摘要:
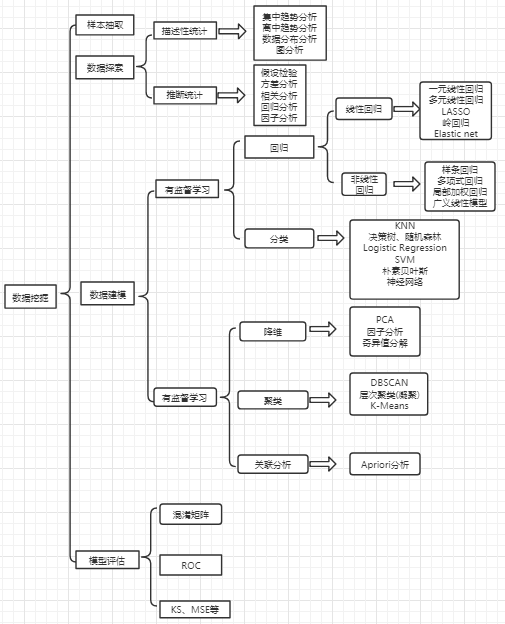 阅读全文
posted @ 2020-11-06 20:43
从前有座山,山上
阅读(79)
评论(0)
推荐(0)
摘要:
基于逻辑回归模型识别信用卡欺诈行为 1.平衡数据(imblearn) RandomOverSampler 过采样,从小众样本中复制样本或者使用SMOTE方法生成样本 多次欠采样,然后合并多个估计器或者采用boost思想,分类正确的不再放入原来的大众样本中 2.GridSearchCV paramet 阅读全文
posted @ 2020-11-06 18:40
从前有座山,山上
阅读(280)
评论(0)
推荐(0)
摘要:
1.数据运营,你会关注哪些指标? 1.拉新指标 浏览量、注册量、拉新成本 2.活跃指标 活跃用户数、活跃率、在线时长 3.留存指标 用户留存率、用户流失率 4.用户价值/转化指标 用户生命周期价值(CLV)、成交额、复购率、付费用户数 5.裂变指标: 裂变k因子 :发起邀请的用户数*转化率 、传播周 阅读全文
posted @ 2020-11-06 17:07
从前有座山,山上
阅读(218)
评论(0)
推荐(0)
摘要:
参考:https://blog.csdn.net/ganghaodream/article/details/100083543 SQL计算最长登录天数 计算最长登陆天数主要用两个函数:1.窗口函数row_number()over() 2.date_sub() 1.使用row_number()窗口函数 阅读全文
posted @ 2020-11-06 12:25
从前有座山,山上
阅读(6661)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号