
随笔分类 - 机器学习
机器学习
摘要: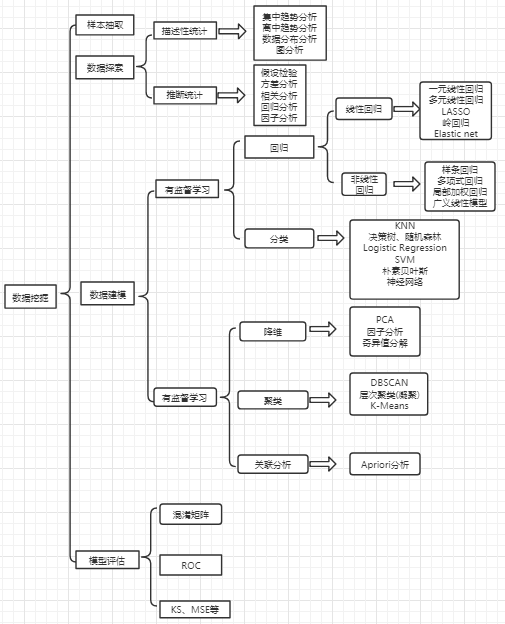
阅读全文
摘要:基于逻辑回归模型识别信用卡欺诈行为 1.平衡数据(imblearn) RandomOverSampler 过采样,从小众样本中复制样本或者使用SMOTE方法生成样本 多次欠采样,然后合并多个估计器或者采用boost思想,分类正确的不再放入原来的大众样本中 2.GridSearchCV paramet
阅读全文
摘要:from sklearn.preprocessing import LabelEncoder #举例对属性job进行LE编码 LE = LabelEncoder() label = LE.fit_transform(train['job']) print(label) sorted_job = so
阅读全文
摘要:几个常用的核函数: 根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数。 1.多项式核 K(x,z)=(x∙z+1)p,在此情形下,分类决策函数成为: \(f(x) = \mbox{sign}(\sum_{i=1}^{N_s}a_i^*y
阅读全文
摘要:这两个算法都可以解决线性分类问题和非线性分类问题(都使用kernel trick)。 如果是非线性分类,那么我们就首选SVM。 SVM不是概率输出,Logistic Regression是概率输出。 也就是说,当一个新样本来了,SVM只会告诉你它的分类,而Logistic Regression会告诉
阅读全文
摘要:HIVE SQL与SQL的区别: 1.HQL不支持增删改 2.不支持事务 3.支持分区存储 4.HQL不支持等值连接,使用JOIN 5.hive中没有not null,当字段为null时,使用\n代替 6.hive落地到hdfs,Mysql落地到磁盘
阅读全文
摘要:数据不平衡 1.什么是数据不平衡 一般都是假设数据分布是均匀的,每种样本的个数差不多,但是现实情况下我们取到的数据并不是这样的,如果直接将分布不均的数据直接应用于算法,大多情况下都无法取得理想的结果。 这里着重考虑二分类,因为解决了二分类种的数据不平衡问题后,推而广之酒能得到多分类情况下的解决方案。
阅读全文
摘要:最大熵模型 1.最大熵原理 最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。 最大熵原理认为,要选择的概率模型首先必须满足已有的事实,即约束条件。在没
阅读全文
摘要:牛顿法的应用: 1.求根:原理是函数f(x)展开到一阶导。 2.最优化:原理是函数f(x)展开到二阶导。 就应用2进行推导: f(x+△x)=f(x)+f′(x)△x+12f″ 这个式
阅读全文
摘要:函数空间 = 元素 + 规则 ,即一个函数空间由 元素 与 元素所满足的规则 定义,而要明白这些函数空间的定义首先得从距离,范数,内积,完备性等基本概念说起。 一.距离 说到距离,我们首先想到的是点与点之间的距离,除此之外还有向量之间的距离,曲线之间的距离,函数之间的距离…。这儿谈到 距离 的定义是
阅读全文
摘要:分析目的 分析空气中主要污染物浓度与空气指数之间的关系 分析数据 天气污染物浓度的数据集,该数据集源自天气后报网站上爬取的数据,为北京2013年10月28日到2016年1月31日的空气污染物浓度的数据。包括空气质量等级、AQI指数和当天排名。 import pandas as pd import n
阅读全文
摘要:分析:女性身高与体重的关系 该数据集源自The World Almanac and Book of Facts(1975) 给出了年龄在30-39岁之间的15名女性的身高和体重信息 1.线性回归 # packages import pandas as pd import numpy as np im
阅读全文
摘要:一元线性回归 ①基本假设: y = w0 + w1x + ε 其中 w0,w1 为回归系数,ε 为随机误差项(noise) 给定样本集合 D = { (x1,y1),…,(xn,yn)}, 我们的目标是找到一条直线 y = w0 + w1x ,使得所有样本点尽可能落在它的附近,即求解以下问题: ②一
阅读全文
摘要:算法1:k近邻法 复杂度:O(n) 算法2:构造平衡kd树 算法3:搜索kd树 复杂度:O(log(n)) 当空间维数接近训练实例数时,他的效率会迅速下降,几乎接近线性扫描 python代码实现k近邻法: # # k近邻算法 步骤: 1.导入数据 2.分割数据(用于交叉验证) 3.k近邻算法 4.模
阅读全文
摘要:广义线性模型:因变量不服从正态分布时,但所服从的的分布属于指数族分布,这样的模型成为广义线性模型。 逻辑回归公式推导: 定义: 联结函数: 则, 记, 则有, 损失函数的推导: (利用极大似然估计) 似然函数: 两边取对数(单调性不变): 损失函数: 梯度下降法更新参数: 梯度方向时函数值增加最快的
阅读全文
摘要:1.什么是感知机 感知机是一种线性分类模型,属于判别模型。感知机模型的假设空间是定义在特征空间中的所有线性分类模型或线性分类器,即函数集合。 2.感知机学习策略 2.1 数据集的线性可分性 给定一个数据集,其中,,,, 如果存在某个超平面 , 能够将数据集的正实例点和负实例点完全正确地划分到超平面的
阅读全文
摘要:恢复内容开始 转载:https://zhuanlan.zhihu.com/p/24913912 刚接触梯度下降这个概念的时候,是在学习机器学习算法的时候,很多训练算法用的就是梯度下降,然后资料和老师们也说朝着梯度的反方向变动,函数值下降最快,但是究其原因的时候,很多人都表达不清楚。所以我整理出自己的
阅读全文
摘要:https://blog.csdn.net/uncle_gy/article/details/78788737
阅读全文
