数据不平衡如何处理
数据不平衡
1.什么是数据不平衡
一般都是假设数据分布是均匀的,每种样本的个数差不多,但是现实情况下我们取到的数据并不是这样的,如果直接将分布不均的数据直接应用于算法,大多情况下都无法取得理想的结果。
这里着重考虑二分类,因为解决了二分类种的数据不平衡问题后,推而广之酒能得到多分类情况下的解决方案。
经验表明,训练数据中每个类别有5000个以上样本,其实也要相对于特征而言,来判断样本数目是不是足够,数据量是足够的,正负样本差一个数量级以内是可以接受的,不太需要考虑数据不平衡问题(完全是经验,没有理论依据,仅供参考)。
2.如何解决数据不平衡
我们将样本较多的类别记为“大众类”,样本较少的称为“小众类”。
下面是解决数据不平衡的方法
2.1 采样
通过随机样本抽取使得数据平衡,采样分为上采样和下采样,上采样就是将小众类复制多份,下采样就是从大众类种随机抽取样本与小种类一起作为训练集放进模型中。
优点:简单
缺点:上采样后数据集出现重复样本会导致一定的过拟合,下采样导致数据集丢失,模型只学会了总体模式的一部分。
那么怎么克服采样的缺点呢?看下面的方法:
(1) EasyEnsemble ,也就是集成,多次下采样,多次从大众类中抽取样本然后和小众类作为一个训练集放进模型,最后将多个模型输出结果进行组合得到最终结果。(使用了bagging的思想)
(2) BalanceCascade , 先通过一次下采样产生训练集,训练一个分类器,然后对于分类正确的大众类样本不放回,然后对这个更小的大众样本进行下采样,训练第二个训练器,......, 最终组合所有分类器的结果得到最终结果。(使用了boosting的思想)
2.2 数据合成(SMOTE)
所谓数据合成方法,就是利用已有样本生成更多样本。在医学图像分析中有显著效果。
它利用小众样本在特征空间的相似性来生成新样本。对于小众样本\(x_i\in S_{min}\),从它属于小众类的K近邻中随机选取一个样本点\(\hat{x}_i\),生成一个新的小众样本:
\(x_{new}=x_i + (\hat{x}_i-x_i)\times\delta\),\(\delta\in [0,1]\)是随机数。
以K=6,生成一个新的小众类:
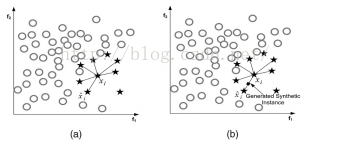
缺点:增加了类之间重叠的可能性,另一方面生成了一些没有提供有益信息的样本。
为了克服SMOTE的缺点,有下面的两种方法:
(1):Borderline-SMOTE,这里的寻找小众类的k紧邻时不局限于在小种类中寻找,而是在所有的样本集中寻找小众类的k紧邻,为k紧邻中有一半以上大众样本的小众样本生成新样本。 也就是说,只为哪些周围大部分是大众样本的小众样本生成新样本。因为这些样本往往是边界样本。
确定了为哪些小众样本生成新样本后,再利用SMOTE生成新样本。
(2):ADASYN,为不同小众样本生成不同数量的新样本
①根据最终的平衡程度设定总共需要生成的新小众样本数量G
②为每个小众样本\(x_i\)计算分布比例\(\Gamma_i\)
③最后为小众样本\(x_i\)生成新样本的个数为\(g_i = \Gamma_i \times G\),确定个数后再利用SMOTE生成新样本
参考:https://blog.csdn.net/u012879957/article/details/82459538

 浙公网安备 33010602011771号
浙公网安备 33010602011771号