


大数据-分布式-Hadoop介绍
一、Hadoop介绍
Hadoop是大数据组件。大数据是海量数据的处理和分析的技术,需要用分布式框架。分布式则是通过多个主机的进程协同在一起,构成整个应用。
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,它可以使用户在不了解分布式底层细节的情況下开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop解決了两大问题:大数据存储、大数据分析。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。
Hadoop主要基于java语言实现,由三个核心子系统组成:HDFS、YARN、MapReduce,其中HDFS是一套分布式文件系统;YARN是资源管理系统;MapReduce是运行在YARN上的应用,负责分布式处理管理.。从操作系统的角度来看的话,HDFS相当于Linnux的ext3/ext4文件系统,而yarn相当于Linux的进程调度和内存分配模块。
1. HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。适合部署在大量廉价的机器上,提供高吞吐量的数据访问。
2. YARN:资源管理器,可为上层应用提供统一的资源管理和调度,兼容多计算框架。
3. MapReduce 是一种分布式编程模型,把对大规模数据集的处理分发给网络上的多个节点,之后收集处理结果进行规约。
二、Hadoop集群三种模式
1. 在CentOS 7.6上搭建hadoop
1)修改主机名,关闭防火墙
[root@kvm01 ~]# hostnamectl set-hostname hadoop101
[root@hadoop101 ~]# systemctl stop firewalld [root@hadoop101 ~]# systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) Active: inactive (dead) Docs: man:firewalld(1)
2)在/opt目录下创建module和software目录
[root@hadoop101 ~]# mkdir /opt/{module,software}
3)安装jdk和hadoop
#下载jdk
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
#下载hadoop-2.7.3.tar.gz
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
[root@hadoop101 ~]# cd /opt/software/ [root@hadoop101 software]# ll total 574904 -rw-r--r-- 1 root root 214092195 Oct 28 22:07 hadoop-2.7.3.tar.gz -rw-r--r-- 1 root root 179472367 May 19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 May 27 18:05 jdk-8u251-linux-x64.tar.gz
[root@hadoop101 software]# tar -zxvf jdk-8u251-linux-x64.tar.gz [root@hadoop101 software]# tar -zxvf hadoop-2.7.3.tar.gz
4)创建符号链接

[root@hadoop101 software]# ll total 574904 drwxr-xr-x 9 root root 149 Aug 18 2016 hadoop-2.7.3 -rw-r--r-- 1 root root 214092195 Oct 28 22:07 hadoop-2.7.3.tar.gz drwxr-xr-x 7 10143 10143 245 Mar 12 2020 jdk1.8.0_251 -rw-r--r-- 1 root root 179472367 May 19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 May 27 18:05 jdk-8u251-linux-x64.tar.gz [root@hadoop101 software]# ln -s jdk1.8.0_251/ jdk [root@hadoop101 software]# ln -s hadoop-2.7.3/ hadoop [root@hadoop101 software]# ll total 574904 lrwxrwxrwx 1 root root 13 Oct 28 22:24 hadoop -> hadoop-2.7.3/ drwxr-xr-x 9 root root 149 Aug 18 2016 hadoop-2.7.3 -rw-r--r-- 1 root root 214092195 Oct 28 22:07 hadoop-2.7.3.tar.gz lrwxrwxrwx 1 root root 13 Oct 28 22:23 jdk -> jdk1.8.0_251/ drwxr-xr-x 7 10143 10143 245 Mar 12 2020 jdk1.8.0_251 -rw-r--r-- 1 root root 179472367 May 19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 May 27 18:05 jdk-8u251-linux-x64.tar.gz
5)配置环境变量
[root@hadoop101 software]# vim /etc/profile [root@hadoop101 software]# tail /etc/profile done unset i unset -f pathmunge #配置以下内容 export JAVA_HOME=/opt/software/jdk export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/opt/software/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#生效 [root@hadoop101 software]# source /etc/profile
6)查看版本
[root@hadoop101 software]# java -version java version "1.8.0_251" Java(TM) SE Runtime Environment (build 1.8.0_251-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode) [root@hadoop101 software]# hadoop version Hadoop 2.7.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff Compiled by root on 2016-08-18T01:41Z Compiled with protoc 2.5.0 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 This command was run using /opt/software/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
7)相关命令
#当前目录创建文件
[root@hadoop101 software]# hdfs dfs -touchz hadoop.txt
#列出当前目录下文件(夹) [root@hadoop101 software]# hdfs dfs -ls Found 8 items drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop-2.7.3 -rw-r--r-- 1 root root 214092195 2020-10-28 22:07 hadoop-2.7.3.tar.gz -rw-r--r-- 1 root root 0 2020-10-28 22:40 hadoop.txt drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk -rw-r--r-- 1 root root 179472367 2020-05-19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 2020-05-27 18:05 jdk-8u251-linux-x64.tar.gz drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk1.8.0_251
#删除文件 [root@hadoop101 software]# hdfs dfs -rm hadoop.txt 20/10/28 22:40:55 INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum 20/10/28 22:40:55 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted hadoop.txt [root@hadoop101 software]# hdfs dfs -ls Found 7 items drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop-2.7.3 -rw-r--r-- 1 root root 214092195 2020-10-28 22:07 hadoop-2.7.3.tar.gz drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk -rw-r--r-- 1 root root 179472367 2020-05-19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 2020-05-27 18:05 jdk-8u251-linux-x64.tar.gz drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk1.8.0_251
#创建文件夹 [root@hadoop101 software]# hdfs dfs -mkdir aaa [root@hadoop101 software]# hdfs dfs -ls Found 8 items drwxr-xr-x - root root 6 2020-10-28 22:41 aaa drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop drwxr-xr-x - root root 149 2016-08-18 09:49 hadoop-2.7.3 -rw-r--r-- 1 root root 214092195 2020-10-28 22:07 hadoop-2.7.3.tar.gz drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk -rw-r--r-- 1 root root 179472367 2020-05-19 20:30 jdk-8u251-linux-x64.rpm -rw-r--r-- 1 root root 195132576 2020-05-27 18:05 jdk-8u251-linux-x64.tar.gz drwxr-xr-x - 10143 10143 245 2020-03-12 14:37 jdk1.8.0_251
2. Hadoop的目录结构
1)bin目录:存放对Hadoop相关的服务(HDFS,YARN)进行操作的脚本
2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
3)lib目录:存放Hadoop的本地库(对数据进行压缩解压功能)
4)sbin目录:存放启动或者停止Hadoop相关服务的脚本
5)share目录:存放Hadoop的依赖jar包、文档和官方案例
3. Hadoop三种集群三种模式:本地模式、伪分布式、完全分布式
Hadoop官方网站:http://hadoop.apache.org/
1). 本地模式
单主机模式,不需要启动进程
官方Grep案例
a. 创建在hadoop文件下面创建一个input文件夹
[root@hadoop101 software]# cd hadoop [root@hadoop101 hadoop]# ll total 108 drwxr-xr-x 2 root root 194 Aug 18 2016 bin drwxr-xr-x 3 root root 20 Aug 18 2016 etc drwxr-xr-x 2 root root 106 Aug 18 2016 include drwxr-xr-x 3 root root 20 Aug 18 2016 lib drwxr-xr-x 2 root root 239 Aug 18 2016 libexec -rw-r--r-- 1 root root 84854 Aug 18 2016 LICENSE.txt -rw-r--r-- 1 root root 14978 Aug 18 2016 NOTICE.txt -rw-r--r-- 1 root root 1366 Aug 18 2016 README.txt drwxr-xr-x 2 root root 4096 Aug 18 2016 sbin drwxr-xr-x 4 root root 31 Aug 18 2016 share [root@hadoop101 hadoop]# mkdir input
b.将Hadoop的xml配置文件复制到input
[root@hadoop101 hadoop]# cp etc/hadoop/*.xml input [root@hadoop101 hadoop]# ll input/ total 48 -rw-r--r-- 1 root root 4436 Oct 28 22:47 capacity-scheduler.xml -rw-r--r-- 1 root root 774 Oct 28 22:47 core-site.xml -rw-r--r-- 1 root root 9683 Oct 28 22:47 hadoop-policy.xml -rw-r--r-- 1 root root 775 Oct 28 22:47 hdfs-site.xml -rw-r--r-- 1 root root 620 Oct 28 22:47 httpfs-site.xml -rw-r--r-- 1 root root 3518 Oct 28 22:47 kms-acls.xml -rw-r--r-- 1 root root 5511 Oct 28 22:47 kms-site.xml -rw-r--r-- 1 root root 690 Oct 28 22:47 yarn-site.xml
c.执行share目录下的MapReduce程序
[root@hadoop101 hadoop]# ll share/hadoop/mapreduce total 4972 -rw-r--r-- 1 root root 537521 Aug 18 2016 hadoop-mapreduce-client-app-2.7.3.jar -rw-r--r-- 1 root root 773501 Aug 18 2016 hadoop-mapreduce-client-common-2.7.3.jar -rw-r--r-- 1 root root 1554595 Aug 18 2016 hadoop-mapreduce-client-core-2.7.3.jar -rw-r--r-- 1 root root 189714 Aug 18 2016 hadoop-mapreduce-client-hs-2.7.3.jar -rw-r--r-- 1 root root 27598 Aug 18 2016 hadoop-mapreduce-client-hs-plugins-2.7.3.jar -rw-r--r-- 1 root root 61745 Aug 18 2016 hadoop-mapreduce-client-jobclient-2.7.3.jar -rw-r--r-- 1 root root 1551594 Aug 18 2016 hadoop-mapreduce-client-jobclient-2.7.3-tests.jar -rw-r--r-- 1 root root 71310 Aug 18 2016 hadoop-mapreduce-client-shuffle-2.7.3.jar -rw-r--r-- 1 root root 295812 Aug 18 2016 hadoop-mapreduce-examples-2.7.3.jar drwxr-xr-x 2 root root 4096 Aug 18 2016 lib drwxr-xr-x 2 root root 30 Aug 18 2016 lib-examples drwxr-xr-x 2 root root 4096 Aug 18 2016 sources [root@hadoop101 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input/ output 'dfs[a-z.]+'
d.查看输出结果
[root@hadoop101 hadoop]# ll output/ total 4 -rw-r--r-- 1 root root 11 Oct 28 22:54 part-r-00000 -rw-r--r-- 1 root root 0 Oct 28 22:54 _SUCCESS [root@hadoop101 hadoop]# cat output/* 1 dfsadmin
官方WordCount案例
#创建目录和文件
[root@hadoop101 hadoop]# mkdir wcinput [root@hadoop101 hadoop]# cd wcinput/ [root@hadoop101 wcinput]# touch wc.input
#编辑wc.input文件 [root@hadoop101 wcinput]# vi wc.input [root@hadoop101 wcinput]# cat wc.input hadoop yarn hadoop mapreduce docker xixi
#回到Hadoop目录 [root@hadoop101 wcinput]# cd ..
#执行程序 [root@hadoop101 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount wcinput wcoutput
#查看结果 [root@hadoop101 hadoop]# ll wcoutput/ total 4 -rw-r--r-- 1 root root 44 Oct 28 23:04 part-r-00000 -rw-r--r-- 1 root root 0 Oct 28 23:04 _SUCCESS [root@hadoop101 hadoop]# cat wcoutput/part-r-00000 docker 1 hadoop 2 mapreduce 1 xixi 1 yarn 1
2). 伪分布式
单主机,需要启动进程,启动HDFS并运行MapReduce程序
a. 配置三种模式并存
[root@hadoop101 hadoop]# pwd /opt/software/hadoop [root@hadoop101 hadoop]# cd etc/ [root@hadoop101 etc]# ll total 4 drwxr-xr-x 2 root root 4096 Aug 18 2016 hadoop
#拷贝hadoop文件夹 [root@hadoop101 etc]# cp -r hadoop local [root@hadoop101 etc]# cp -r hadoop pseudo [root@hadoop101 etc]# cp -r hadoop full [root@hadoop101 etc]# ll total 16 drwxr-xr-x 2 root root 4096 Oct 28 23:14 full drwxr-xr-x 2 root root 4096 Aug 18 2016 hadoop drwxr-xr-x 2 root root 4096 Oct 28 23:14 local drwxr-xr-x 2 root root 4096 Oct 28 23:14 pseudo [root@hadoop101 etc]# rm -rf hadoop/ [root@hadoop101 etc]# ln -s pseudo/ hadoop [root@hadoop101 etc]# ll total 12 drwxr-xr-x 2 root root 4096 Oct 28 23:14 full lrwxrwxrwx 1 root root 7 Oct 28 23:15 hadoop -> pseudo/ drwxr-xr-x 2 root root 4096 Oct 28 23:14 local drwxr-xr-x 2 root root 4096 Oct 28 23:14 pseudo
b.进入hadoop配置文件目录下,修改配置文件
[root@hadoop101 etc]# cd hadoop/ [root@hadoop101 hadoop]# pwd /opt/software/hadoop/etc/hadoop #配置core-site.xml [root@hadoop101 hadoop]# vim core-site.xml [root@hadoop101 hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name>
#<!-- 指定HDFS中NameNode的地址 --> <value>hdfs://localhost/</value> </property> </configuration>
#配置hdfs-site.xml [root@hadoop101 hadoop]# vim hdfs-site.xml [root@hadoop101 hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <!-- 指定HDFS副本的数量 --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
#配置 mapred-site.xml [root@hadoop101 hadoop]# cp mapred-site.xml.template mapred-site.xml [root@hadoop101 hadoop]# vim mapred-site.xml [root@hadoop101 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property>
<!-- 指定MR运行在YARN上 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
#配置yarn-site.xml [root@hadoop101 hadoop]# vim yarn-site.xml [root@hadoop101 hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property>
<!-- 指定YARN的ResourceManager的地址 --> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> </property> <property>
<!-- Reducer获取数据的方式 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
[root@hadoop101 hadoop]# vim hadoop-env.sh [root@hadoop101 hadoop]# cat hadoop-env.sh |grep JAVA_HOME # The only required environment variable is JAVA_HOME. All others are # set JAVA_HOME in this file, so that it is correctly defined on export JAVA_HOME=/opt/software/jdk
c. 配置ssh免密登陆
[root@hadoop101 hadoop]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa Generating public/private rsa key pair. Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: d6:a3:c3:ef:c8:76:09:6c:cd:1b:5c:1a:c6:a1:78:f4 root@hadoop101 The key's randomart image is: +--[ RSA 2048]----+ | | | . . | | o + . | | . o.E . | | oS=o+ | | o+.*. | | .+. + | | ..++ | | .ooo | +-----------------+ [root@hadoop101 hadoop]# ssh-copy-id hadoop101 The authenticity of host 'hadoop101 (10.0.0.131)' can't be established. ECDSA key fingerprint is 80:18:52:09:3f:b9:8b:95:3c:dd:fa:d6:0c:98:15:7b. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop101's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop101'" and check to make sure that only the key(s) you wanted were added.
d.启动集群
#格式化hdfs文件系统
[root@hadoop101 hadoop]# hdfs namenode -format
#启动hadoop进程
[root@hadoop101 hadoop]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /opt/software/hadoop-2.7.3/logs/hadoop-root-namenode-hadoop101.out localhost: starting datanode, logging to /opt/software/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop101.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/software/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-hadoop101.out starting yarn daemons resourcemanager running as process 2014. Stop it first. localhost: starting nodemanager, logging to /opt/software/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop101.out
e. 查看集群
[root@hadoop101 hadoop]# jps 2548 NameNode 3174 Jps 3063 NodeManager 2651 DataNode 2014 ResourceManager 2815 SecondaryNameNode
f.web端查看HDFS文件系统
hdfs:分布式文件系统,进程如下
DataNode
NameNode
SecondaryNameNode
http://10.0.0.131:50070 //ip为当前机器ip
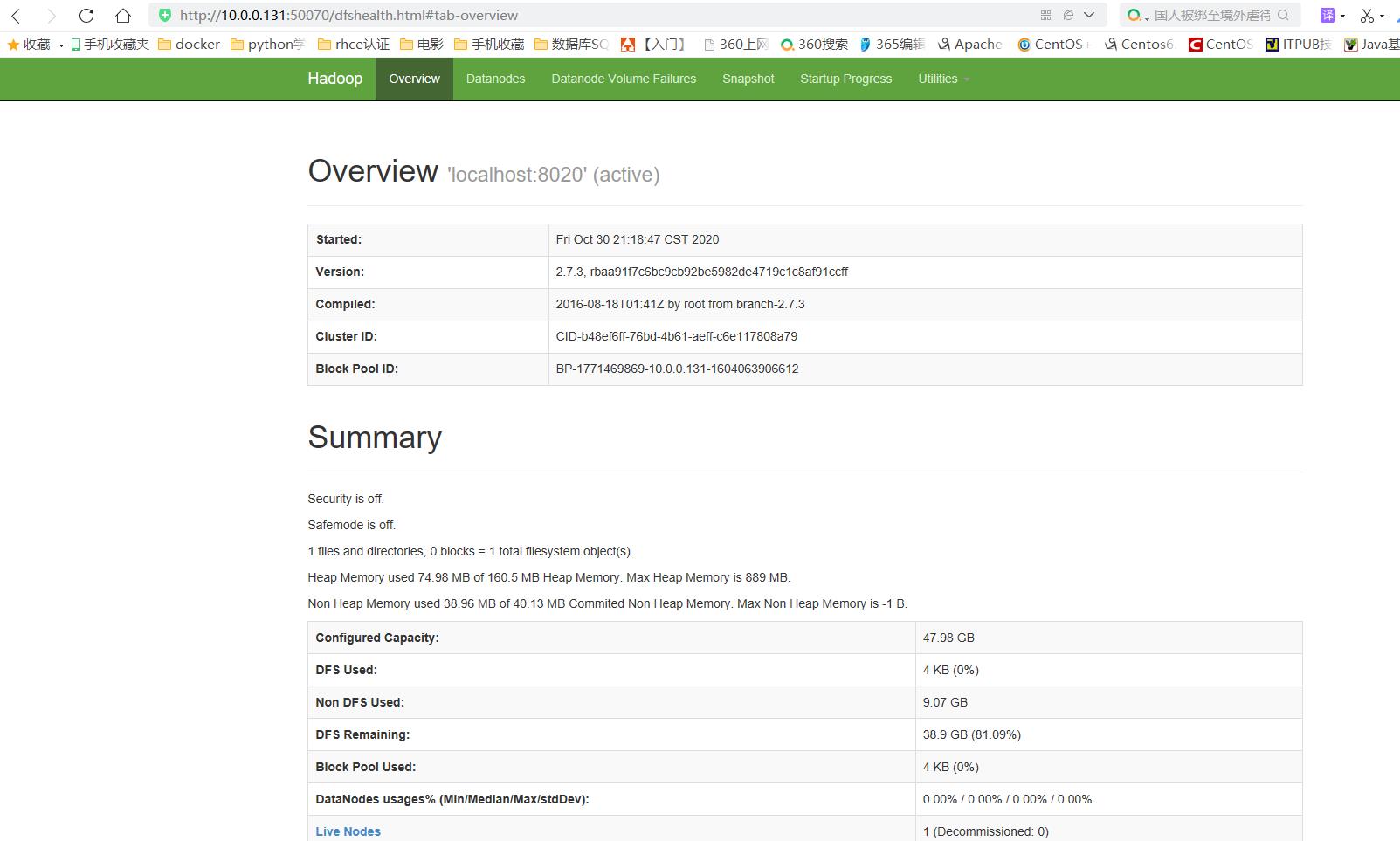
g.操作集群
#在HD FS文件系统上创建一个文件
[root@hadoop101 hadoop]# hdfs dfs -touchz /hadoop.txt
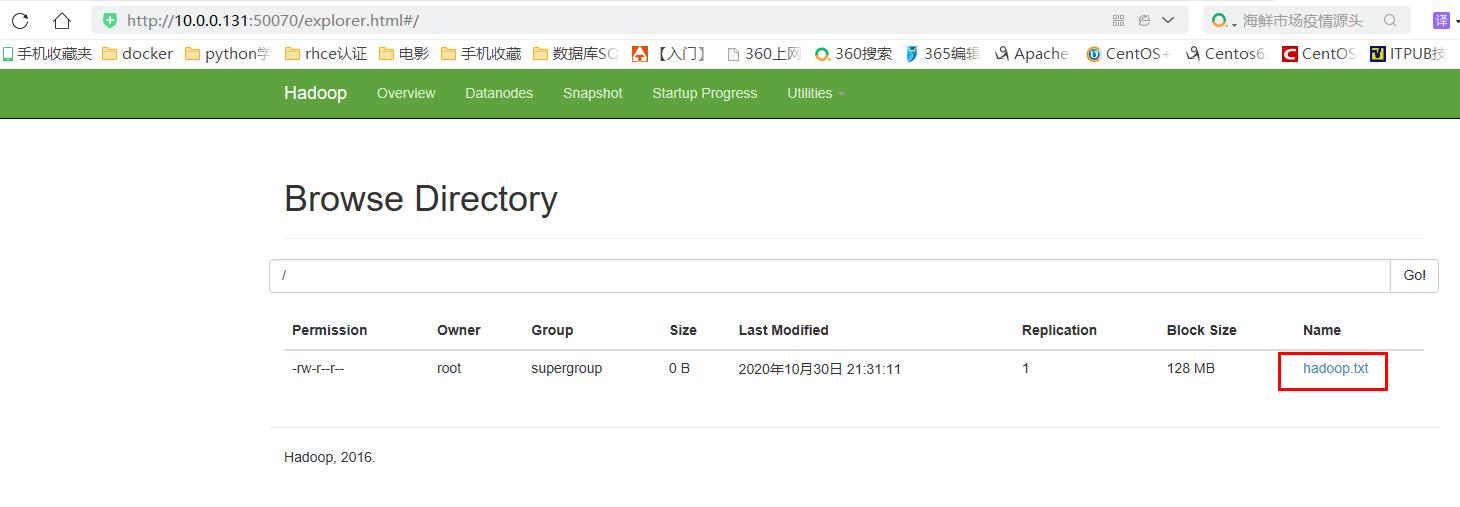
[root@hadoop101 hadoop]# hdfs dfs -ls / Found 1 items -rw-r--r-- 1 root supergroup 0 2020-10-30 21:31 /hadoop.txt [root@hadoop101 hadoop]# hdfs dfs -mkdir /aaa [root@hadoop101 hadoop]# hdfs dfs -ls / Found 2 items drwxr-xr-x - root supergroup 0 2020-10-30 21:34 /aaa -rw-r--r-- 1 root supergroup 0 2020-10-30 21:31 /hadoop.txt
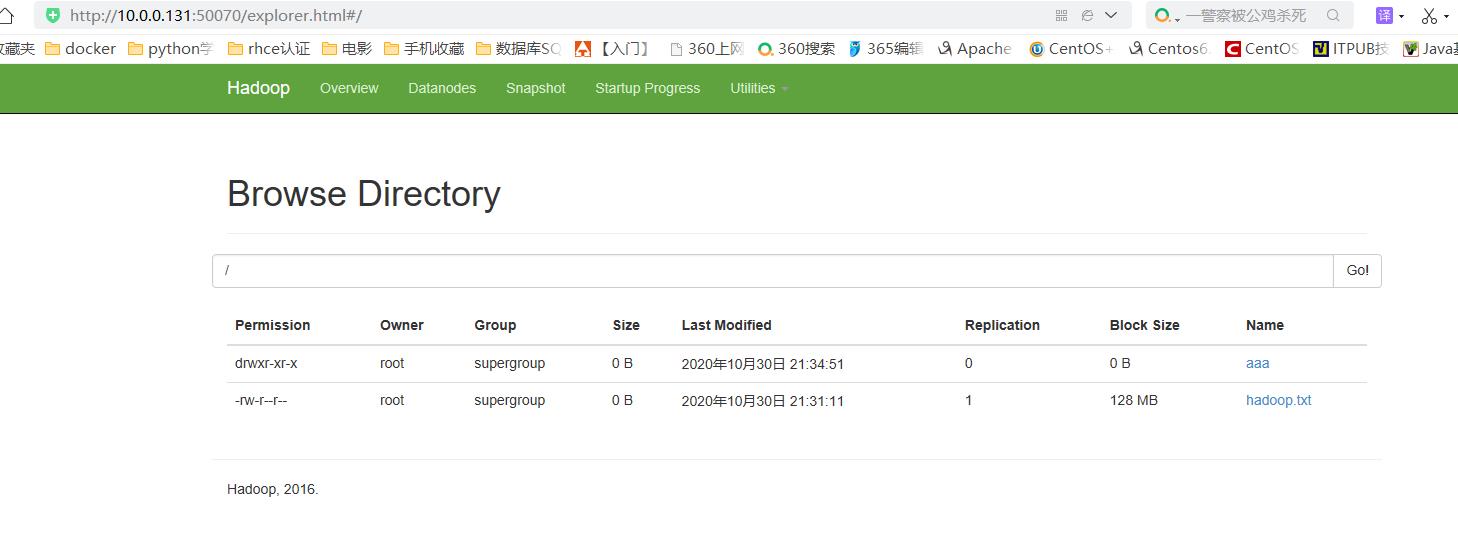
#mapreduce:分布式计算
通过Mapreduce进行简单的单词统计统计词频,使用自带的demo
#在本地创建wordcount.txt文件,并将一段英文文档粘贴到文档中
[root@hadoop101 hadoop]# vim wordcount.txt [root@hadoop101 hadoop]# cat wordcount.txt hdfs dfs -put wordcount.txt / hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wordcount.txt /out
#将wordcount.txt发送到hadoop中
[root@hadoop101 hadoop]# hdfs dfs -put wordcount.txt / [root@hadoop101 hadoop]# hdfs dfs -ls / Found 3 items drwxr-xr-x - root supergroup 0 2020-10-30 21:34 /aaa -rw-r--r-- 1 root supergroup 0 2020-10-30 21:31 /hadoop.txt -rw-r--r-- 1 root supergroup 144 2020-10-30 21:43 /wordcount.txt
#运行MapReduce程序
[root@hadoop101 hadoop]# hadoop jar /opt/software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wordcount.txt /out
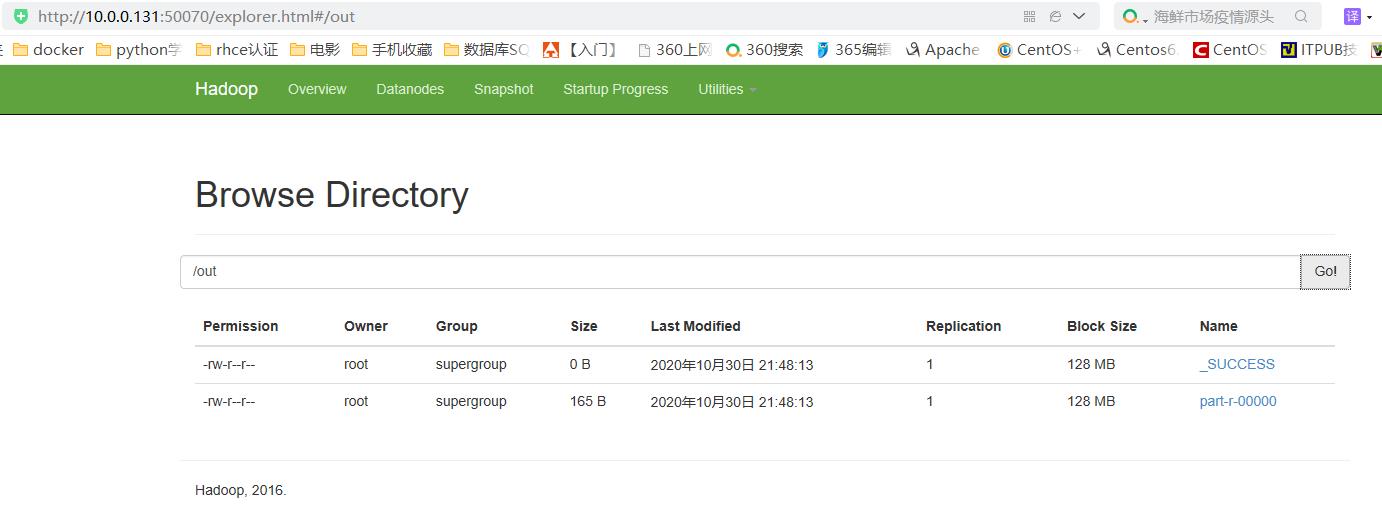
[root@hadoop101 ~]# hdfs dfs -get /out/part-r-00000 . [root@hadoop101 ~]# ll total 8 -rw-------. 1 root root 1423 Sep 5 12:14 anaconda-ks.cfg -rw-r--r-- 1 root root 165 Oct 30 22:22 part-r-00000
[root@hadoop101 ~]# cat part-r-00000 -put 1 / 1 /out 1 /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar 1 /wordcount.txt 1 dfs 1 hadoop 1 hdfs 1 jar 1 wordcount 1 wordcount.txt 1
#YARN的浏览器页面查看
http://10.0.0.131:8088/cluster
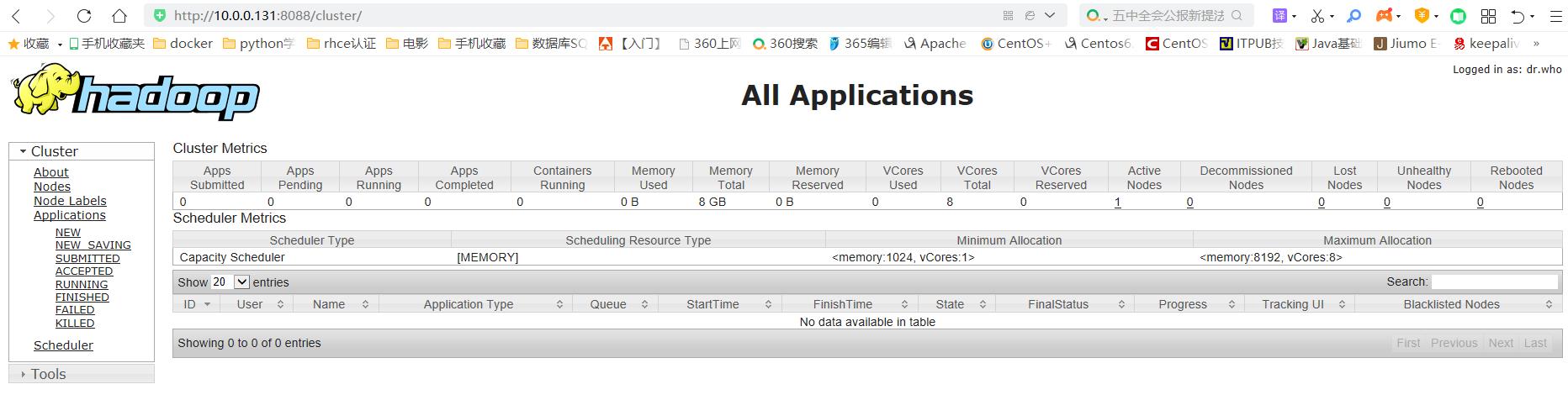
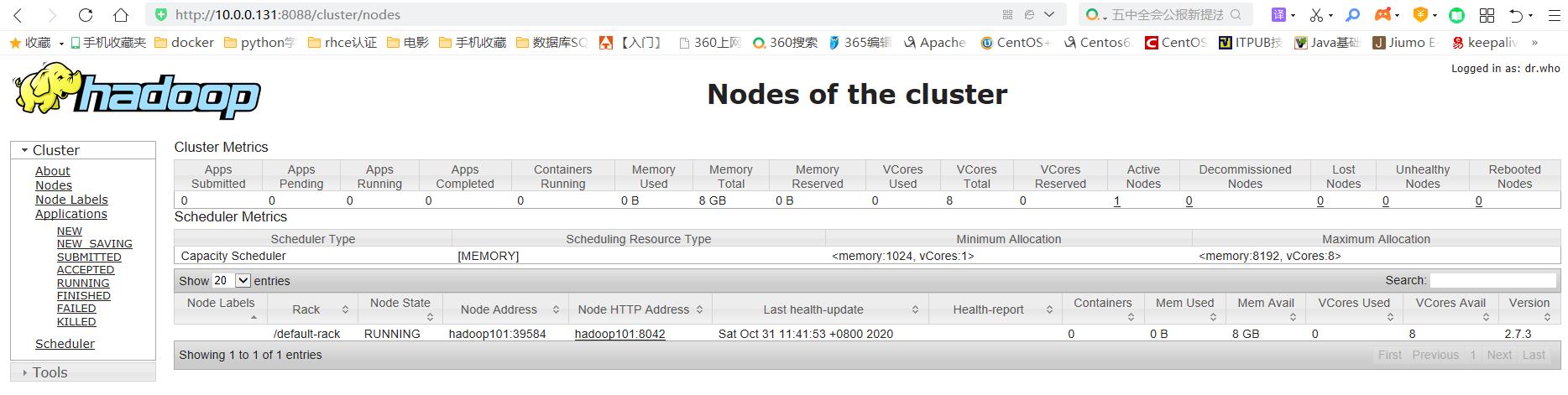
3)完全分布式
a.虚拟机准备
192.168.0.231 hadoop100 192.168.0.67 hadoop101 192.168.0.224 hadoop102
b.设置host(每台主机都设置)
[root@hadoop101 ~]# vim /etc/hosts [root@hadoop101 ~]# cat /etc/hosts ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 192.168.0.231 hadoop100 192.168.0.67 hadoop101 192.168.0.224 hadoop102
c.配置ssh免密登陆
[root@hadoop100 ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa Generating public/private rsa key pair. Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:ICTqNaED9KkO30osSsa2prTPKQh/ju3CvLPSFZLNcEY root@hadoop101 The key's randomart image is: +---[RSA 2048]----+ |o..oE | |..+o= | |.o %. . | |. * =. . | |.o . . S | |=o .. | |+%+.. | |O=@+o | |=+B%+ | +----[SHA256]-----+ [root@hadoop100 ~]# ssh-copy-id 192.168.0.67 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host '192.168.0.67 (192.168.0.67)' can't be established. ECDSA key fingerprint is SHA256:2SoZqpuaEJKIuDV64Hydg+892ggDkDkYAASKS0QFC5o. ECDSA key fingerprint is MD5:3d:a5:c5:95:b9:43:f7:3e:e1:3f:63:d0:57:0b:14:25. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@192.168.0.67's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh '192.168.0.67'" and check to make sure that only the key(s) you wanted were added. [root@hadoop100 ~]# ssh-copy-id 192.168.0.224 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host '192.168.0.224 (192.168.0.224)' can't be established. ECDSA key fingerprint is SHA256:kKoP8PDUCMrFswXVR+xlX6uzwrM/b69911yWEeykBmg. ECDSA key fingerprint is MD5:37:ab:d1:42:70:60:f9:94:7e:03:02:af:9a:f8:95:9f. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@192.168.0.224's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh '192.168.0.224'" and check to make sure that only the key(s) you wanted were added.
#验证
[root@hadoop100 ~]# ssh root@192.168.0.67 Last login: Tue Nov 3 21:42:15 2020 from 192.168.0.231 [root@hadoop101 ~]# exit logout Connection to 192.168.0.67 closed. [root@hadoop100 ~]# ssh root@192.168.0.224 Last login: Tue Nov 3 21:14:02 2020 from 123.139.40.135 [root@hadoop102 ~]# exit logout Connection to 192.168.0.224 closed.
d. 配置JAVA_HOME
在/server/tools/hadoop/etc/hadoop目录下的三个脚本 hadoop-env.sh yarn-env.sh mapred-env.sh 都需要配置JAVA_HOME变量,全路径: export JAVA_HOME=/home/java/jdk
[root@hadoop100 tools]# cd hadoop/etc/hadoop/ [root@hadoop100 hadoop]# vim hadoop-env.sh [root@hadoop100 hadoop]# vim yarn-env.sh [root@hadoop100 hadoop]# vim mapred-env.sh [root@hadoop100 hadoop]# grep JAVA_HOME hadoop-env.sh # The only required environment variable is JAVA_HOME. All others are # set JAVA_HOME in this file, so that it is correctly defined on export JAVA_HOME=/server/tools/jdk [root@hadoop101 hadoop]# grep JAVA_HOME yarn-env.sh # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/server/tools/jdk if [ "$JAVA_HOME" = "" ]; then echo "Error: JAVA_HOME is not set." JAVA=$JAVA_HOME/bin/java [root@hadoop100 hadoop]# grep JAVA_HOME mapred-env.sh export JAVA_HOME=/server/tools/jdk
e.集群配置
# core-site.xml
[root@hadoop100 hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop100:8020</value> #HDFS的URI,文件系统://namenode标识:端口号 </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop</value> #namenode上本地的hadoop临时文件夹 </property> </configuration> [root@hadoop100 hadoop]# mkdir -p /data/hadoop
#hdfs-site.xml
[root@hadoop100 hadoop]# vim hdfs-site.xml [root@hadoop100 hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>3</value> #副本个数,配置默认是3,应小于datanode机器数量
</property> </configuration>
#mapred-site.xml
[root@hadoop100 hadoop]# cp mapred-site.xml.template mapred-site.xml [root@hadoop100 hadoop]# vim mapred-site.xml [root@hadoop100 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
#yarn-site.xml
[root@hadoop100 hadoop]# vim yarn-site.xml [root@hadoop100 hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop100</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
#slaves
[root@hadoop100 hadoop]# vim slaves
[root@hadoop100 hadoop]# cat slaves
hadoop101
hadoop102
f.分发配置文件
[root@hadoop100 hadoop]# scp -r /server/tools/hadoop/etc/hadoop/ root@hadoop101:/server/tools/hadoop/etc/
[root@hadoop100 hadoop]# scp -r /server/tools/hadoop/etc/hadoop/ root@hadoop102:/server/tools/hadoop/etc/
g.格式化,启动hadoop
[root@hadoop100 hadoop]# start-all.sh
[root@hadoop100 hadoop]# hdfs namenode -format
h.验证
[root@hadoop100 hadoop]# jps
3825 SecondaryNameNode
3634 NameNode
4245 Jps
3981 ResourceManager
1263 WrapperSimpleApp
[root@hadoop101 tools]# jps 4214 NodeManager 1258 WrapperSimpleApp 4364 Jps 3934 SecondaryNameNode 3774 DataNode
[root@hadoop102 hadoop]# jps 3376 NodeManager 3207 DataNode 3673 SecondaryNameNode 1261 WrapperSimpleApp 3951 Jps


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏