NJU-ICS 2024学习随笔PA1_2(正则表达式)
2024-09-22
确实这一块比前面有点难了,先看看这make_token函数在哪。
在nemu目录下执行指令grep -r "make_token",就可以得到这个函数所在路径。
然后看到enum和rule,结合文章可知,这里就是添加规则的地方。
先学一下正则表达式语法
正则表达式语法
.:匹配任意字符(除了换行符)*:匹配前一个字符零次或多次+:匹配前一个字符一次或多次?:匹配前一个字符零次或一次^:匹配字符串开头$:匹配字符串结尾[]:匹配括号内任意字符():创建一个捕获组\\:一个 \ 是转义字符,两个 \ 是表示匹配后面紧跟的字符
enum里面更改为
enum
{
TK_NOTYPE = 0, // " "
TK_EQ = 1, // ==
/* TODO: Add more token types */
TK_LEFT = 2, // (
TK_RIGHT = 3, // )
TK_PLUS = 4, // +
TK_MINUS = 5, // -
TK_MUL = 6, // *
TK_DIV = 7, // /
TK_AND = 8, // &&
TK_OR = 9, // ||
TK_XOR = 10, // ^
TK_AR = 11, // access register
TK_NUM = 12, // number
TK_HEX = 13, // hexadecimal
TK_NOTEQ = 14, // not equal
TK_LEQ = 15, // less equal
TK_GEQ = 16 // less equal
};rule里面更改为
rules的代码
static struct rule {
const char *regex;
int token_type;
} rules[] = {
/* TODO: Add more rules.
* Pay attention to the precedence level of different rules.
*/
{" +", TK_NOTYPE}, // spaces
{"==", TK_EQ}, // equal
{"\\(", TK_LEFT}, // left bracket
{"\\)", TK_RIGHT}, // right bracket
{"\\+", TK_PLUS}, // plus
{"\\-", TK_MINUS}, // minus
{"\\*", TK_MUL}, // multiply
{"\\/", TK_DIV}, // divide
{"\\&\\&", TK_AND}, // and
{"\\|\\|", TK_OR}, // or
{"\\^", TK_XOR}, // xor
{"\\$[a-z]*[0-9]*", TK_AR}, // access register
{"0[xX][0-9a-fA-F]+", TK_HEX}, // hexadecimal
{"[0-9]+", TK_NUM}, // number
{"!=", TK_NOTEQ}, // not equal
{"<=", TK_LEQ}, // less equal
{">=", TK_GEQ}, // greater equal
};这里解释一下关于访问寄存器部分。可以找到nemu/src/isa/riscv32/reg.c这里关于寄存器的命名。除了一个$0其余都符合一个字符+一个数字的命名方式,所以就这样写了。
剩下一个存token的地方明天再说吧,不早了,得睡觉了。反正后面都得测试,现在对不对也问题不大
2024-09-24
make_token
make_token的代码
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
while (e[position] != '\0') {
// printf("position:%d e:%c nr_regex:%d\n", position, e[position], NR_REGEX);
/* Try all rules one by one. */
for (i = 0; i < NR_REGEX; i ++) {
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s",
i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
switch (rules[i].token_type) {
case TK_NOTYPE:
break;
/*
+-*\, and so on
*/
case TK_EQ:
strcpy(tokens[nr_token].str, "=");
tokens[nr_token ++].type = TK_EQ;
break;
case TK_LEFT:
strcpy(tokens[nr_token].str, "(");
tokens[nr_token ++].type = TK_LEFT;
break;
case TK_RIGHT:
strcpy(tokens[nr_token].str, ")");
tokens[nr_token ++].type = TK_RIGHT;
break;
case TK_PLUS:
strcpy(tokens[nr_token].str, "+");
tokens[nr_token ++].type = TK_PLUS;
break;
case TK_MINUS:
strcpy(tokens[nr_token].str, "-");
tokens[nr_token ++].type = TK_MINUS;
break;
case TK_MUL:
strcpy(tokens[nr_token].str, "*");
tokens[nr_token ++].type = TK_MUL;
break;
case TK_DIV:
strcpy(tokens[nr_token].str, "/");
tokens[nr_token ++].type = TK_DIV;
break;
/*
&& || ^
*/
case TK_AND:
tokens[nr_token].type = TK_AR;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
case TK_OR:
tokens[nr_token].type = TK_AR;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
case TK_XOR:
tokens[nr_token].type = TK_AR;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
/*
register, number, hexadecimal
*/
case TK_AR:
tokens[nr_token].type = TK_AR;
strncpy(tokens[nr_token ++].str, &e[position - substr_len], substr_len);
break;
case TK_NUM:
tokens[nr_token].type = TK_NUM;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
case TK_HEX:
tokens[nr_token].type = TK_HEX;
strncpy(tokens[nr_token ++].str, &e[position - substr_len], substr_len);
break;
case TK_NOTEQ:
tokens[nr_token].type = TK_HEX;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
case TK_LEQ:
tokens[nr_token].type = TK_HEX;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
case TK_GEQ:
tokens[nr_token].type = TK_HEX;
strncpy(tokens[nr_token++].str, &e[position - substr_len], substr_len);
break;
default:
printf("undefined character in position %d\n", position);
break;
}
break;
}
}
if (i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}今天写了写这里面的东西,然后继续看了看接下来要干啥。
看起来是要写递归求值的事情了。基本思路就是用+-*\来分割式子然后递归求值。应该不难写,明天再写吧,今天歇了。
考研吐槽部分:为什么数据结构的代码都是指针来指针去,空间还要malloc,这也不能用那也不能用。束手束脚的,明天研究研究代码,整理一份好用的出来。
2024-09-27
eval(p, q)
u_int32_t eval(u_int32_t p, u_int32_t q, u_int32_t flag) {
while (tokens[p].type == TK_NOTYPE) p ++;
while (tokens[q].type == TK_NOTYPE) q --;
if (p > q) {
/* Bad expression */
assert(0);
}
else if (p == q) {
/* Single token.
* For now this token should be a number.
* Return the value of the number.
*/
// Number
if(tokens[p].type == TK_NUM){
return atoi(tokens[p].str);
}
// Hexadecimal
else if(tokens[p].type == TK_HEX){
int num;
sscanf(tokens[p].str, "%x", &num);
return num;
}
else if(tokens[p].type == TK_AR){
bool flag = 1;
int num = isa_reg_str2val(tokens[p].str, &flag);
if(flag) return num;
else{
printf("Cannot get the number in %s\n", tokens[p].str);
assert(0);
}
}
return 0;
}
else if (check_parentheses(p, q) == 1) {
/* The expression is surrounded by a matched pair of parentheses.
* If that is the case, just throw away the parentheses.
*/
return eval(p + 1, q - 1, 0);
}
else {
//op = the position of primary operator in the token expression;
u_int32_t op = get_position(p, q);
u_int32_t op_type = tokens[op].type;
u_int32_t val1 = eval(p, op - 1, flag);
u_int32_t val2;
if(op_type == TK_MINUS)
val2 = eval(op + 1, q, flag ^ 1);
else
val2 = eval(op + 1, q, flag);
// printf("val1:%d val2:%d flag:%d str:%s\n", val1, val2, flag, tokens[op].str);
switch (op_type) {
// +
case TK_PLUS:
if(flag)
return val1 - val2;
else return val1 + val2;
// -
case TK_MINUS:
if (flag)
return val1 + val2;
else return val1 - val2;
// *
case TK_MUL: return val1 * val2;
// /
case TK_DIV:
if(val2 == 0){
printf("Division by 0 at %d", op);
assert(0);
}
return val1 / val2;
default:
printf("Unkonwn type at %d", op);
assert(0);
}
}
}算法逻辑讲解:
首先,正则表达式的分割相当于:如何把表达式分割成一个树。
那么满足:深度越深,计算的优先级越高。
正则表达式分割可以视为一个dfs的行为。每一个子树相当于一个带括号的式子;每一个有儿子节点的点,必定是计算符号;每一个叶子节点,必定是一个独立的值。
因为这是一个dfs行为,所以我优先会搜到叶节点,才会进行计算,然后一步步往上回溯。
所以4 + 3 * ( 2 - 1 )形成的树如下:
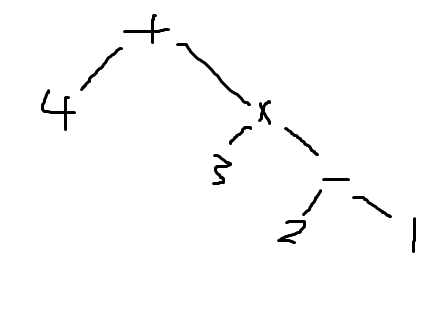
p > q:左指针大于右指针了肯定就有问题了,assert以下就可以p = q:左指针和右指针相等,就是同时指到一个 token,这样的话就是一个独立的数字(10进制或者16进制)( ):左右括号就直接跳过就可以了- :寻找计算符号,把表达式继续分割
check_parentheses(p, q)
u_int32_t get_position(u_int32_t p, u_int32_t q){
int op = p;
for(int i = p; i <= q; i ++){
//Check that the parentheses match
if(tokens[i].type == TK_LEFT){
while(tokens[i].type != TK_RIGHT && i < q)
i ++;
if(tokens[i].type != TK_RIGHT){
printf("Parentheses mismatch from %d to %d", p, q);
assert(0);
}
}
//
else if(tokens[i].type == TK_PLUS || tokens[i].type == TK_MINUS){
return i;
}
else if(tokens[i].type == TK_MUL || tokens[i].type == TK_DIV){
op = i;
}
}
assert(op != p);
return op;
}算法思想:枚举每一个 token
- 把 ( ) 内的表达式是为一个 token 并跳过。记得判断 ( ) 是否合法。
- 从左到右找一个 + 或 -。直接返回该 token 的坐标就可以。
- 从左到右找一个 * 或 /。记录,但是不返回,因为计算机不知道后面会不会有一个 + 或者 -。
注意:我是利用初始化op = p,然后判断循环后 op 是否修改。因为 p 的位置的 token 不可能是个计算符号,所以 assert(op != p)。
想了想,我前面写的那些东西,什么异或啊啥啥的,短时间内我应该用不到。就像前文说的,先跑起来。我现在还没跑起来呢。
明天继续写。
腿拉伤好多了,太久没运动,长时间低头学习颈椎就疼,明天应该可以慢跑试试,先慢跑个两公里试试水,然后慢慢恢复。希望能赶上足球联赛。
考研啊。今天看到thu和pku什么的都在改408,还有很多奇奇怪怪的专业考408。目前我考的学校倒是说不改考,但是我突然开始焦虑了。我们学院一年考不上几个985,我又何德何能呢。
我也不知道,或许呢,万一呢。我希望我一战考上。
2024-09-27 (纯吐槽部分
2024-09-29 这段别看了,弱智了
这个gen-expr的部分很难写啊,为什么网上搜到的没有写的很对的。
要么直接通过增加模数的方式减少出现类似[num](expr)、(expr)[num]、[num][num]或者(expr)(expr) 这种情况。但是这是不对的。
正常情况应该是[num] op (expr)。
我在尝试在[num]和(expr)中间增加一个op,但是目前还没很好的想法(我不知道是我写错了什么,他不识别 buf 的前一个字符)
明天再说吧。或者过两天再说。
2024-09-28
我好像知道我为什么不识别了:
- 下标记错了。我常用
++id,因为数组从1开始比较符合习惯,所以这里id++就很容易忘了。 - 我当时想通过限制
buf_id来限制buf的大小,这样就容易一个表达式还没构造完就结束构造了,就会出现(-)的情况
gen-expr.c
那么关于这个部分,我就按照执行顺序来讲解我的代码思路。
main
static int buf_id;
int main(int argc, char *argv[]) {
/*
Original code
*/
for (i = 0; i < loop; i ++) {
printf("Test %d:\n", i);
/*
Original code
*/
//Reset buf_id and buf
buf_id = 0;
memset(buf, 0, sizeof buf);
}
return 0;
}这里我没有从代码里面找到关于下标的部分的变量,所以我定义了一个全局变量buf_id来表示当前字符插入的位置以及buf大小
记得每次运行完,要清空数组,以及重置下标。防止构造下一个表达式的时候会有没有被覆盖掉的内容,以及防止下一个表达式是构造在上一个表达式的基础上的
增加了一个输出test id的部分,方便从终端debug
gen_rand_expr
static void gen(char ch){
buf[buf_id ++] = ch;
}
static void gen_rand_expr() {
//When the buf_id is greater than 65530, kill it
if(buf_id > 65530){
assert(0);
}
switch (choose(3)) {
case 0: gen_num(); break;
case 1:
gen('(');
gen_rand_expr();
/*Control the size of regular expressions*/
// if(buf_id <= 10)
// gen_rand_expr();
// else gen_num();
gen(')'); break;
default:
gen_rand_expr(); gen_rand_op(); gen_rand_expr(); break;
}
}增加了一个表达式太大的时候的assert
如果你想减少buf的长度,可以把case1的注释的部分搬出来,然后把原来的gen_rand_expr注释掉
choose
static int choose(int n){
int num = rand() % n;
// Prevent the situation: [num](expr) or [num](expr)
// printf("Now the number is %d\n", num);
// printf("Now the buffer is %s\n", buf);
return num;
}直接简单的return就可以。
关于为什么我前文讨论的事情不会发生,我这里简述以下:
显然,[num]肯定是一个合法的表达式。
expr只有以下几种形式
[num](expr)expr op expr
假设存在expr0不合法,即存在构造其形式的(expr1)或者expr2 op expr3不合法,而根据代码可知,expr可看作一棵树,而其叶子节点可且仅可以是[num]。
也就是说([num])或者[num] op [num]不合法。
所以存在[num]不合法。显然不对。
所以所有构造的expr均合法。
关于为什么我后面没有用gen()来添加字符:其实我刚刚才想起来我还写了这个函数
gen_num
static void gen_num(){
int num = rand() % 100;
// printf("The number in gen_num is %d\n", num);
char str[3];
int id = 0;
if(num == 0){
buf[buf_id ++] = '0';
return;
}
//Calculate the length of num
int num_sz = 0, x = 1;
while(x <= num){
num_sz ++;
x *= 10;
}
num_sz --;
x /= 10;
while(num){
buf[buf_id ++] = num / x + '0';
str[id ++] = num / x + '0';
num %= x;
x /= 10;
}
// printf("The str in gen_num is %s\n\n", str);
return;
}这一段没啥好说的,就是一个数字转字符串存储的语法题。
itoa()函数好像可以整型转字符串,抽空可以试试。
gen_rand_op
static void gen_rand_op(){
char expr[4] = {'+', '-', '*', '/'};
int id = rand() % 4;
buf[buf_id ++] = expr[id];
// printf("Now the op is %c\n\n", expr[id]);
return;
}这也没啥好说的。
讲一讲如何验证计算是否正确:
可以用 python 复制你在终端输出的expr然后再.py中print(expr)
当然,结果可能和你的不一样,因为有精度和舍入问题,但是误差不那么离谱就问题不大。
睡了睡了。
今天去运维社团做了根网线,上午就没咋学。因为不太会用那个剪线的工具,一直剪断里面的细线,就得剪了重新剪。导致我3m的线最后还剩2m多点。只能说还好能够到网口,再短10cm估计就够不到了。
2024-09-29
今天继续写bug。
首先修改了前面的部分代码,有点问题,主要集中在rules的定义和maketoken中position++。
在src/monitor/sdb/sdb.c中添加以下语句(你知道每句话要添加到哪里,因为之前讲过
cmd_test_expr
cmd_test_expr的代码
static int cmd_test_expr(char *argc);
static struct {
/*
origin code
*/
{ "test", "Test the function expr", cmd_test_expr}
};
static int cmd_test_expr(char *argc){
/*Compile gen-expr.c file*/
int sys_call = system("gcc -o tools/gen-expr/test tools/gen-expr/gen-expr.c");
if(sys_call != 0) return 1;
/*Get the results of the run and enter them into the input file*/
int tot = 5;
char command[100];
sprintf(command, "./tools/gen-expr/test %d > tools/gen-expr/input", tot);
// printf("%s\n", command);
sys_call = system(command);
FILE *input_file = fopen("tools/gen-expr/input", "r");
if(input_file == NULL){
printf("Cannot open input file\n");
return 0;
}
char record[65536];
int eq_num = 0;// The number of equal results
for(int i = 0; i < tot; i ++){
if(fgets(record, sizeof(record), input_file) == NULL){
printf("Cannot read input file test %d\n", i);
continue;
}
char *token = strtok(record, " ");
if(token == NULL){
printf("Invalid pattern\n");
continue;
}
uint32_t val = atoi(token);
token = strtok(NULL, "\n");
printf("%u\n%s\n\n", val, token);
bool flag = 0;
uint32_t res = expr(token, &flag);
if(res == val)
eq_num ++;
}
printf("The correct rate is %d/%d\n", eq_num, tot);
fclose(input_file);
return 1;
}这样就可以做到,启动系统后,输入test一键编译并运行gen-expr.c了,而且还可以自动和expr函数对答案
关于expr的计算部分,明天今天再写。
我今天才知道github如果不设置pa1为默认分支是会点亮绿灯的,前几天的绿灯都没有了,好伤心。
2024-10-02
woc,前面的代码问题不小,但是我现在改完了。
所以好消息是,明天今天再改前面的内容。
2024-10-07
回家了一趟,然后修了两天bug,现在应该是没什么问题了,可以继续推进了。
前面的代码已更新。
现在测试一下寄存器的识别和解引用
测试完了,基本算是完了,能用只能说
expr
word_t expr(char *e, bool *success) {
nr_token = 0;
*success = 1;
memset(tokens, 0, sizeof(tokens));
if (!make_token(e)) {
*success = false;
return 0;
}
/* TODO: Insert codes to evaluate the expression. */
init();
u_int32_t ans = eval(0, nr_token - 1, 0);
// printf("ans:%u\n\n", ans);
return ans;
}init
void init(){
//Get the number in regesters
for(int i = 0; i < nr_token; i ++){
if(tokens[i].type == TK_MUL
&& (i == 0
|| (tokens[i - 1].type != TK_NUM && tokens[i - 1].type != TK_RIGHT))){
// *()
int p = i + 1, q = p;
int para = 1;
for(int j = i + 2; j < nr_token; j ++){
if(tokens[j].type == TK_RIGHT)
para --;
if(para == 0){
q = j;
break;
}
}
u_int32_t num = eval(p, q, 0);
u_int32_t val = vaddr_read(num, 4);
tokens[i].type = TK_NUM;
// printf("num:%d val:%d\n", (int)num, val);
sprintf(tokens[i].str, "%u", val);
for (int j = p; j <= q; j++)
tokens[j].type = TK_NOTYPE;
}
}
//Handing negative numbers
for(int i = 0; i < nr_token; i ++){
if(tokens[i].type == TK_MINUS
&& (i == 0
|| (tokens[i - 1].type != TK_NUM && tokens[i - 1].type != TK_RIGHT))){
// (+-*/)-[num]
u_int32_t num = eval(i + 1, i + 1, 0);
tokens[i + 1].type = TK_NOTYPE;
tokens[i].type = TK_NUM;
// printf("num:%u\n", num);
sprintf(tokens[i].str, "%u", -num);
}
}
}好像就没什么了,目前测试的部分都还可以,其他情况遇到了再改。
结束,背单词去。
明天再写后面的监视点。

