

CQRS并不复杂
两天前Rob Ashton写了一篇博客CQRS is too complicated,实际内容是说CQRS并不复杂,只是要看你怎么去实施(以及别把PPT整得太复杂)。
摘要如下(顺序有打乱,我自己怎么理解起来方便怎么总结-v-)
一说起CQRS,人们头脑中就是这样的东西
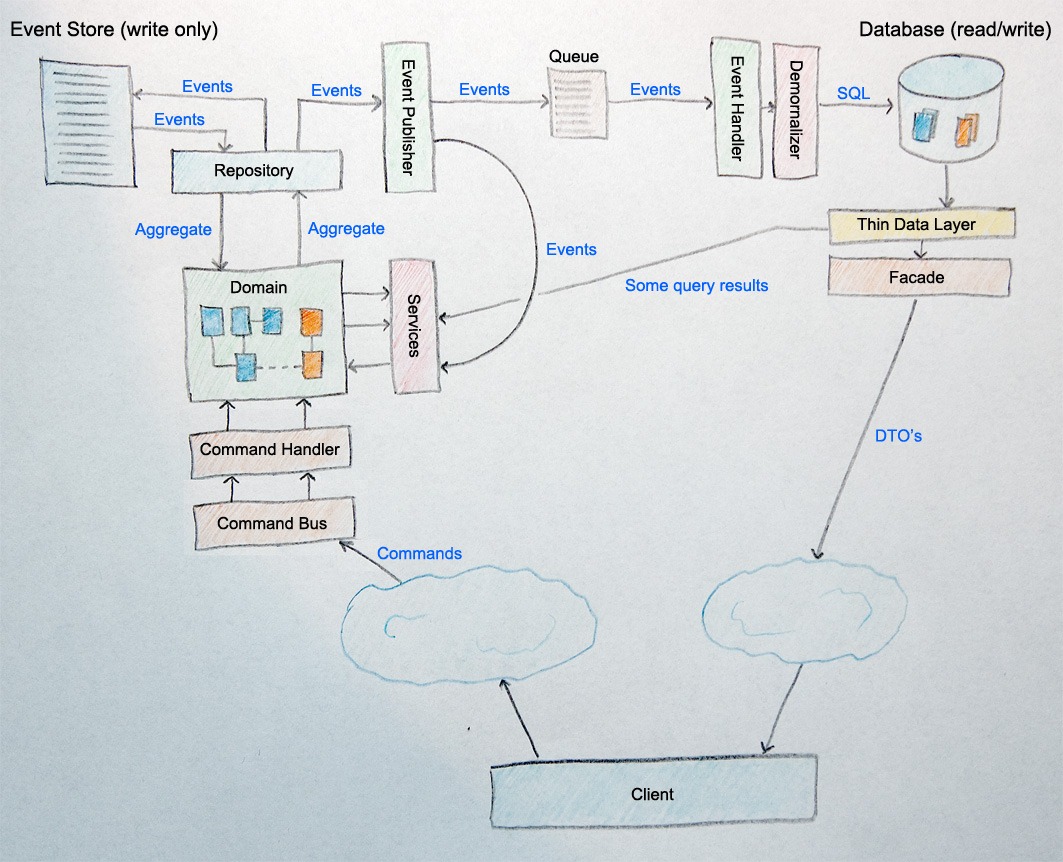
实际上,CQRS在高层次的意义上来说,就是要读写分离,跟事件溯源啊神马的并不一定有联系。
首先看这样一个经常见到的所谓N层架构
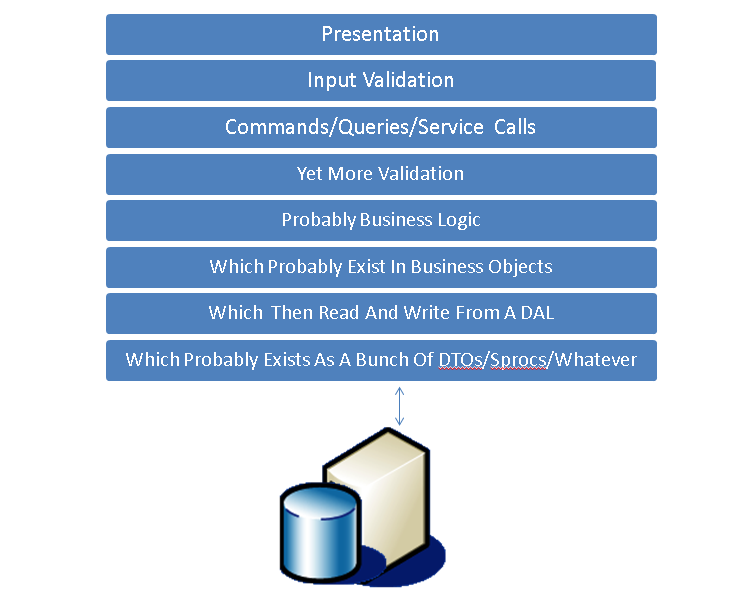
很大的问题在于这个架构尝试用统一的模型去访问数据,然而实际上读操作是简单的,不同于写操作要经过很多疯狂的逻辑例如验证、更新队列、第三方系统、业务规则之类。这种模型也往往是为写操作特殊优化过。实际上大型系统中往往会让读操作不经过所谓的“统一模型”,直接用SQL或者存储过程访问数据库,变成下面这种样子。
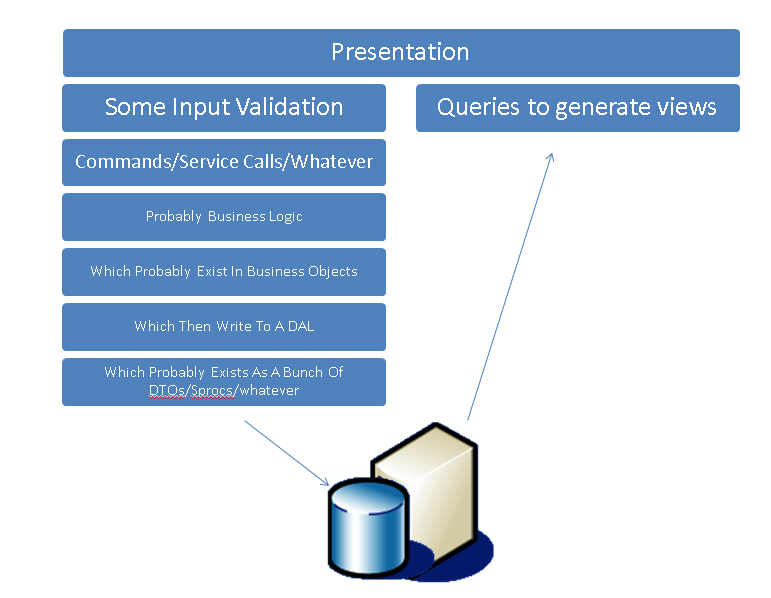
这现在其实已经是一种CQRS了,在更高层次的意义上来说,我们已经将我们的读写模型分离,然后再method级别做了一些非常类似于我们称之为CQS的事情。这本身应该已经让人满足:CQRS本身并不复杂,值得关注。
一些例子
CQRS可以用文本型数据库来实现,例如Raven或者Couch。用document来作为写仓储,用index作为读仓储。
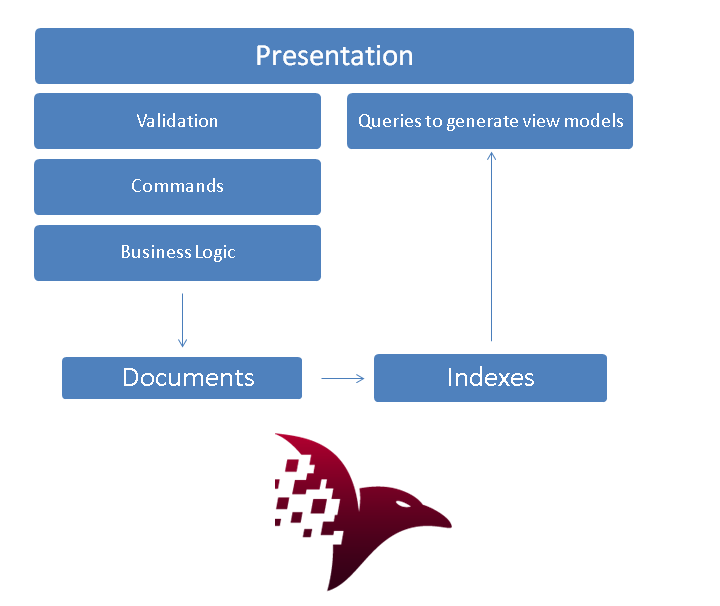
如果你喜欢ORM,你也可以这样构建你的读写分离,即使你只用一个数据库(有趣的是、越是使用NHibernate越是觉得需要读写分离)
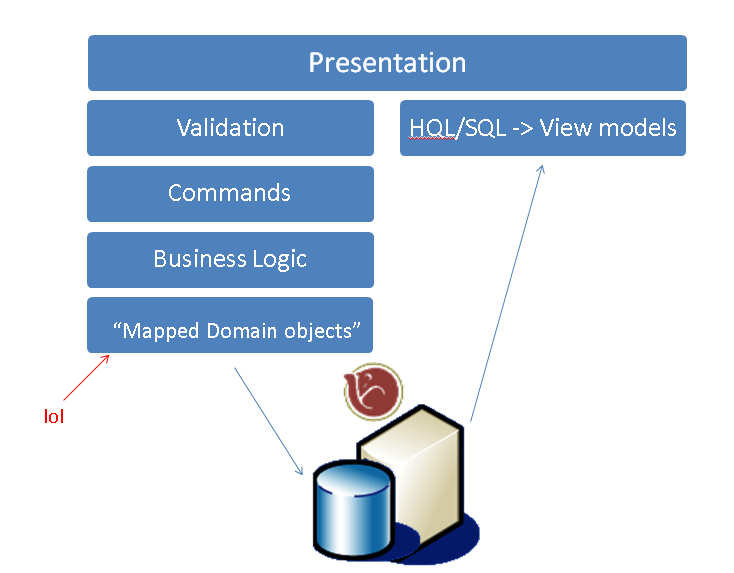
当然也可以搞双数据库,数据写入写数据库后直接计算成为为View优化过的样子存入读数据库。
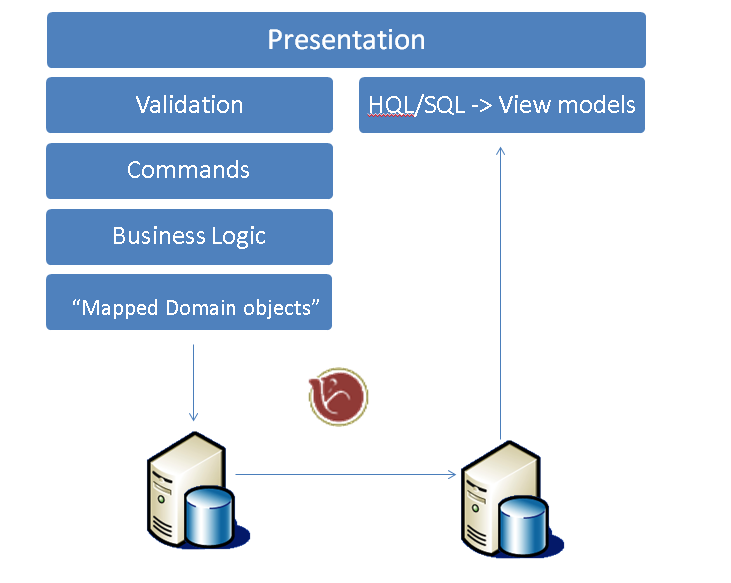
即使加上事件溯源也没那么复杂。其实就是把写数据作为事件抛出来,让其他东西有机会处理一下。
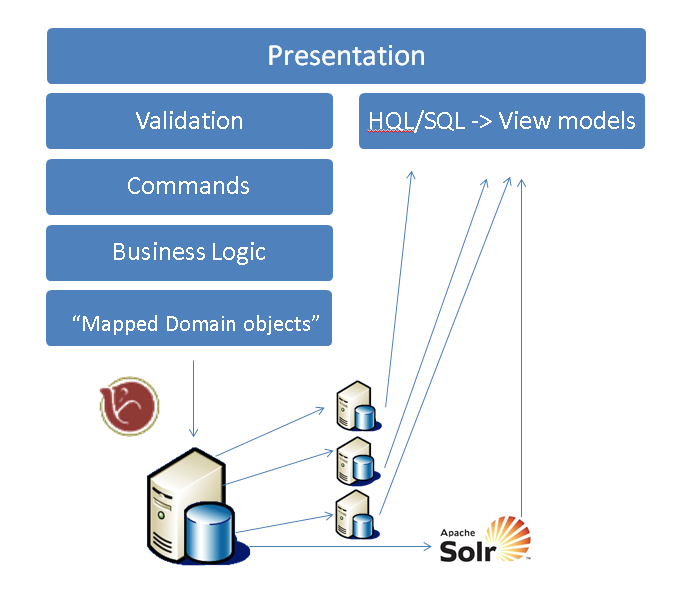
说实话原文没太读懂,希望英语好的各位多指教= =
另原作者特别说了一句,本文和DDD半毛钱关系都没有,所以看到存储过程神马的也请勿喷。

