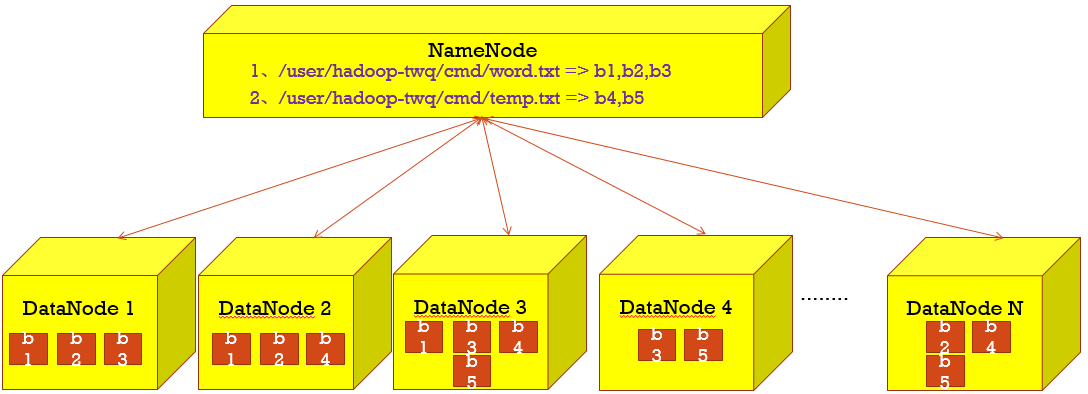
HDFS中的数据块
创建一个321M的big_file.txt文件:
写一个脚本:vi test.sh,内容:
#!/bin/bash
for((i=0;i<=$1;i++))
do
echo "just an example" >> big_file.txt
done执行脚本:bash test.sh 100(增加100行数据,直到文件大小到321M)
将321M的big_file.txt上传到hdfs文件系统中
hadoop fs -put big_file.txt /user/hadoop-twq/cmd
查看:
hadoop fs -ls -h /user/hadoop-twq/cmd
可以使用WebUI查看321M的文件分成了多少块,每一块分布在那一个节点上,
- ☛ 数据块的默认大小为: 128M
- ☛ 设置数据块的大小为: 256M*1024*1024,在${HADOOP_HOME}/etc/hadoop/hdfs-site.xml中加上配置:
<property>
<name>dfs.block.size</name>
<value>268435456</value>
</property>重启hdfs,这样重新打开WebUI,big_file.txt每一块大小仍不会变,因为即使修改了配置,而big_file.txt已经分好数据块了,需要再次上传一个副本big_file.txt(可以重命名:mv big_file.txt big_file_other.txt)到hdfs,这时候再看WebUI,就会按照上面配置的进行分块
- ☛ 数据块的默认备份数是3,如果直接修改文件中备份数,big_file.txt数据块备份数不会变,只有重新上传才会变,这时候就可以使用命令改变备份数:
hadoop fs -setrep 2 /users/hadoop-twq/cmd/big_file.txt - ☛ 数据块都是存储在每一个DataNode所在的机器本地磁盘文件中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号