transformer
感觉现在对transfomer的定义是什么有的地方说法不太一致。 1.有的时候指的是 Attention Is All You Need 里面包括encoder-decoder在内的整个模型(这个时候一般多用于跟这篇文章中的模型结构进行比较,最新的一般只用本文模型中的encoder或者decoder中的一个)。2.有的时候指的是利用self-attention进行信息抽取的这种方法(目前还是这种说法占大多数,这种说法偏向于指特征抽取器,跟LSTM,CNN等进行对比的)。
但是无论怎么讲,transfomer的核心都是指利用self-attention来进行特征抽取的这种方法。其他的地方每个模型可能大大小小会有一些细节的差异。
注:本文中的transfomer指的是Attention Is All You Need这篇paper中encoder-cecoder整体模型
Transofomer 模型整体架构
Transofomer 模型整体架构是一个encoder-decoder架构,如下:
与传统encoder-decoder架构一样,先由encoder部分对信息进行编码,然后decoder利用这些编码后的信息进行解码。
可以看到左边整体encoders是由一个个小的encoder模块堆叠而成,右边的decoders也是这样。
Encoder 模块
每个encoder模块如图2所示,由一个自注意力层和一个前馈层组成。
假设encoder模块的输入有三个token,那么encoder中数据流动情况:
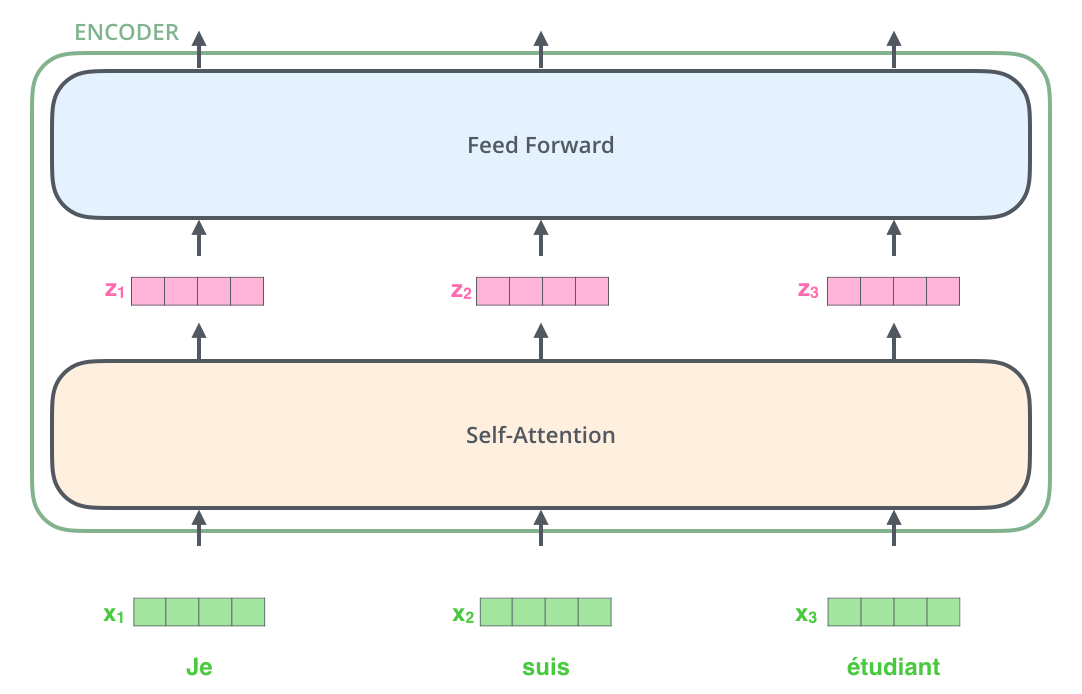
1.self-attention
transfomer模型里面最重要的部分就是self-attention,并且这篇paper最大的贡献也是提出了self-attention这种方法。下面对self-attention进行重点的讲解。
传统attention的计算
所谓的attention就是对于q、k、v三个向量,q为query,k为key,v是value。q一般是decoder中某个时间步的隐向量,k,v一般都是encoder的输出向量。先由q和每个k计算出一个score,然后做归一化,即为encoder中每个时间步的权重,然后将每个权重与对应的v相乘然后求和得到上下文向量。
由attention的到的上下文向量会随着decoder每个时间步隐向量的不同而不同,让其对encoder中的每个时间步的内容有不同的关注。
self-attention
self-attention的计算也整体框架也是这样,由q、k、v计算得来。区别就出在self上。self-attention的q、k、v都来自与自身,这使得输入的句子中的每个token可以关注到句子中的其他的token。
具体计算
self-attention里面某个token的q、k、v向量都是这个token的表示向量乘一个转换矩阵而得到的。
之所以会经过一个矩阵转换的原因:1.增加参数数量,增加模型的学习能力 2.将token映射到另一个空间 3.如果都采用他们自身的话,则q,k,v 都会是他自己。可能会出现下面的这个问题:假设token的embedding是一维的,一个句子是:2,2,3,44 则会造成无论对于哪个token来讲与44这个token的score都会是最大的,也就是说会造成token的embed ing值越大则它的权重就会越大导致强者恒强,越来越强。
-
计算 q,k,v
如下图:
, ,同理。
-
计算 z
这里计算score用的是点积的方法。
除以是进行缩放,防止score之间的差距过大。因为下一步要根据score经过sofmax计算权重,如果差距过大会造成权重过多的集中到某一个token上。
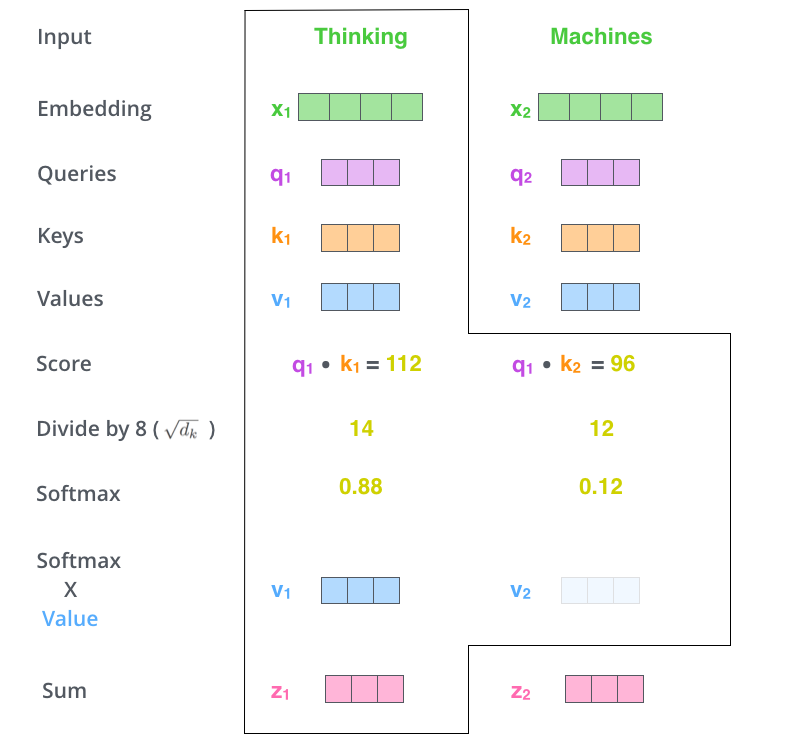
-
把向量运算转为矩阵运算形式
上面都是用向量的形式进行运算,虽然好理解但是速度慢,转为矩阵运算可以更好的利用gpu进行加速
首先是经过转换矩阵的映射:
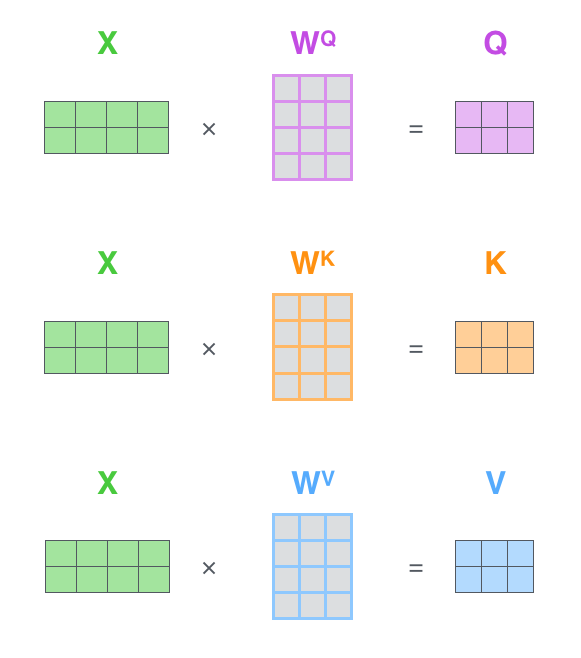
然后把Z的计算由向量运算转为矩阵运算:
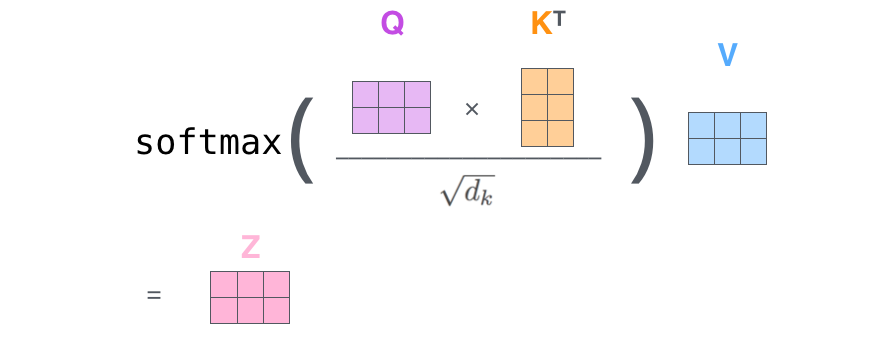
2. multi-head self-attention
multi-head self-attention 有点类似于多卷积核的感觉。一是可以用来增加参数增加模型表达能力 二是可以用来捕捉不同类型的特征。
每个head里面都有一组不同的,可以增加模型的参数,并且不同的转换矩阵捕获的特征也不尽相同,这样各异捕获更多的特征。
3. encoder的输入
4 层与层残差连接
encoder中经过self-attention层与前向层之后都有一个残差链接和layer norm,可以让模型可以让encoder模块堆叠的数量更大。
Decoder 模块
Decoder模块相对于encoder模快多了个encoder-decoder attention 层(位于self-attention层和feed-forward层之间),其余结构相同,也是有残差链接和normalize
encoder-decoder attention 用的还是跟self-attention相同的算法,只不过是来自decoder,k,v来自encoder,所以叫做encoder-decoder attention
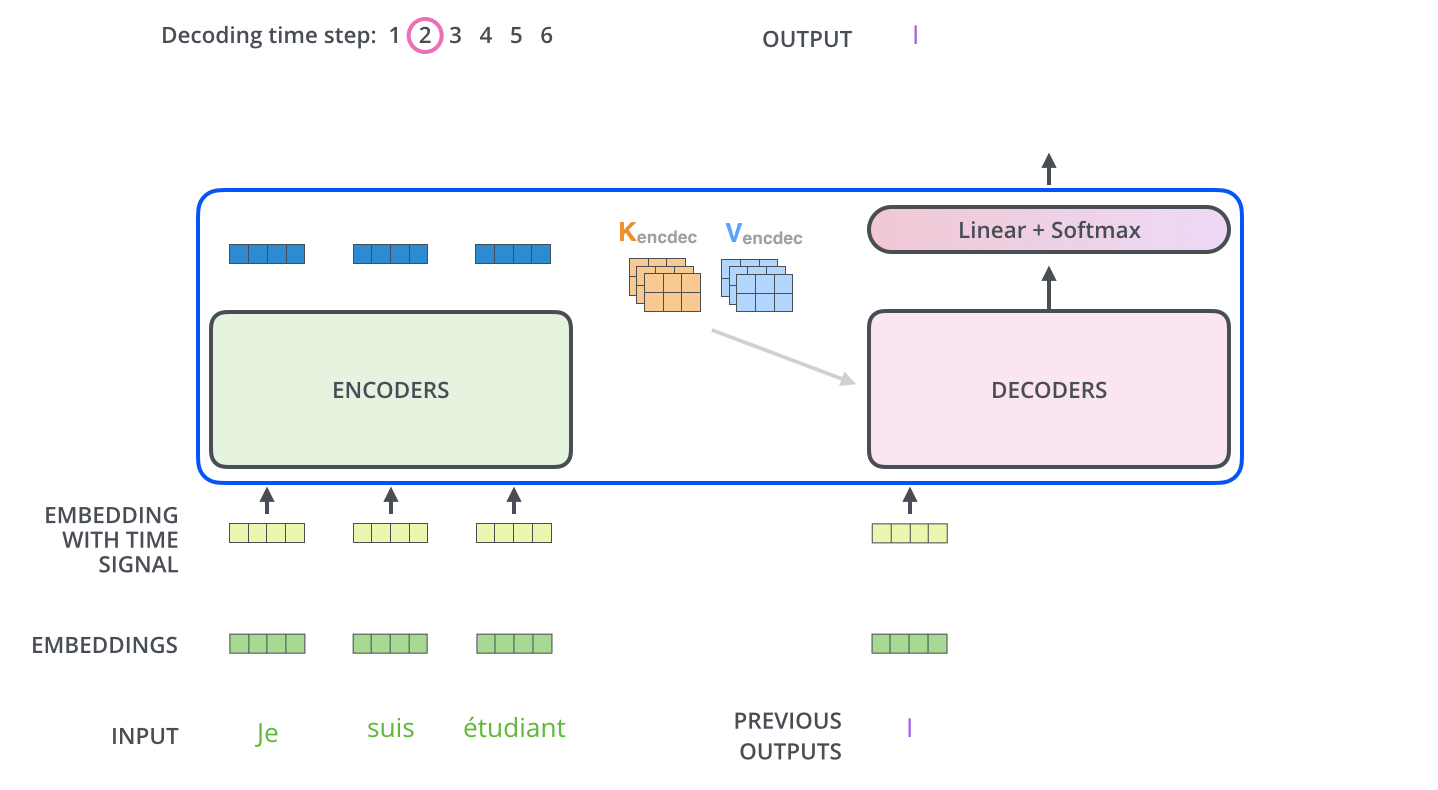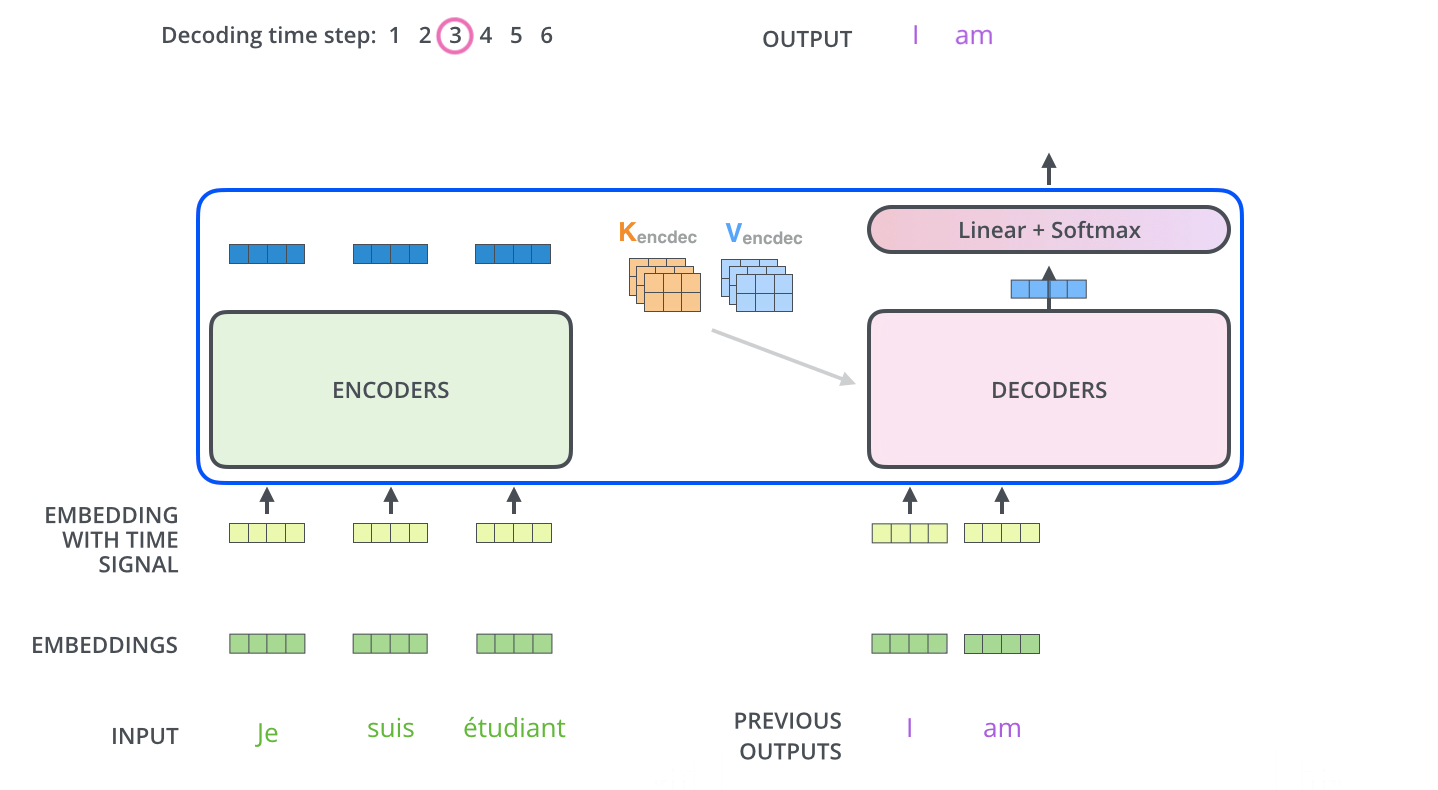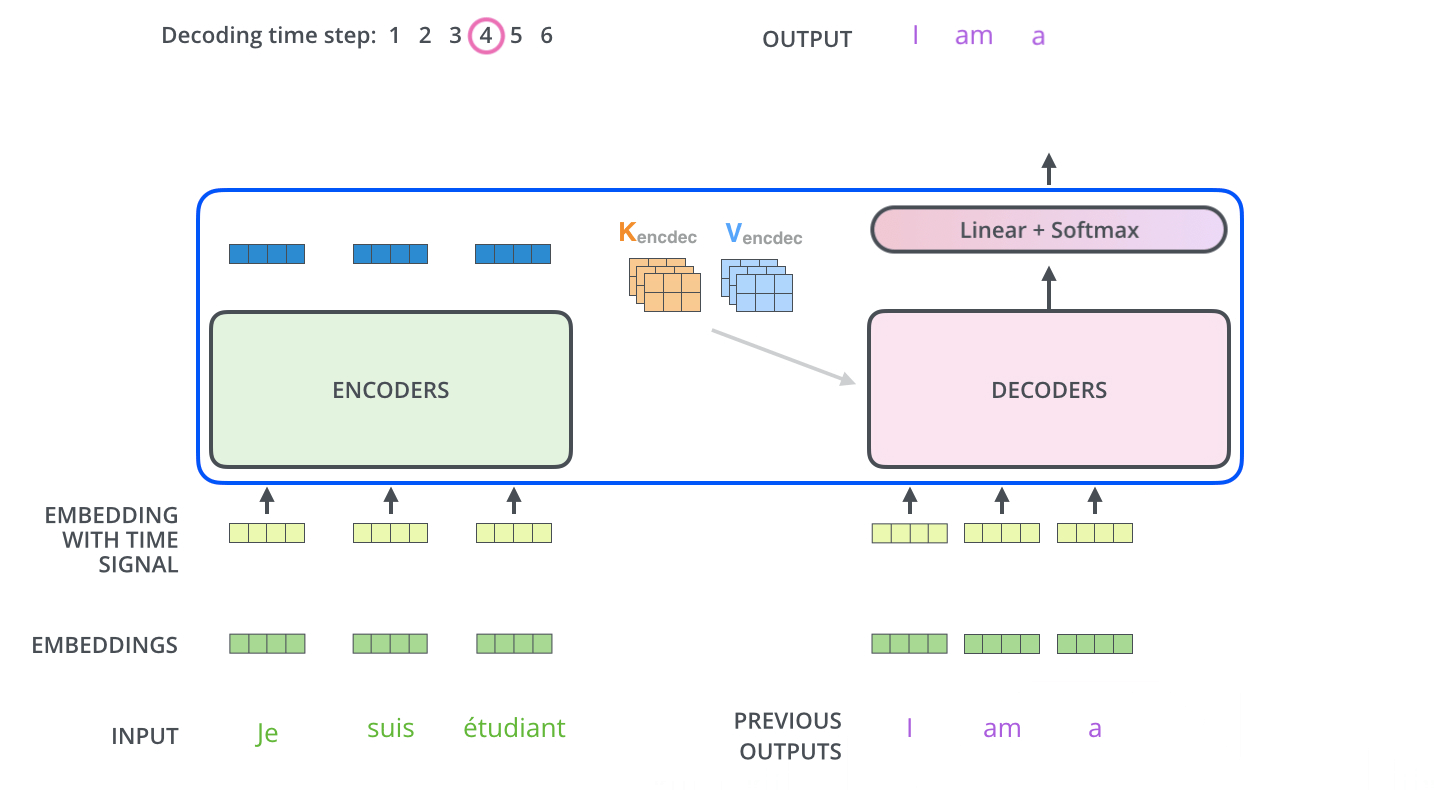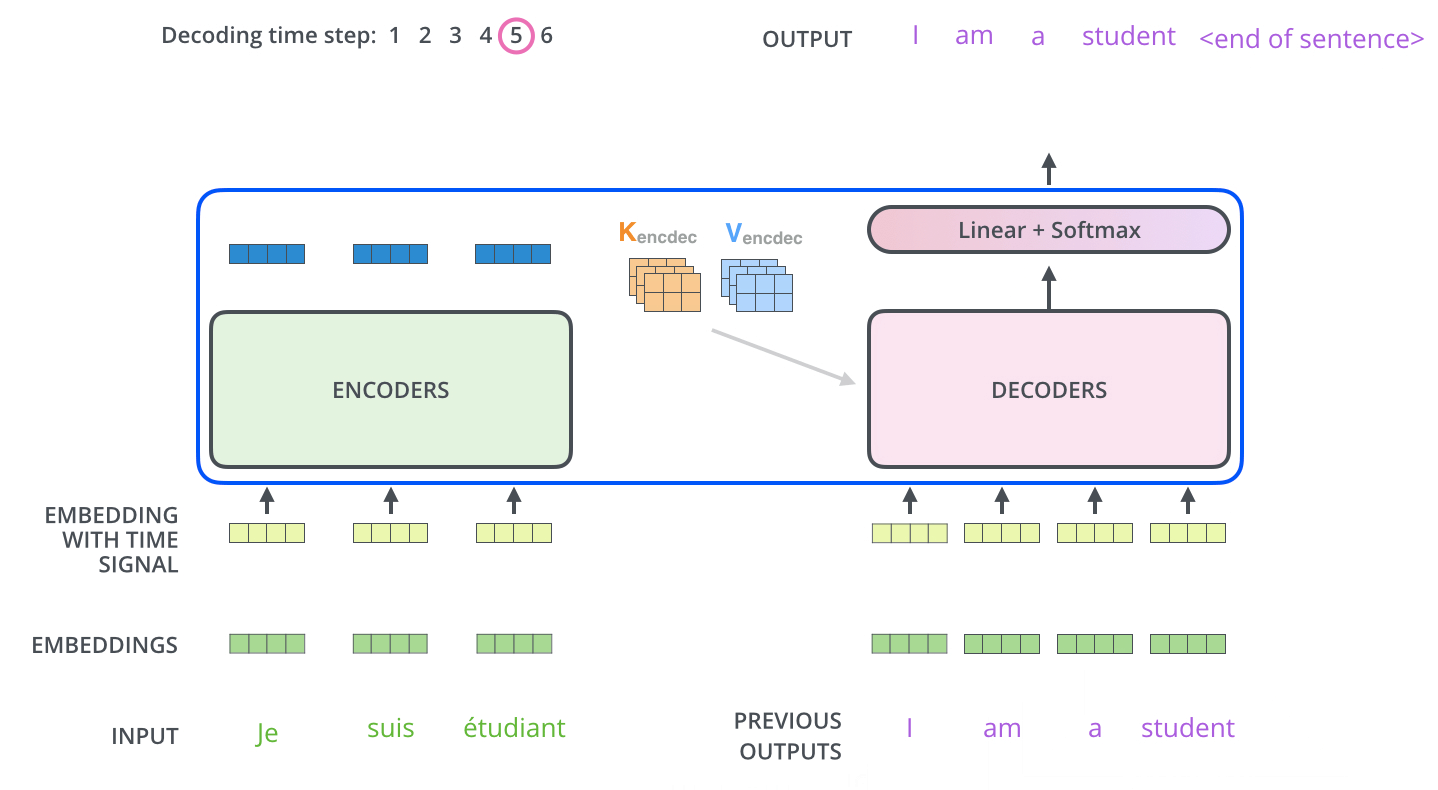
Encoder Decoder 整体联合起来看
1.整体架构
2. decode 过程
从下面动图的过程来看,整个transformer跟普通的encoder-decoder过程一样,decode过程也是一个一个往外吐的过程。