Python可视化 | Seaborn包—heatmap()
seaborn.heatmap()的参数
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
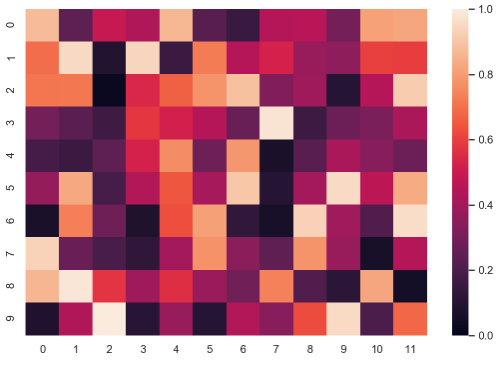
⚪ 绘制热图
uniform_data = np.random.rand(10,12) #随机创建10行12列的数组 pd.DataFrame(uniform_data) #以一个数据框的格式来显示 f,ax = plt.subplots(figsize=(9,6)) #定义一个子图宽高为9和6 ax存储的是图形放在哪个位置 ax = sns.heatmap(uniform_data,vmin = 0,vmax = 1) #vmin,vmax定义了色彩图的上下界 # sns.heatmap(uniform_data) #此语句会默认图形的大小画热图
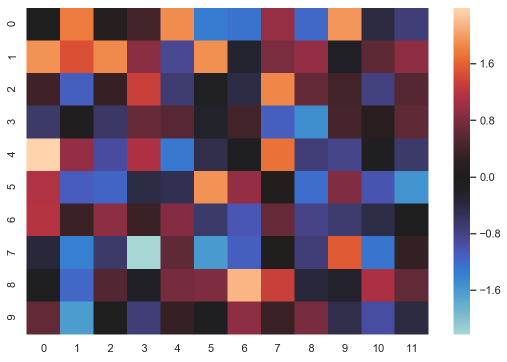
⚪ 使用发散色图绘制以0为中心得数据的热力图
uniform_data = np.random.randn(10, 12) f, ax = plt.subplots(figsize=(9, 6)) ax = sns.heatmap(uniform_data, center=0) #参数center = 0
⚪ 以数据集 flights 为例绘图
flights = pd.read_csv('C:\\Users\\86130\\Desktop\\flights.csv')
flights = sns.load_dataset("flights") 因为XJ的网络链接不了github所以该语句不可用
网址https://github.com/mwaskom/seaborn-data直接下载数据集 👆
数据集 flights 的部分截图:
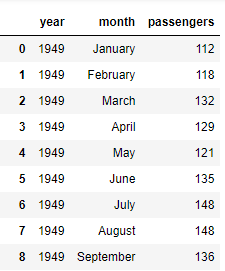
高效的函数pivot(),该函数有三个参数(index,columns,values),第一个参数index是指新表的索引,第二个参数columns是新表的列名,第三个参数values是指新表中的值,看效果就比较明确了 👇
new_flights = flights.pivot("month","year","passengers")
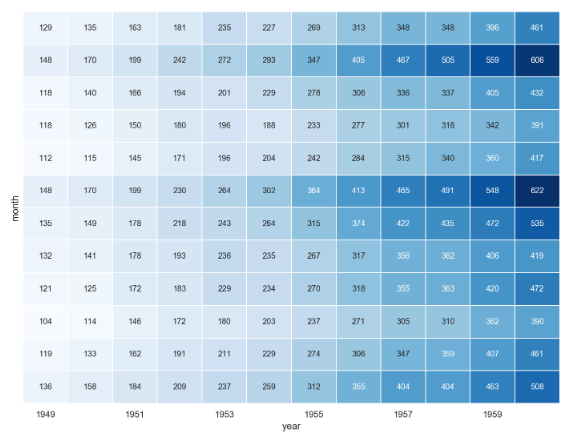
new_flights的数据显示:
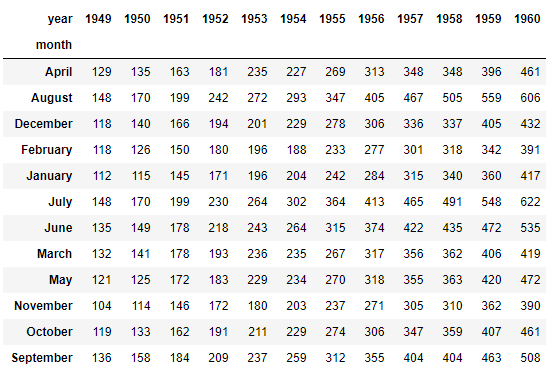
f,ax = plt.subplots(figsize=(9,6)) sns.heatmap(new_flights)
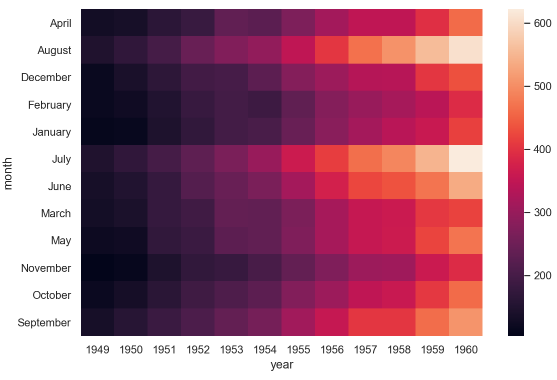
f,ax = plt.subplots(figsize=(12,9)) sns.heatmap(new_flights,annot = True,fmt = "d",linewidth =0.5,cmap = 'Blues',xticklabels = 2,yticklabels = False,cbar = False) #annot=True 为每个单元格写入值。 #参数fmt是指添加值的格式。这里设置为整数型 #linewidth是指划分每个单元格的行的宽度 #cmap设置热图的颜色 #xticklabels与yticklabes默认为1,即标签没有中断,若设置为False则不显示标签, #参数cbar默认为True,即绘制颜色条
⚪ 使用不同的轴作为颜色条,直接用代码吧。
grid_kws = {"height_ratios": (.9, .05), "hspace": .3}
f, (ax, cbar_ax) = plt.subplots(2, gridspec_kw=grid_kws)
ax = sns.heatmap(new_flights, ax=ax,
cbar_ax=cbar_ax,
cbar_kws={"orientation": "horizontal"})
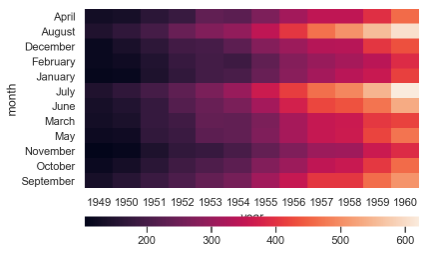
subplots函数中的参数gridspec_kw是将字典的关键字传递给GridSpec构造函数创建子图放在网格里。heatmap函数中的参数ax指绘制图的轴,否则使用当前活动的轴,cbar_ax用于绘制颜色条的轴,否则从主轴获取;cbar_kwsfig.colorbar的关键字参数.这部分不太会用大白话解释,直接上图吧 👆
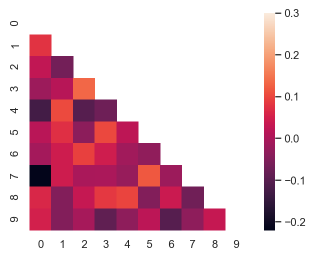
⚪ 绘制相关系数矩阵,因为对称仅绘制一半
corr = np.corrcoef(np.random.randn(10, 200))
mask = np.zeros_like(corr)
print(mask)
mask[np.triu_indices_from(mask)] = True #把上部分设置为1
#设置为1 的单元格将不再显示
#mask[np.tril_indices_from(mask)] = True #把下部分设置为1
print(mask)
with sns.axes_style("white"):
ax = sns.heatmap(corr, mask=mask, vmax=.3, square=True)
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]] [[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [0. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [0. 0. 1. 1. 1. 1. 1. 1. 1. 1.] [0. 0. 0. 1. 1. 1. 1. 1. 1. 1.] [0. 0. 0. 0. 1. 1. 1. 1. 1. 1.] [0. 0. 0. 0. 0. 1. 1. 1. 1. 1.] [0. 0. 0. 0. 0. 0. 1. 1. 1. 1.] [0. 0. 0. 0. 0. 0. 0. 1. 1. 1.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 1.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]