Master选举原理
为什么需要Zookeeper?
为了防止集群的主NameNode挂掉,再另创建一个辅NameNode,两个保持数据同步,一旦主NameNode挂掉,集群就会把辅NameNode节点作为整个集群的主NameNode,而在这之间就需要用到Zookeeper来协调,帮助辅NameNode成为整个集群的主NameNode。
在这里Zookeeper是实现的master选举机制完成这一过程,选举机制分两种:
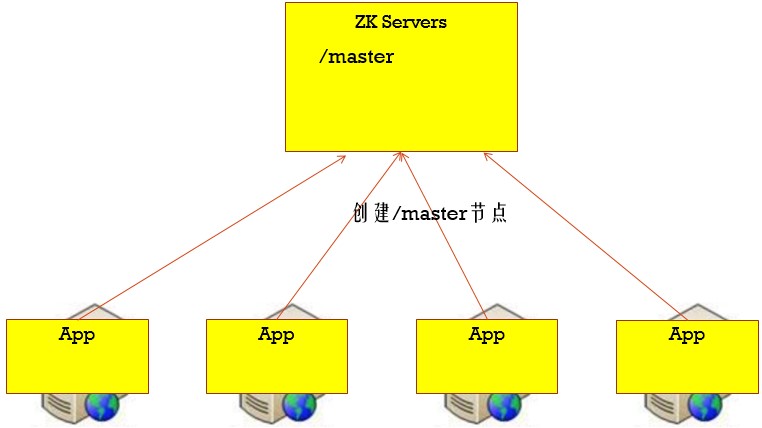
第一种:谁先创建master临时节点,谁就是master,当一个master挂掉了,master节点就消失了,别的节点就会监听到,就会继续去创建master临时节点,以此类推,利用Zookeeper的两个特点(一个节点只能成功创建一次、利用监听的机制)
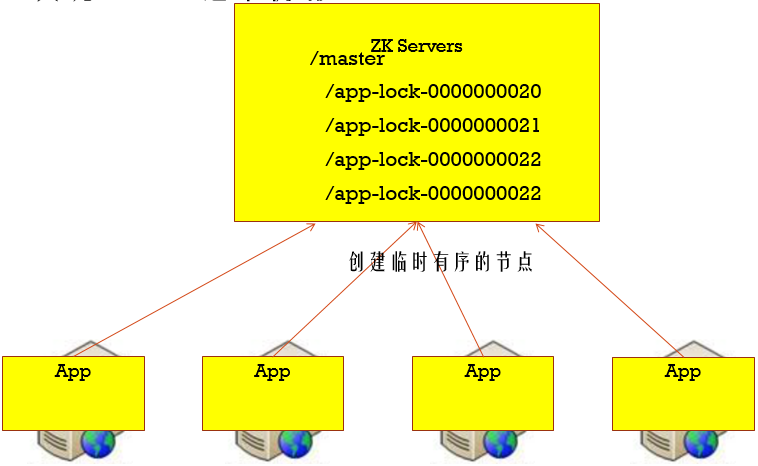
第二种:在master下面创建临时有序节点,那个节点最小,那个就是master,节点挂掉,下面那个临时节点就会监听到上面的临时节点挂掉了,从而取代成为master,以此类推,(利用Zookeeper创建节点临时有序的特性)
第二种master选举机制利用Curator的API写:LeaderSelectionApp.java
打包上传到各个节点运行:
java -cp zookeeper-course-1.0-SNAPSHOT-jar-with-dependencies.jar com.twq.zk.usage.LeaderSelectionApp
master、slave1、slave2轮流成为master
两种选举机制示意图:
第一种:
第二种:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号