Yarn Capacity Scheduler配置
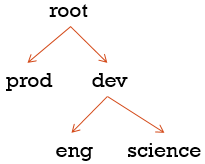
我们开辟出两个队列,一个是生产上需要的队列prod,一个是开发上需要的队列dev,开发下面又分了eng工程师和science科学家,我们这样就可以指定队列
- 1、关闭yarn, stop-yarn.sh
- 2、先备份$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml
cp capacity-scheduler.xml capacity-scheduler.xml_bak
rm capacity-scheduler.xml - 3、然后在这个配置中加上如下配置
vi capacity-scheduler.xml:
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>占比是百分比
- 4、然后进行同步:
scp capacity-scheduler.xml hadoop-twq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp capacity-scheduler.xml hadoop-twq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/ - 5、启动yarn, start-yarn.sh
-
6、通过WebUI查看配置是否成功

-
在DistributedCount.java中MapReduce程序指定队列运行
job.getConfiguration().set("mapreduce.job.queuename", "eng");
运行中通过WebUI可以查看运行过程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号