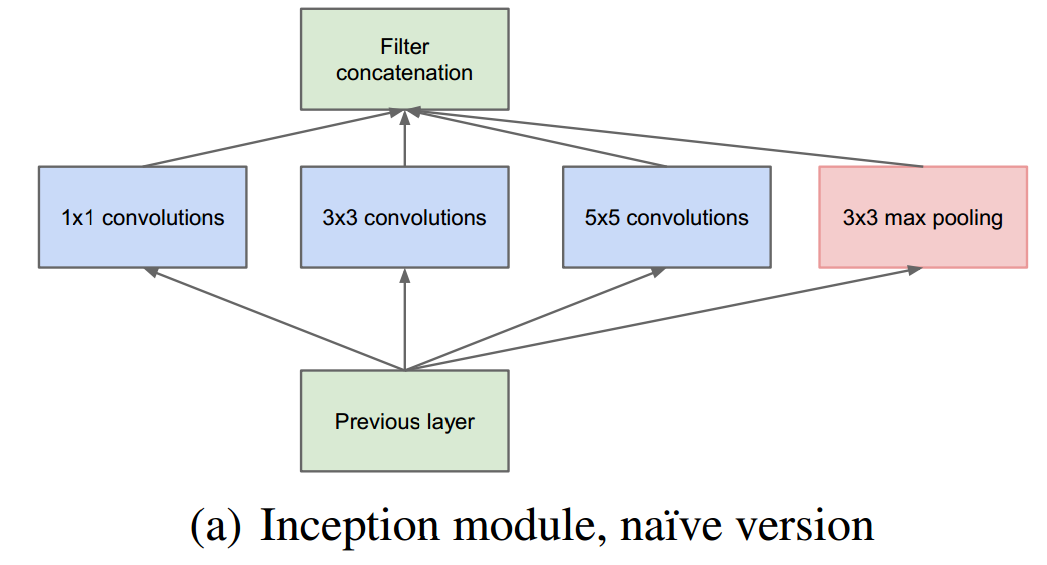
这是最原始的模型。可以看出,因为卷积并不一定就改变大小,而通道数目由于分散的连接最终会增加,这样很容易造成参数个数的指数级别的上升。论文中使用了NIN网络中提到的利用1*1卷积核降维的作用,在卷积层处理前,先对特征图层进行降维(注意是通道的降维,不是空间的降维),例如原本是M通道,降维到P通道后,在通过汇聚变成了M通道,这时参数的个数并没有随着深度的加深而指数级的增长,如下图:

这样做的合理性在于,Hebbin法则说的“有些神经元同时兴奋或抑制”,而在区域中同一节点对应的区域可能一样,认为它们是相关的,所以通过1*1的卷积核将它们聚合(信息压缩)后再卷积,符合Arora的理论。同时,注意到还有一个最大化池化层。
这样处理的好处是(1)深度增加,节点数目可控(2)出现多个尺度如3*3,1*1,5*5,7*7等。
GoogLeNet结构:
GoogLeNet网络有22层,最后一层使用了NIN网络中的全局平均池化层,但还是会加上FC层,再输入到softmax函数中。如下图:
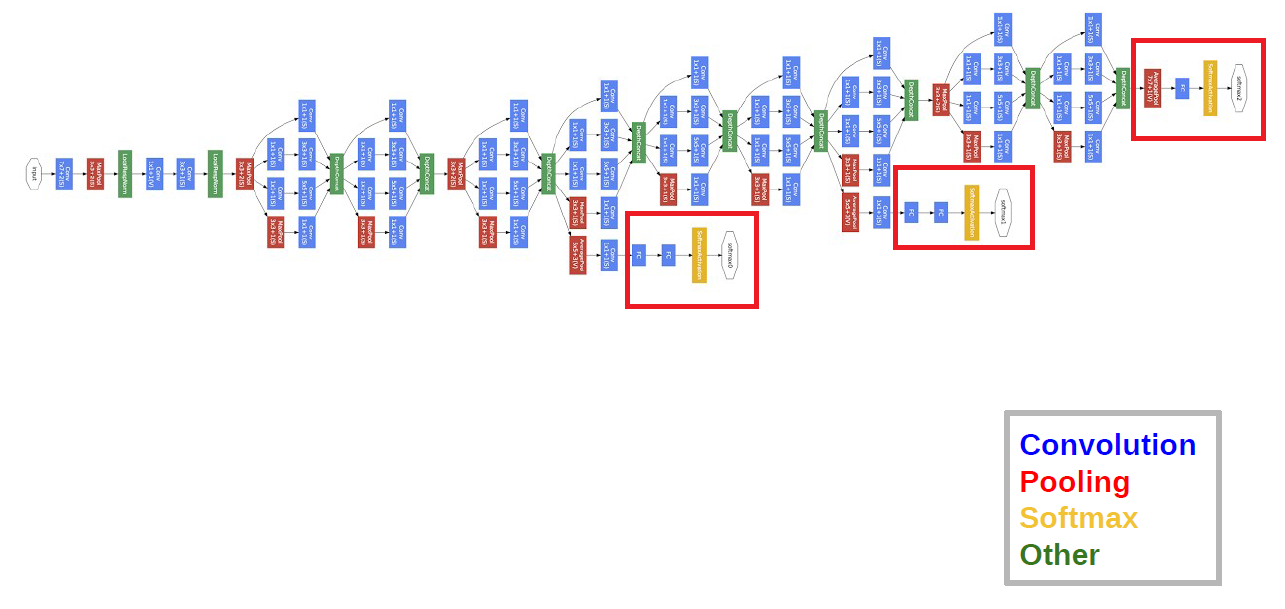
在深度加深的情况下,在BP算法执行时可能会使得某些梯度为0,这会使得网络的收敛变慢。论文中使用的方法是增加两个输出层(Auxiliary Classifiers),这样一些权值更新的梯度就会来自于多个部分的叠加,加速了网络的收敛。但预测时会吧AC层去掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号