
unordered_set是一种关联容器,set和map内部实现是基于RB-Tree,是有序的,unordered_set和unordered_map是基于hashtable。是无序的。
首先了解哈希表的机制。哈希表是根据关键码值进行直接访问的数据结构,通过相应的哈希函数处理关键字得到相应的关键码值,关键码值对应着一个特定位置,用该位置来存取相应的信息。这样就能以较快的速度获取关键字的信息。
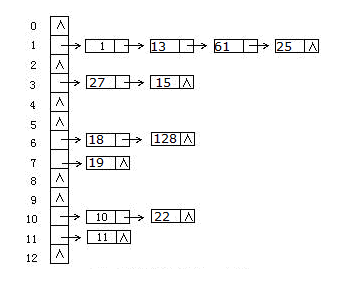
unordered_set解决内部冲突采用的是--链地址法。当有冲突发生时,把具有同一关键码的数据组成一个链表,下图展示了链地址法的使用:
模板原型:
template<class Key,
class Hash=hash<Key>,
class Pred=equal_to<Key>,
class Alloc=allocator<Key>,
>class unordered_set;
unordered_set具有快速查找,删除,添加的优点
基本使用:
一、定义
unordered_set<int> c1;
二、容量操作
c1.empty();//判断是否为空 c1.size();//获取元素个数 c1.max_size();//获取最大存储量
三、迭代器操作
//返回头迭代器 unordered_set<int>::iterator ite_begin=c1.begin(); //返回尾迭代器 unordered_set<int>::iterator ite_end=c1.end(); //槽迭代器 unordered_set<int>::iterator local_iter_begin=c1.begin(1); unordered_set<int>::iterator local_iter_end=c1.end(1);
四、基本操作
1 //查找函数find通过给定主键查找元素 2 unordered_set<int>::iterator find_iter=c1.find(1); 3 //value出现的次数count返回匹配给定主键元素的个数 4 c1.count(1); 5 //返回元素在哪个区域equal_range,返回值匹配给定搜索值的元素组成的范围 6 pair<unordered_set<int>::iterator, 7 unordered_set<int>::iterator> pair_equal_range = c1.equal_range(1); 8 //插入函数emplace 9 c1.emplace(1); 10 //插入函数emplace_hint()使用迭代器 11 c1.emplace_hint(ite.begin,1); 12 //插入函数insert 13 c1.insert(1); 14 //删除erase 15 c1.erase(1); 16 //清空clear 17 c1.clear(); 18 //交换swap 19 c1.swap(c2);
五、篮子操作
1 //篮子操作,篮子个数bucket_count,返回槽数 2 c1.bucket_count(); 3 //篮子最大数量max_bucket_count,返回最大槽数 4 c1.max_bucket_count(); 5 //篮子个数bucket_size返回槽大小 6 c1.bucket_size(3); 7 //返回篮子bucket,返回元素所在槽的序号 8 c1.bucket(1); 9 //返回载入因子,即一个元素槽的最大元素数 10 c1.load_factor(); 11 //返回或设置最大载入因子 12 c1.max_load_factor();
六、内存操作
1 c1.rehash(1);//rehash设置槽数 2 c1.reserve(1000);//请求改变容器容量
七、hash func
1 auto hash_func_test=c1.hash_function();//返回与hash_func相同函数的指针
2 auto key_eq_test=c1.key_eq();//返回比较key值得函数指针
