
并行编程——内存模型之顺序一致性
1 定义
Sequential consistency , 简称 SC,定义如下
… the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program [lamport]
下面用一个小例子说明这个定义的意思:
假设我们有两个线程(线程1和线程2)分别运行在两个CPU上,有两个初始值为0的全局共享变量x和y,两个线程分别执行下面两条指令:
初始条件: x = y = 0;
表 1.1 CC 示意图
|
线程 1 |
线程 2 |
|
x = 1; |
y=1; |
|
r1 = y; |
r2 = x; |
因为多线程程序是交错执行的,所以程序可能有如下几种执行顺序:
表 1.2 CC示意图2
|
Execution 1 |
Execution 2 |
Execution 3 |
|
x = 1; r1 = y; y = 1; r2 = x; 结果:r1==0 and r2 == 1 |
y = 1; r2 = x; x = 1; r1 = y; 结果: r1 == 1 and r2 == 0 |
x = 1; y = 1; r1 = y; r2 = x; 结果: r1 == 1 and r2 == 1 |
|
Execution 1 |
Execution 2 |
Execution 3 |
当然上面三种情况并没包括所有可能的执行顺序,但是它们已经包括所有可能出现的结果了,所以我们只举上面三个例子。我们注意到这个程序只可能出现上面三种结果,但是不可能出现r1==0 and r2==0的情况。
SC其实就是规定了两件事情:
(1)每个线程内部的指令都是按照程序规定的顺序(program order)执行的(单个线程的视角)
(2)线程执行的交错顺序可以是任意的,但是所有线程所看见的整个程序的总体执行顺序都是一样的(整个程序的视角)
第一点很容易理解,就是说线程1里面的两条语句一定在该线程中一定是x=1先执行,r1=y后执行。第二点就是说线程1和线程2所看见的整个程序的执行顺序都是一样的,举例子就是假设线程1看见整个程序的执行顺序是我们上面例子中的Execution 1,那么线程2看见的整个程序的执行顺序也是Execution 1,不能是Execution 2或者Execution 3。
有一个更形象点的例子。伸出你的双手,掌心面向你,两个手分别代表两个线程,从食指到小拇指的四根手指头分别代表每个线程要依次执行的四条指令。SC的意思就是说:
(1)对每个手来说,它的四条指令的执行顺序必须是从食指执行到小拇指
(2)你两个手的八条指令(八根手指头)可以在满足(1)的条件下任意交错执行(例如可以是左1,左2,右1,右2,右3,左3,左4,右4,也可以是左1,左2,左3,左4,右1,右2,右3,右4,也可以是右1,右2,右3,左1,左2,右4,左3,左4)
其实说简单点,SC就是我们最容易理解的那个多线程程序执行顺序的模型。CC 保证的是对一个地址访问的一致性,SC保证的是对一系列地址访问的一致性。
2 几种顺序约束
顺序的内存一致性模型为我们提供了一种简单的并且直观的程序模型。但是,这种模型实际上阻止了硬件或者编译器对程序代码进行的大部分优化操作。为此,人们提出了很多松弛的(relaxed)内存顺序模型,给予处理器权利对内存的操作进行适当的调整。例如Alpha处理器,PowerPC处理器以及我们现在使用的x86, x64系列的处理器等等。下面是一些内存顺序模型
2.1 TSO (整体存储定序)
- 数据载入间的执行顺序不可改变。
- 数据存储间的顺序不可改变。
- 数据存储同相关的它之前的数据载入间的顺序不可改变。
- 数据载入同其相关的它之前的数据存储的顺序可以改变。
- 向同一个地址存储数据具有全局性的执行顺序。
- 原子操作按顺序执行。
- 这方面的例子包括x86 TSO26和SPARC TSO.
2.2 PSO (部分存储定序)
- 数据载入间的执行顺序不可改变。
- 数据存储间的执行顺序可以改变。
- 数据载入同数据存储间相对顺序可以改变。
- 向同一个地址存储数据具有全局性的执行顺序。
- 原子操作同数据存储间的顺序可以改变。
- 这方面的例子包括SPARC PSO.
2.3 RMO (宽松内存定序)
- 数据载入间的顺序可以改变。
- 数据载入同数据存储间的顺序可以改变。
- 数据存储间的顺序可以改变。
- 向同一个地址存储数据具有全局性的执行顺序。
- 原子操作同数据存储和数据载入间的顺序可以改变。
- 这方面的例子包括Power27和ARM.7
图 1 一些体系架构的内存顺序标准

图 2 强内存顺序模型和弱内存顺序模型一些例子,
最左边的内存顺序一致性约束越弱,右边的约束是在左边的基础上加上更多的约束,X86/64 算是比较强的约束。

3 乱序执行和内存屏障
任何非严格满足SC规定的内存顺序模型都产生所谓乱序执行问题,从编程人员的代码,到编译器,到CPU运行,中间可能至少需要对代码次序做三次调整,每一次调整都是为了最终执行的性能更高。如下图
图 3 编译乱序和运行乱序

在串行时代,编译器和CPU对代码所进行的乱序执行的优化对程序员都是封装好了的,无痛的,所以程序员不需要关心这些代码在执行时被乱序成什么样子。在单核多线程时代,mutex , semaphore 等机制在实现的时候考虑了编译和执行的乱序问题,可以保证关键代码区不会被乱序执行。在多核多线程时代,大部分情况下跟单核多线程是类似的,通过锁调用可以保证共享区执行的顺序性。但某种情况下,比如自己编写无锁程序,则会被暴露到这个问题面前。
下面通过一个例子解释乱序执行和内存屏障这两个概念。
[来源:http://preshing.com/20120625/memory-ordering-at-compile-time]
示例代码:
int A, B;
void foo()
{
A = B + 1;
B = 0;
}
普通编译选项:
$ gcc -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR _B (redo this at home...)
add eax, 1
mov DWORD PTR _A, eax
mov DWORD PTR _B, 0
加上 -o2 优化编译选项,可以看到,B的赋值操作顺序变了
$ gcc -O2 -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR B
mov DWORD PTR B, 0
add eax, 1
mov DWORD PTR A, eax
...
上述情况在某些场景下导致的后果是不可接受的,比如下面这段伪代码中,生产者线程执行于一个专门的处理器之上,它先生成一条消息,然后通过更新ready的值,向执行在另外一个处理器之上的消费者线程发送信号,由于乱序执行,这段代码在目前大部分平台上执行是有问题的:
处理器有可能会在将数据存储到message->value的动作执行完成之前和/或其它处理器能够看到message->value的值之前,执行consume函数对消息进行接收或者执行将数据保存到ready的动作。
图 4 乱序执行

回到之前的例子,加上一句内存屏障命令
int A, B;
void foo()
{
A = B + 1;
asm volatile("" ::: "memory");
B = 0;
}
依然采用 o2 优化编译选项,发现这次B的赋值操作顺序没有变化
$ gcc -O2 -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR _B
add eax, 1
mov DWORD PTR _A, eax
mov DWORD PTR _B, 0
...
在内存顺序一致性模型不够强的多核平台上,例子2的正确实现应该是下面这种,需要加上两个内存屏障语句。
图5 内存屏障
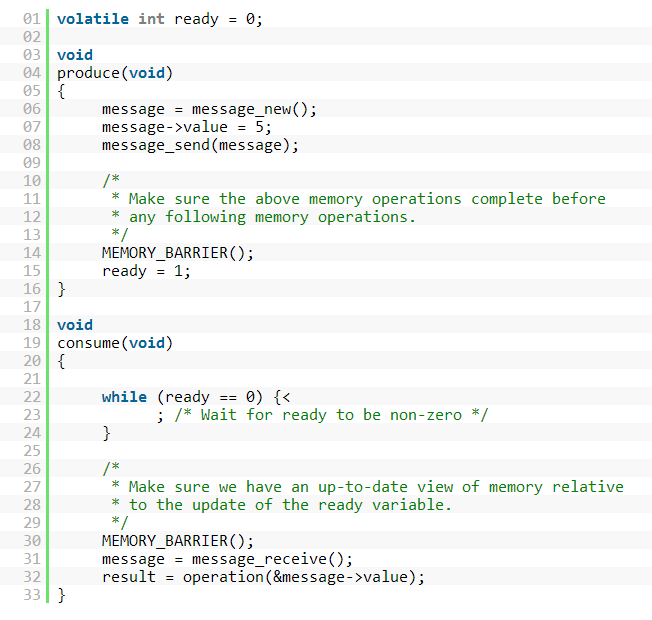
X86 的内存屏障 #define barrier() __asm__ __volatile__("": : :"memory")
更多X86内存屏障请参考 : http://blog.csdn.net/cnctloveyu/article/details/5486339

 浙公网安备 33010602011771号
浙公网安备 33010602011771号