


Linux正则表达式
一、正则表达式的意义
处理大量的字符串
处理文本
通过特殊符号的辅助,让Linux管理员快速过滤、替换、处理所需要的字符串、文本,让工作高效。
二、Linux三剑客
文本处理工具,均支持正则表达式引擎
grep:文本过滤工具(模式:pattern)
sed :stream editor,流编辑器,文本编辑工具
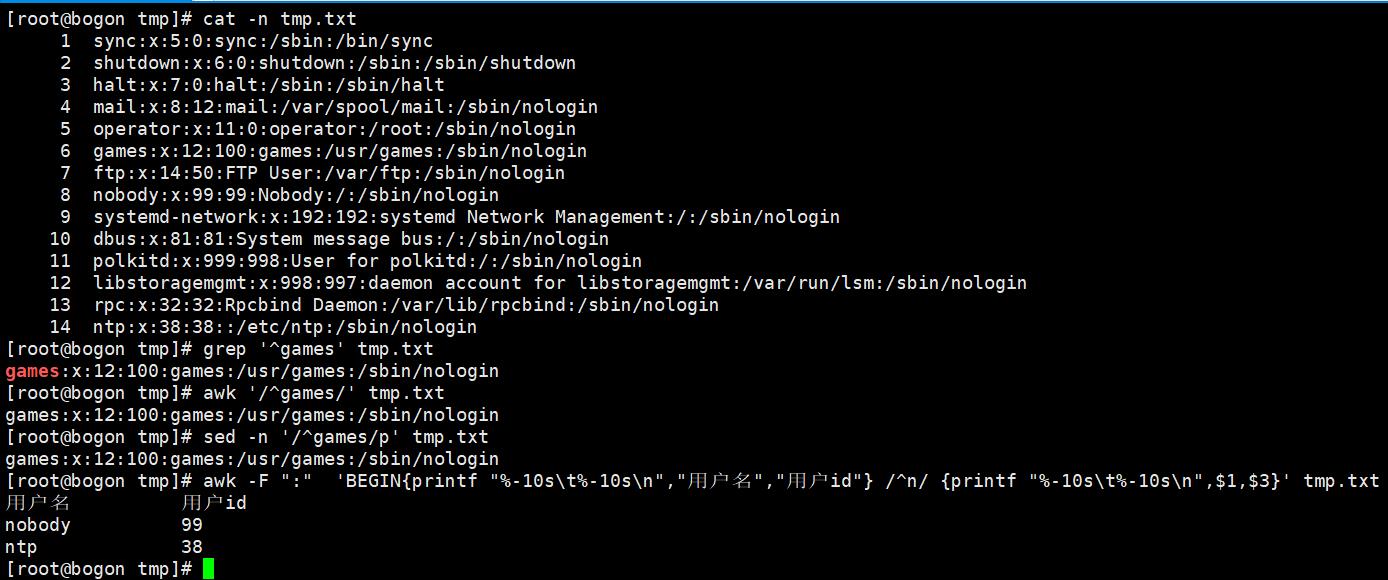
awk :Linux的文本报告生成器(格式化文本),Linux上是gawk
三、基本正则表达式BRE集合
匹配字符
匹配次数
位置瞄定

四、扩展正则表达式ERE集合
扩展正则必须用grep -E才能生效
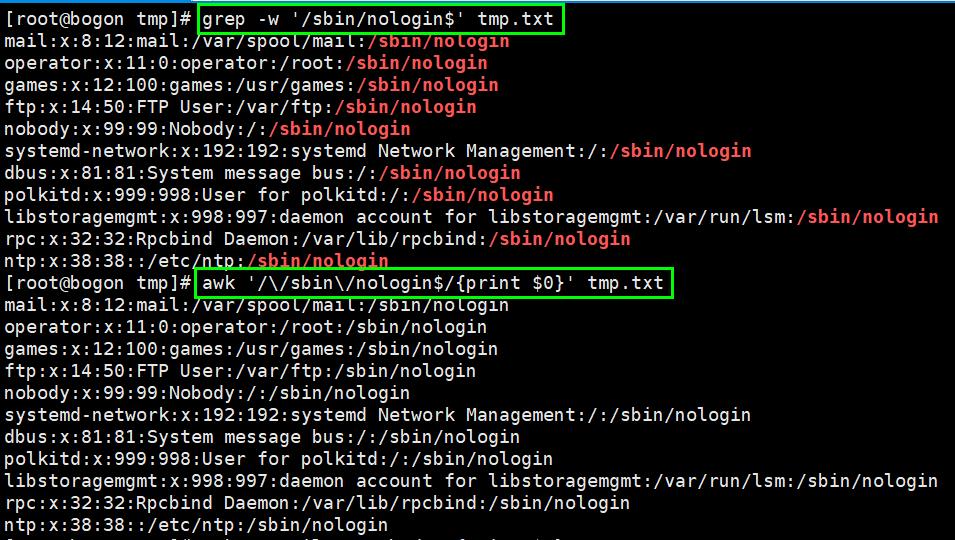
五、grep命令
作用:文本搜索工具,根据用户指定的模式(过滤条件),对目标文本逐行进行匹配检查,打印匹配到的行
模式:由正则表达式的元字符及文本字符所编写的过滤条件。
语法:grep [options] [pattern] file
grep命令实践
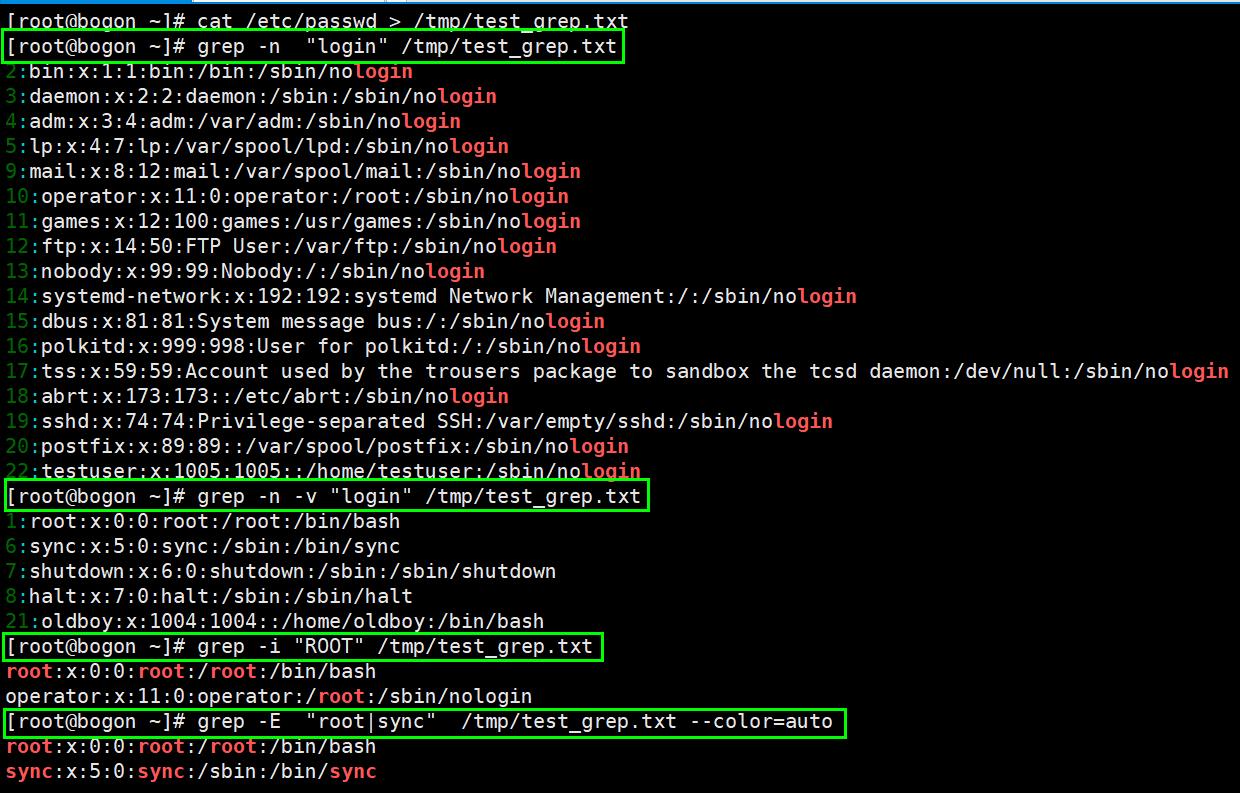
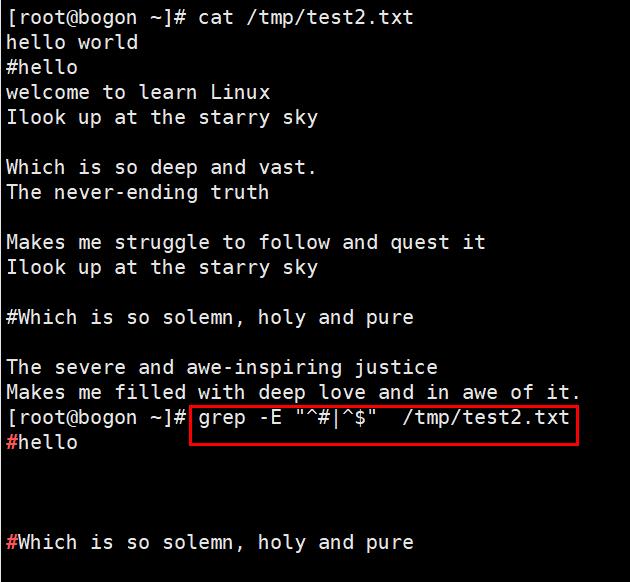
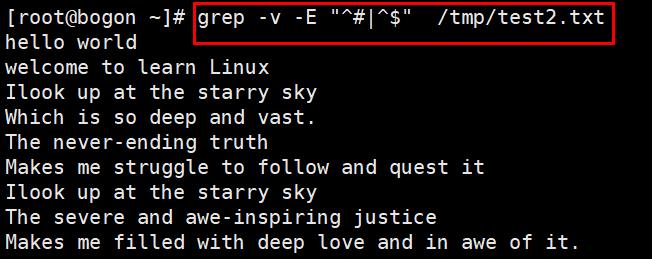
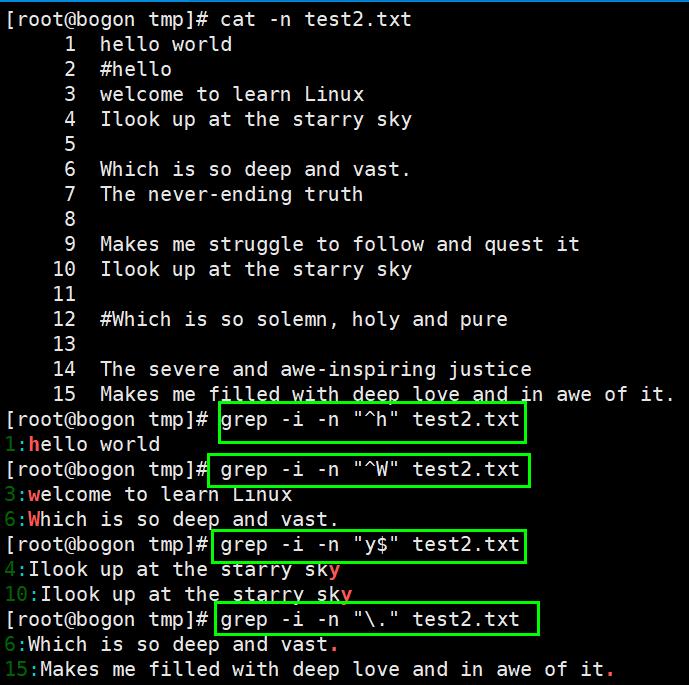
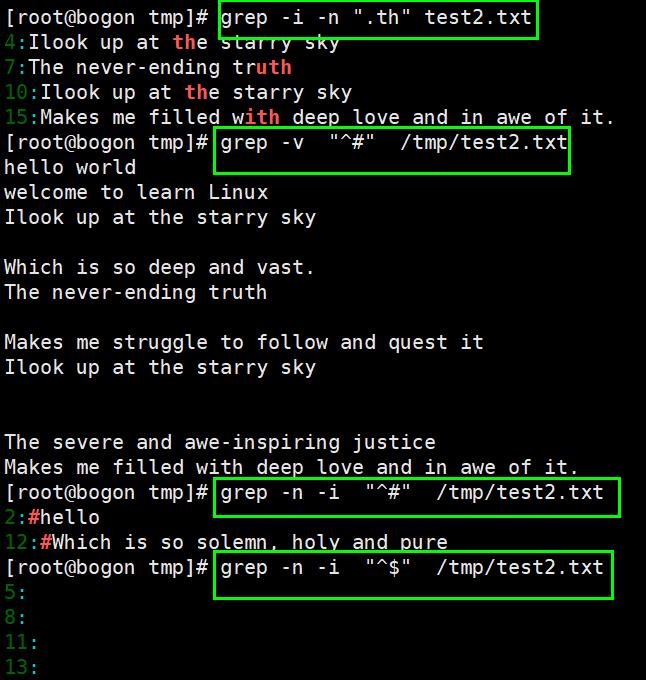
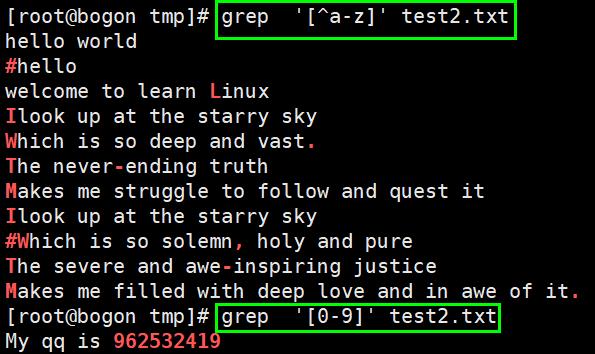
注:^:表示以某字符为开头
.:表示任意0或者多个字符
.* :表示匹配所有内容
.*o:一直到字母o结束(匹配到相同字符到最后一个字符的特点,称之为贪婪匹配)
[a-z]:匹配所有小写单个字母
[A-Z]:匹配所有单个大写字母
[a-zA-Z]:匹配所有的单个大小写字母
[0-9]:匹配所有单个数字
[a-zA-Z0-9]:匹配所有数字和字母
扩展正则表达式grep -E
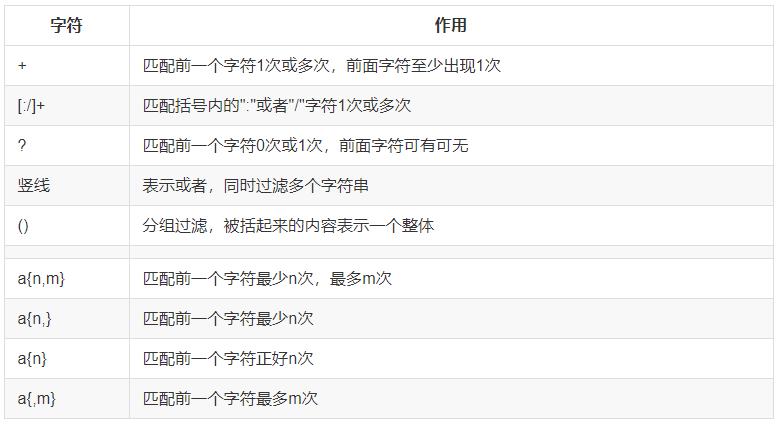
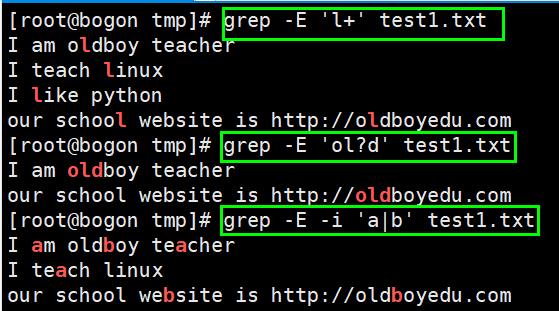
+号:表示匹配前一个字符1次或者多次,必须用grep -E扩展正则
?号:表示匹配前一个字符0次或者1次
| 符:或者的意思
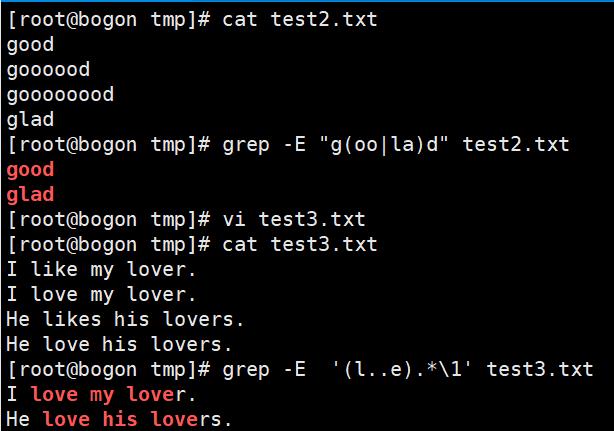
())小括号:将一个或者多个字符捆在一起,当做一个整体进行处理
注:小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
括号()内的内容可以被后面的”\n“正则引用,n表示数字,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符
\2:表示从左侧起,第二个括号中的模式所匹配到的字符
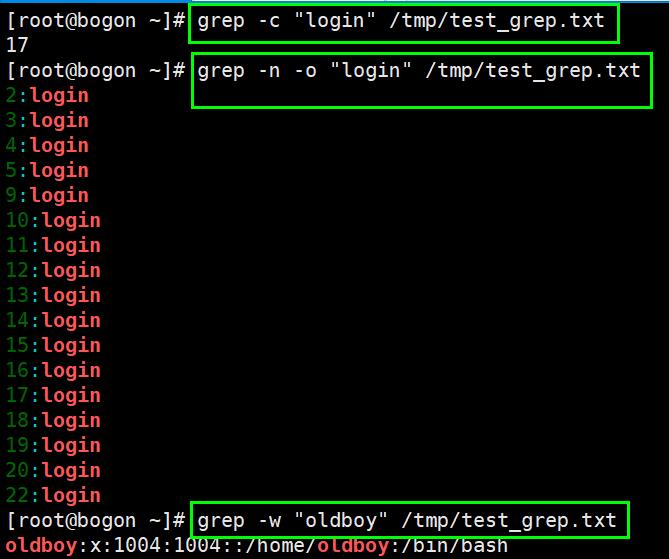
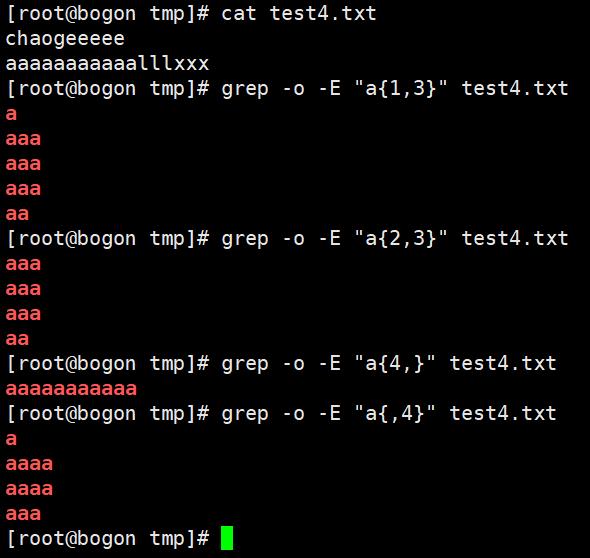
{n,m}匹配次数:重复前一个字符的各种次数,可以通过-o 参数显示明确的匹配过程
六、sed命令
sed是字符流编辑器,简称流编辑器。sed是操作、过滤和转换文本内容的强大工具
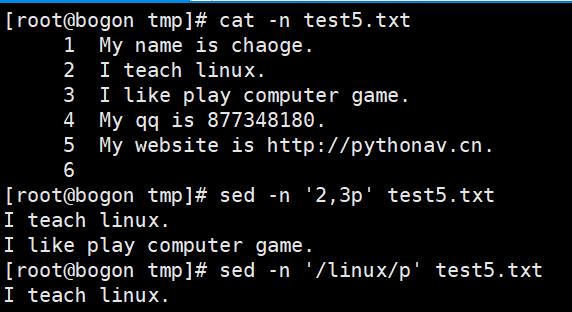
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中,最常用的两大功能是过滤(过滤指定的字符串)、取行(取出指定的行)
语法:sed 【选项】 【sed内置命令】【输入文件】
选项:

内置命令符(用于对文件进行不同的操作功能)

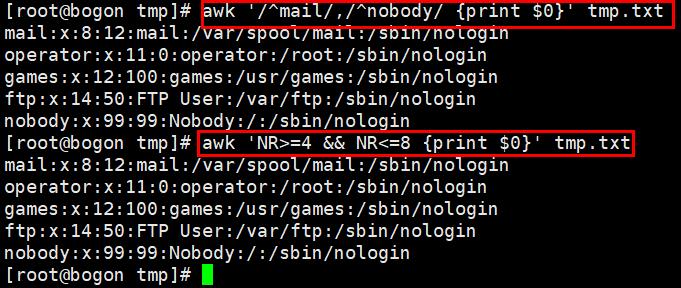
sed匹配的范围
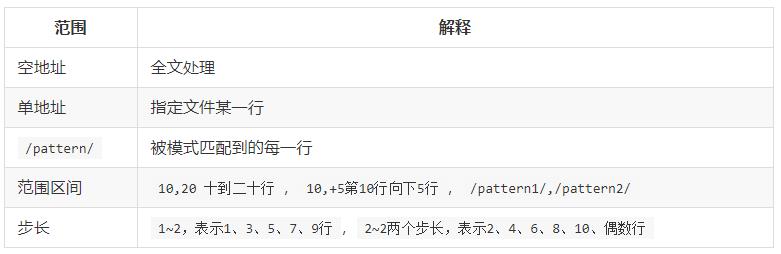
注:sed要实现grep的过滤效果,必须把要过滤的内容放在双斜杠中
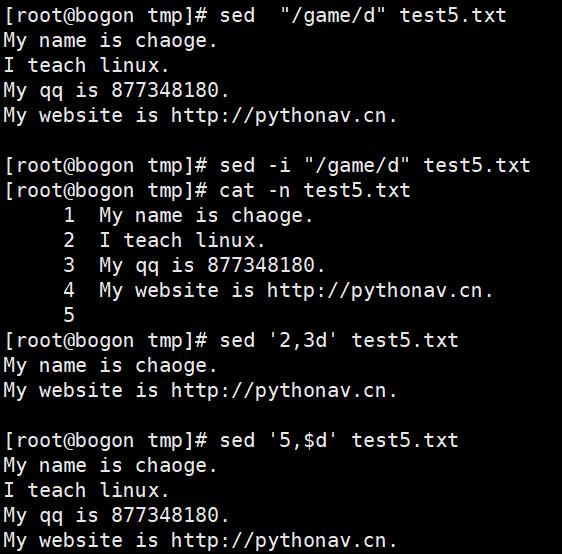
sed想要修改文件内容,必须用参数-i
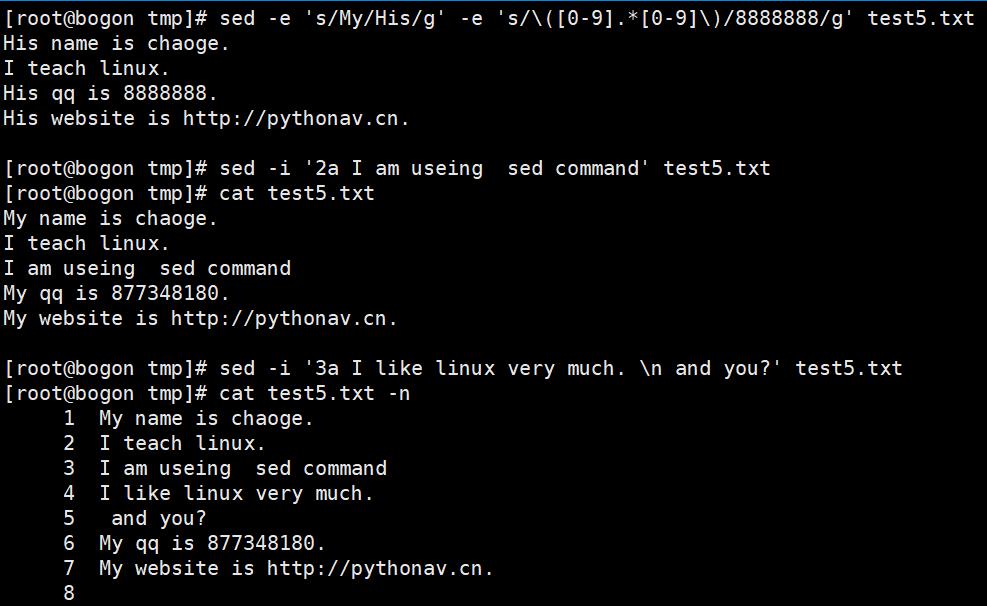
s内置符配合g,代表全局替换,中间的“/”可以替换成“#@/”等
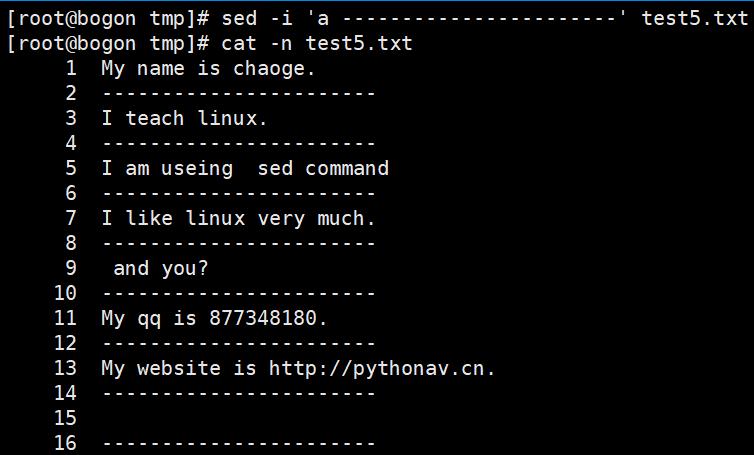
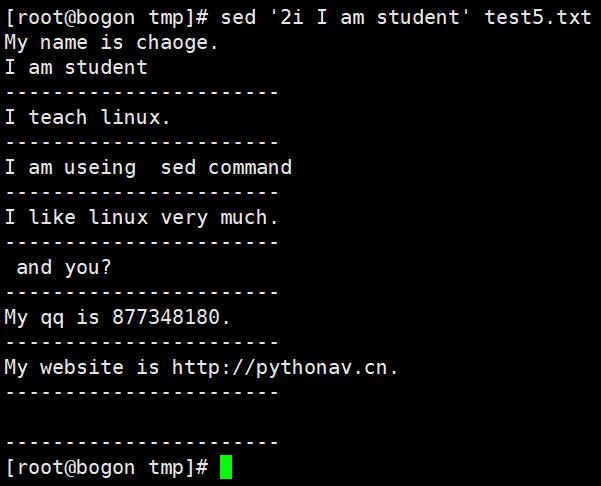
示例:取出Linux的ip 地址(去头去尾法)
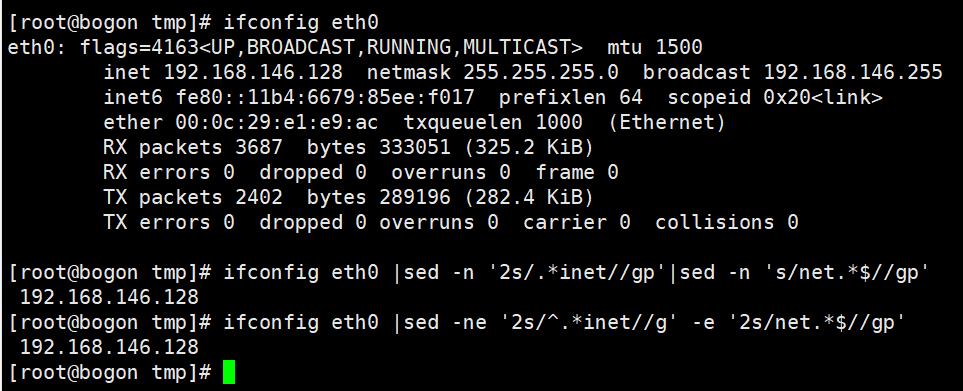
通过shell脚本生成的账号密码格式如下:
svn服务的配置文件中的密码及账号格式如下:
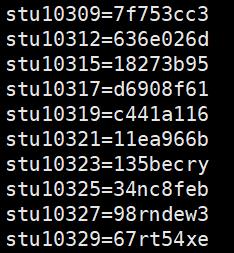
使用sed命令将shell脚本生成的账号密码,转换成SVN服务的配置文件中的账号及密码格式
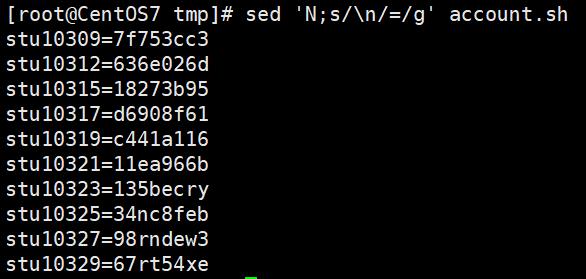
sed内置命令N的作用:不会清空模式空间的内容,并且从输入文件中读取下一行数据,追加到模式空间中,两行数据以换行符\n连接。
七、awk命令
awk有强大的文本格式化的能力。支持条件判断、数组、循环等功能。
grep:擅长单纯的查找或匹配文本内容
awk:更适合编辑、处理匹配到的文本内容
sed :更适合格式化文本内容,对文本进行复杂处理
awk 语法:awk [option] 'pattern[action]' file ...
awk 参数 ‘条件动作’ 文件
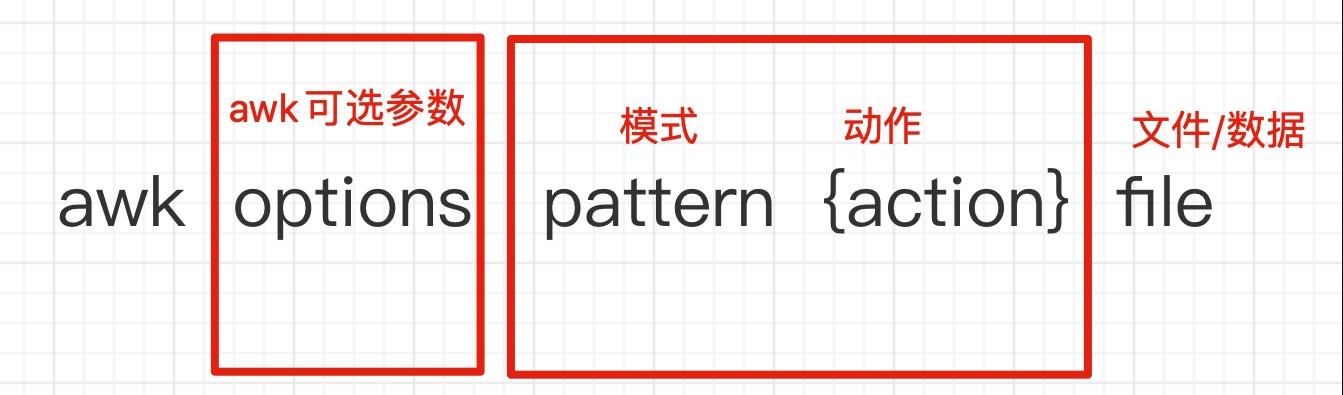
action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作是print和printf
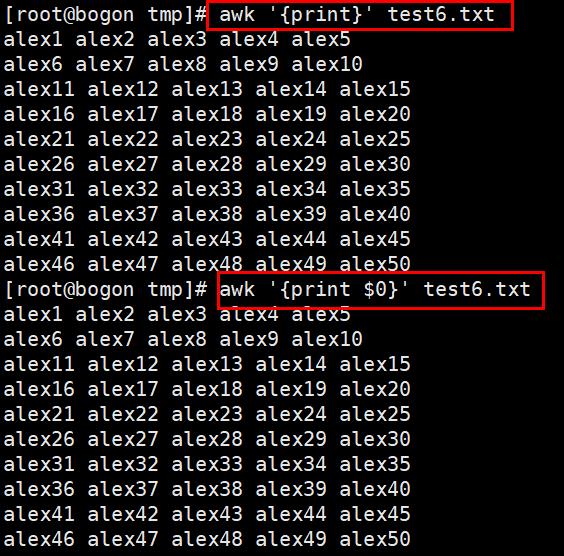
awk 默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符。awk按行处理文件,一行处理完毕,处理下一行,根据用户指定的分隔符工作,没有默认空格。
指定了分隔符后,awk把每一行切割后的数据对应到内置变量中。
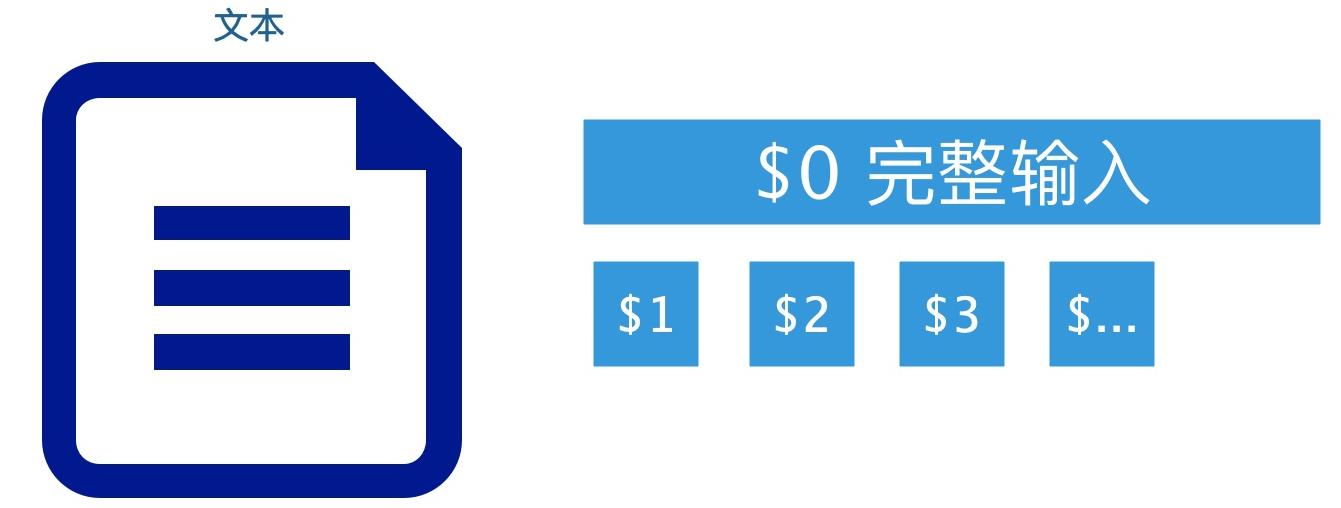
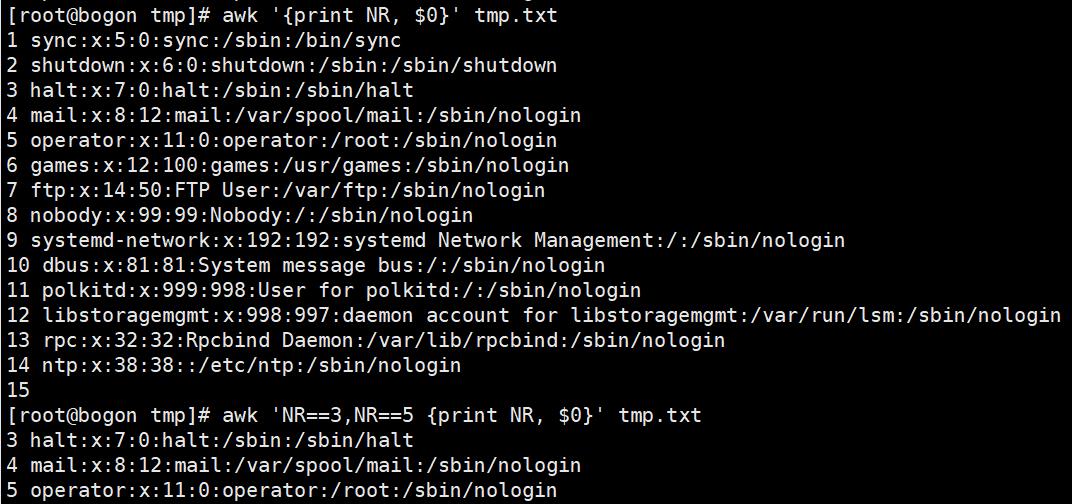
$0:表示整行
$NF:表示当前分割后的最后一列
$(NF-1):表示倒数第二列
1. awk内置变量
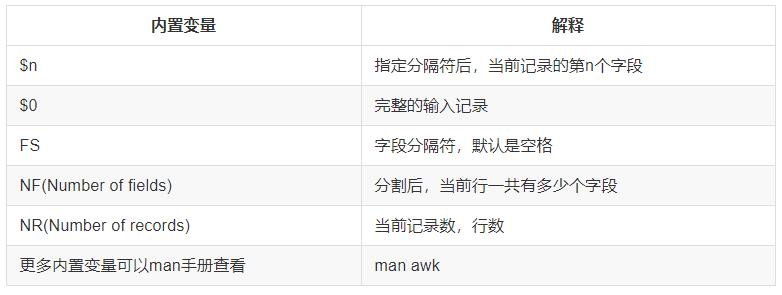
awk可以自动定义输出内容。awk 必须外层单引号,内层双引号。内置变量都不得添加双引号,否则会被识别为文本。
2. awk参数

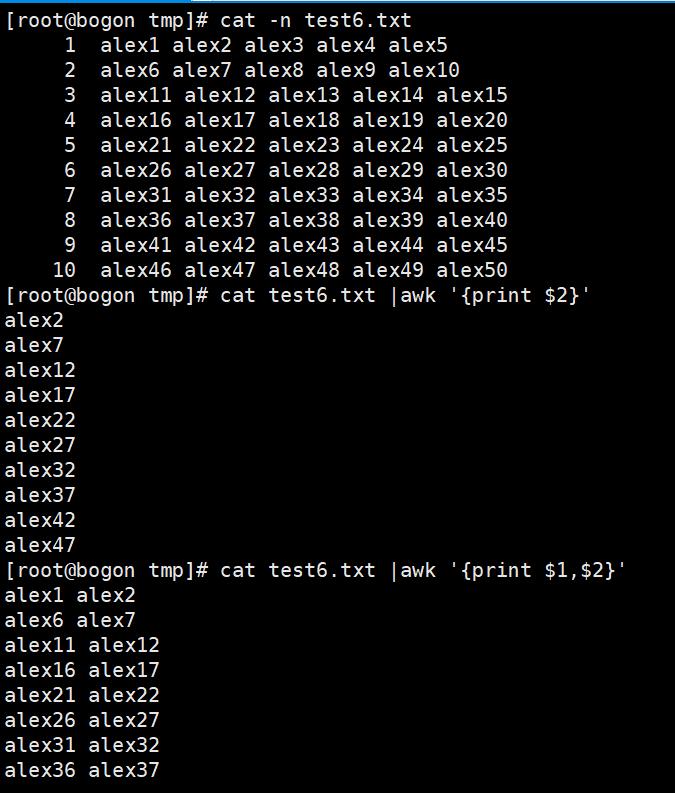
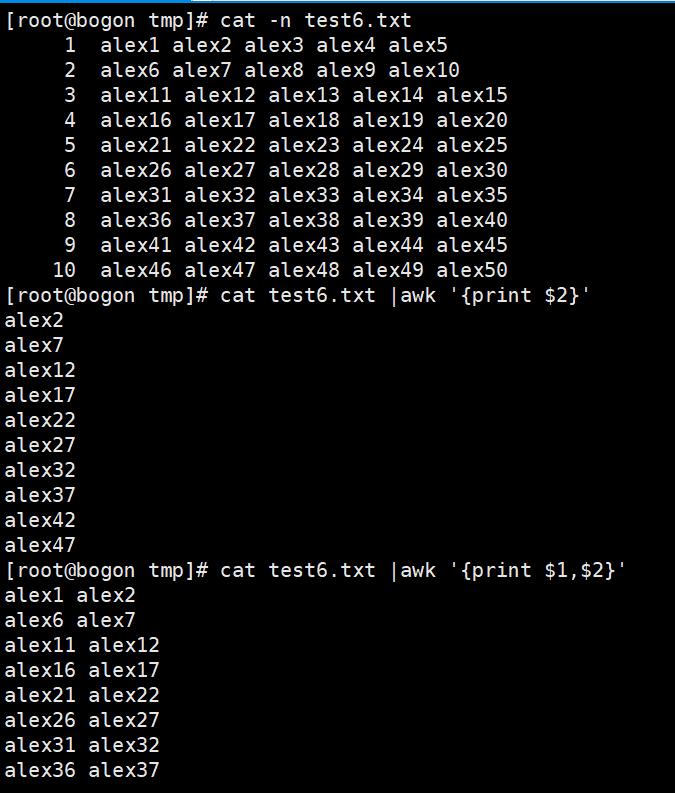
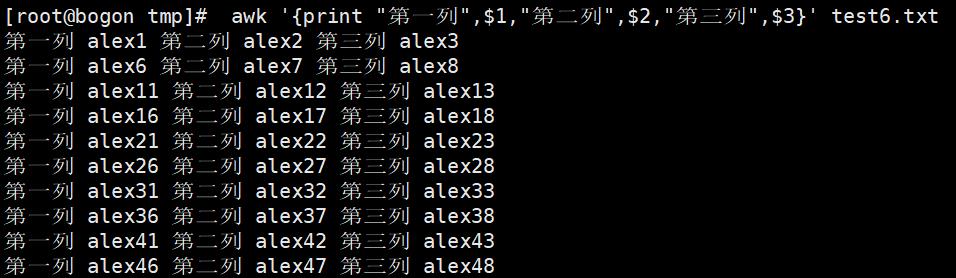
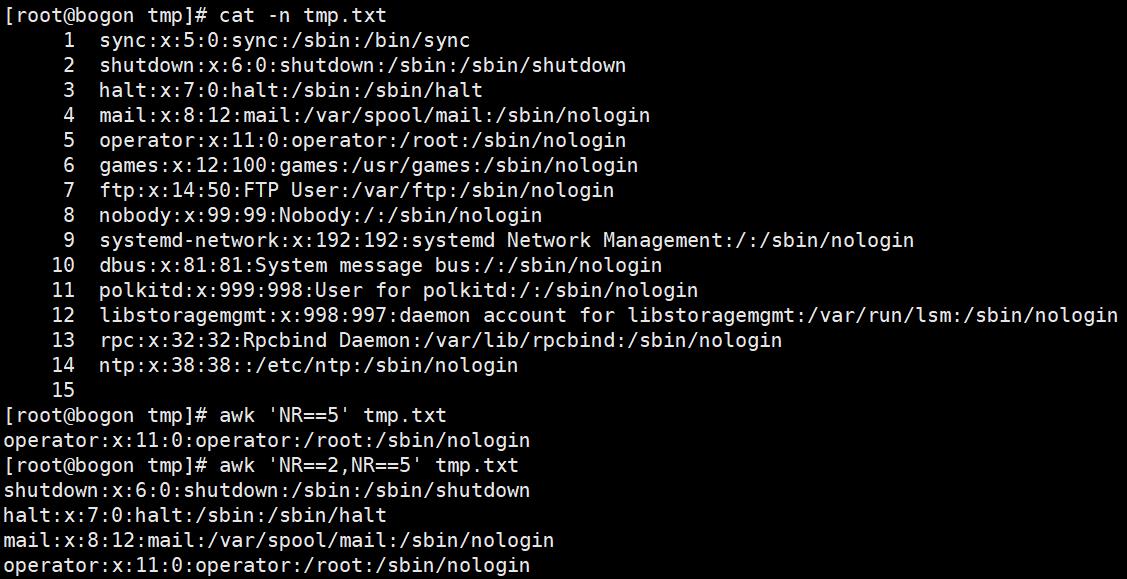
3. awk实践

4. awk分隔符
输入分隔符:awk默认是空格,空白字符,变量名是FS
输出分隔符:简称OFS
处理特殊文件时,如果没有空格,可以自由指定分隔符特点
除了使用-F 选项,还可以使用变量的形式,指定分隔符,使用-v选项搭配,修改FS变量

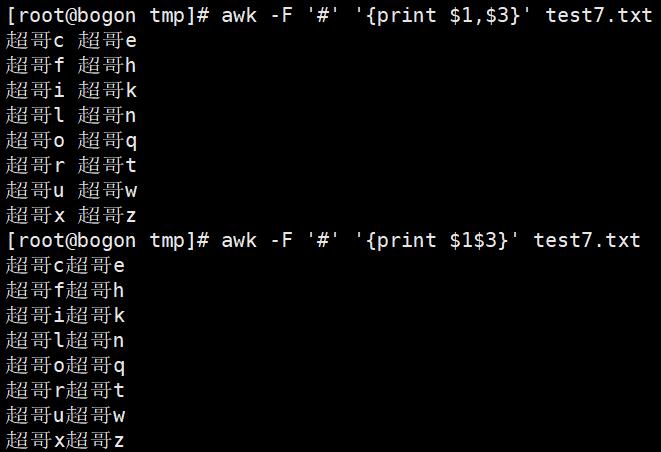
awk 执行完命令,默认用空格隔开每一列,这个空格就是awk的默认输出符
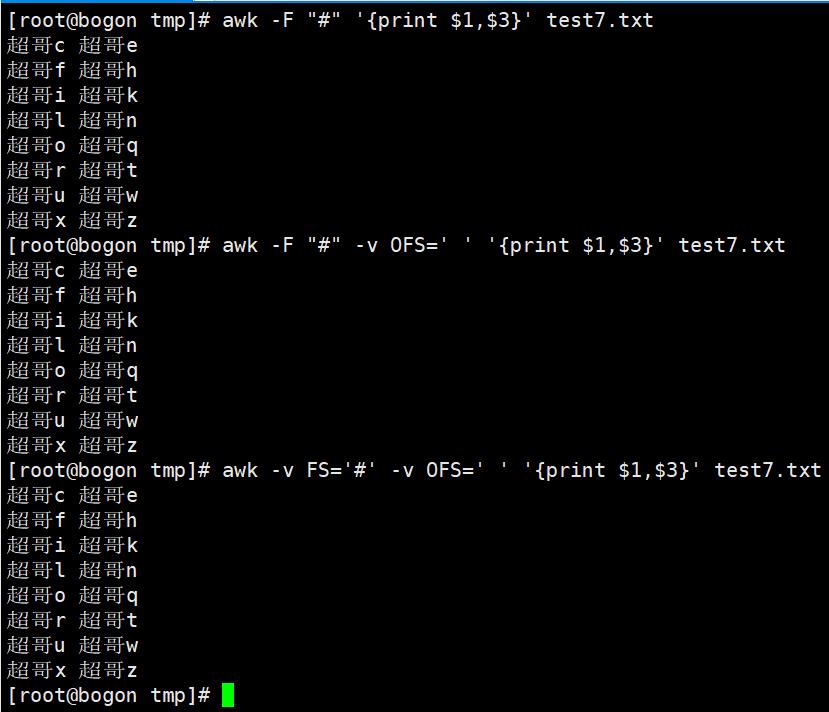
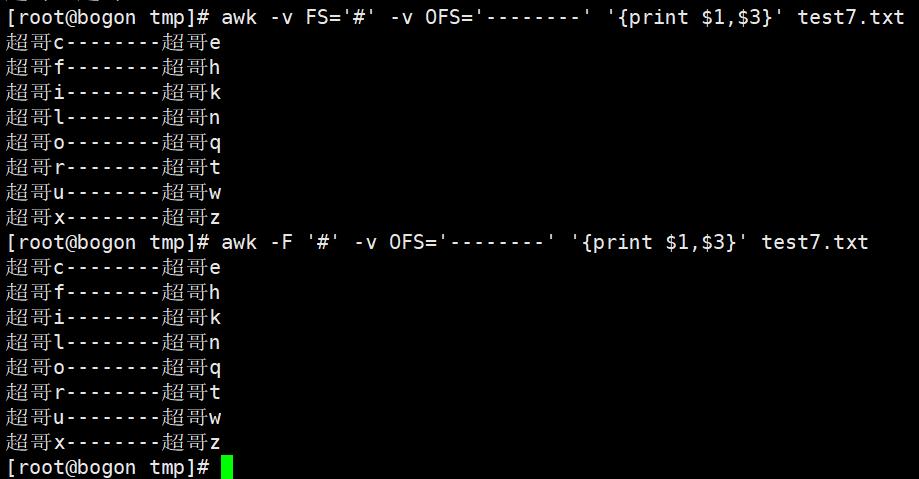
输出分隔符与逗号:awk添加逗号,默认是空格分隔符
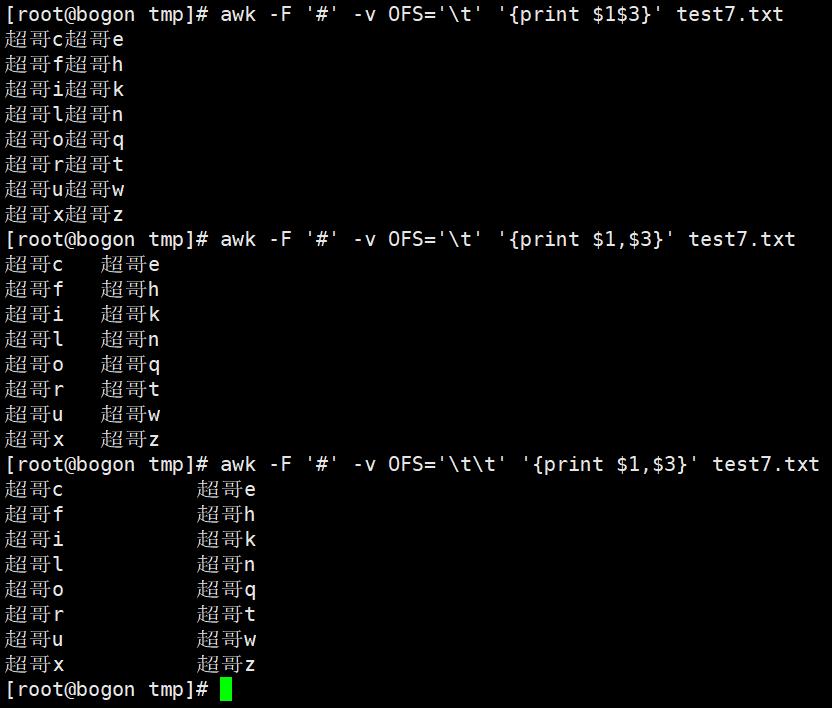
修改分隔符,改为\t(制表符,四个空格)或者任意字符
5. awk变量
awk参数

变量分为:内置变量和自定义变量
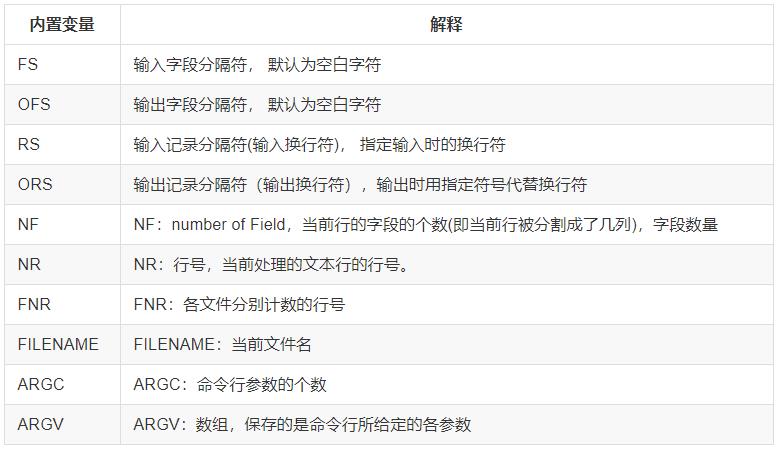
内置变量:NR、NF、FNR,其中NR、NF是不用添加符号$,而$0,$1,$2...是需要添加$符号的
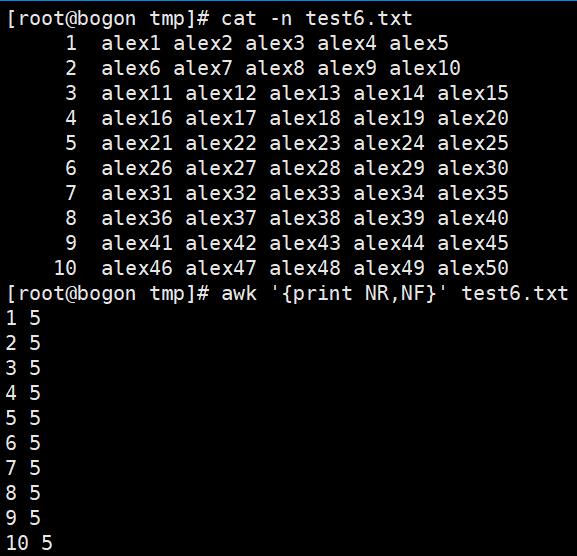
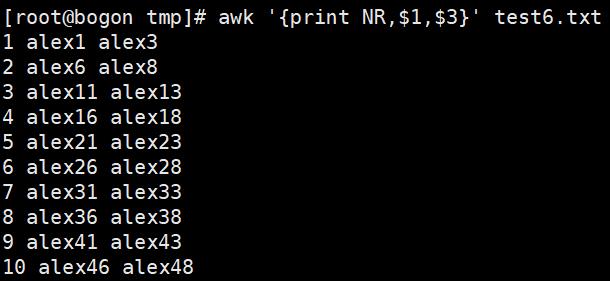
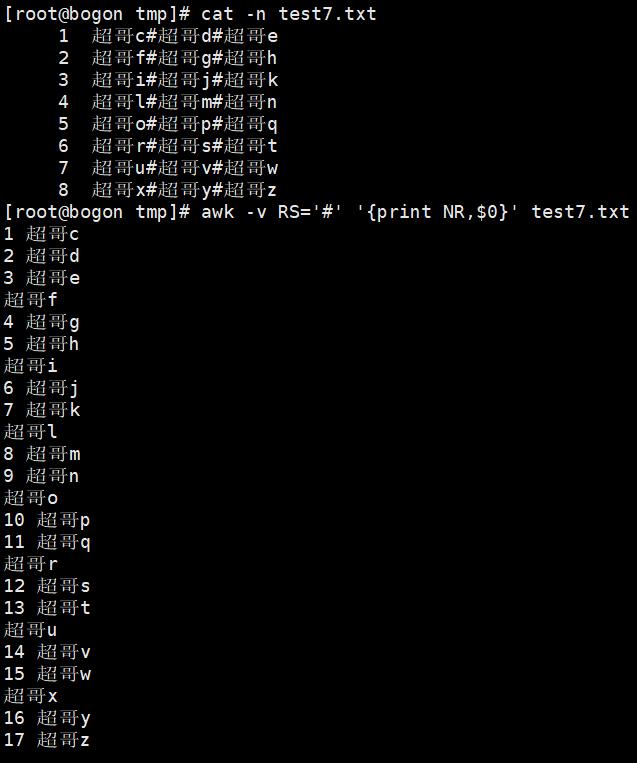
内置变量:RS——RS变量作用是输入分隔符,默认是回车符,也就是换行符。也可以定义#为行分隔符,每遇见一个#,就换行处理。
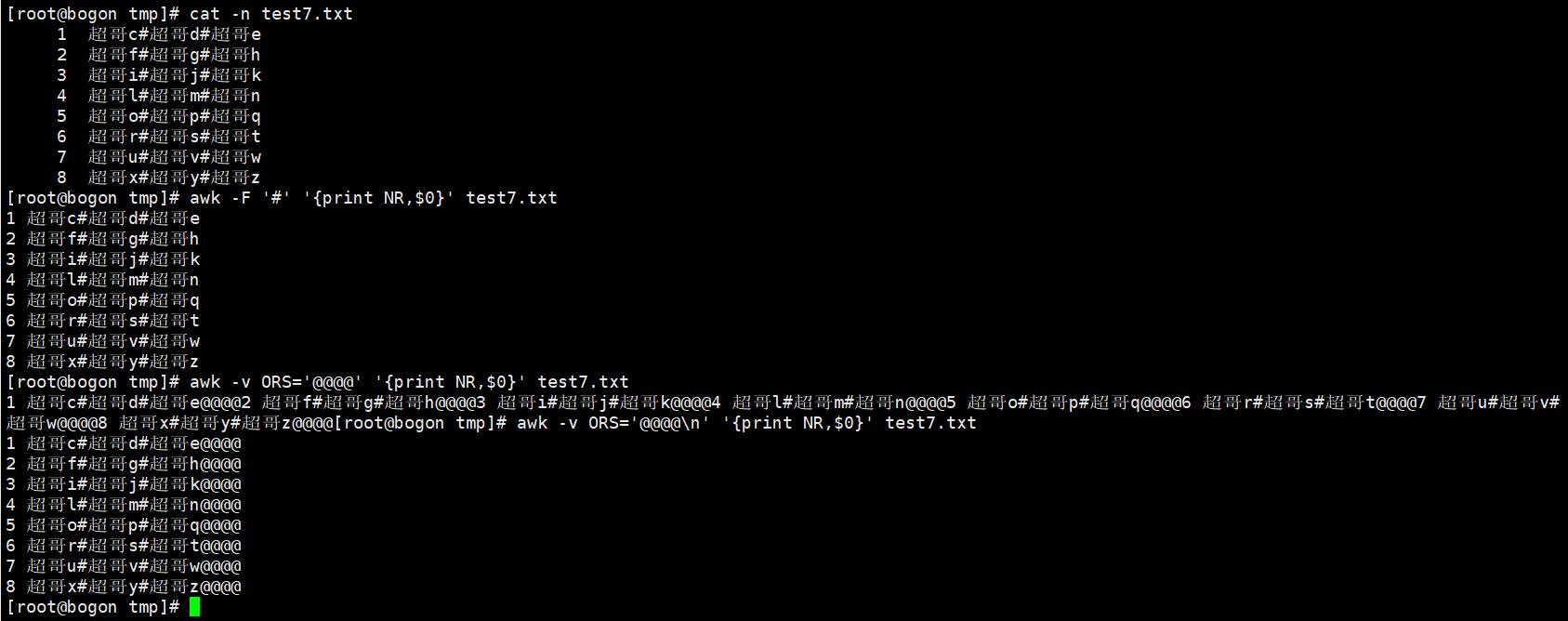
内置变量:ORS—ORS是输出分隔符,awk默认每一行结束了,就得添加回车换行符,ORS可以更改输出符
内置变量FILENAME——显示awk正在处理文件的名字
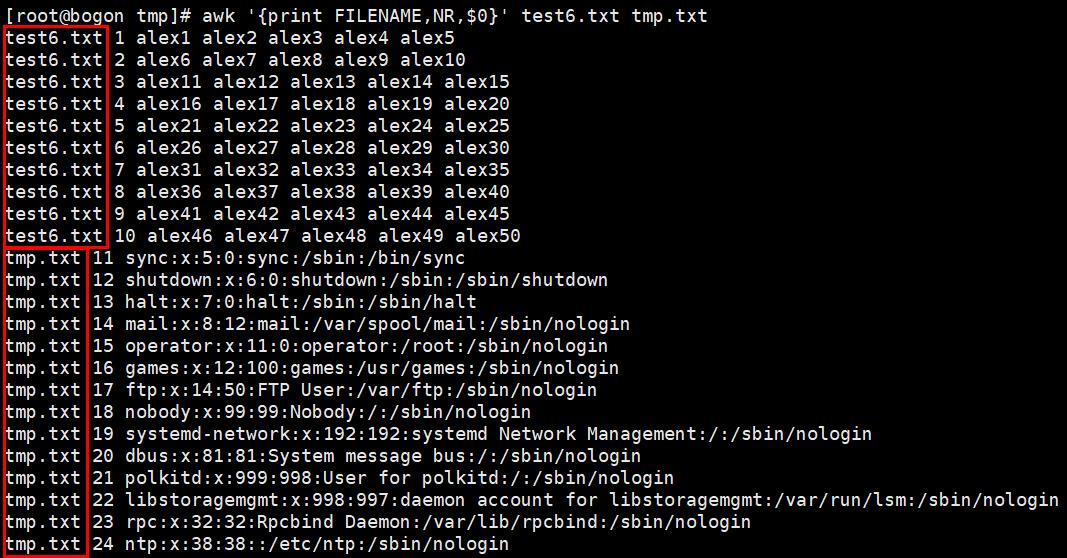
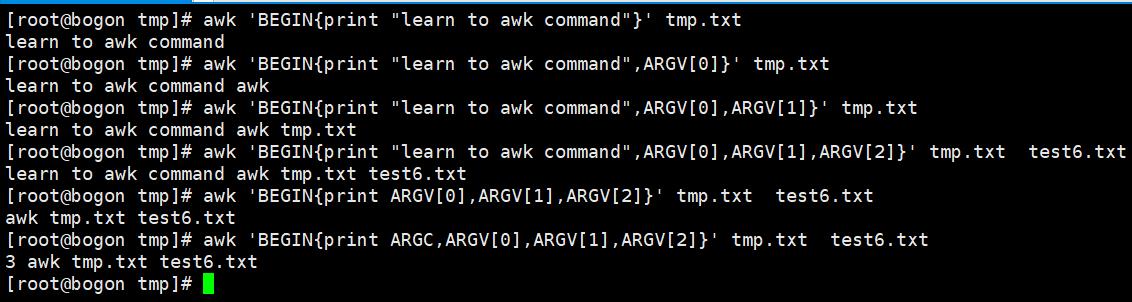
变量ARGC、ARGV——ARGV表示的是一个数组,数组中保存的是命令行所给的参数。
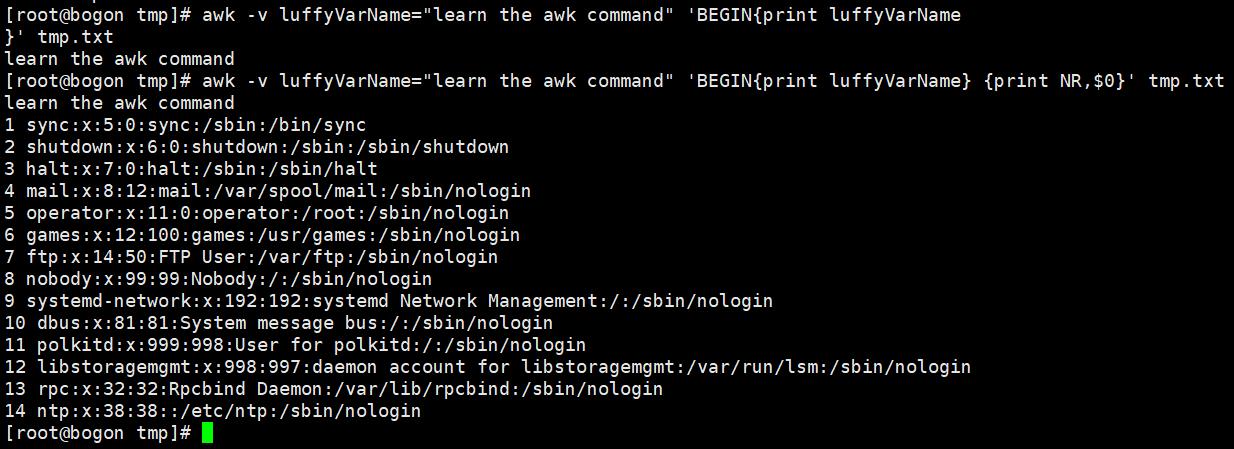
自定义变量:方法一(-v varName=value)方法二,在程序中直接定义

6. awk格式化
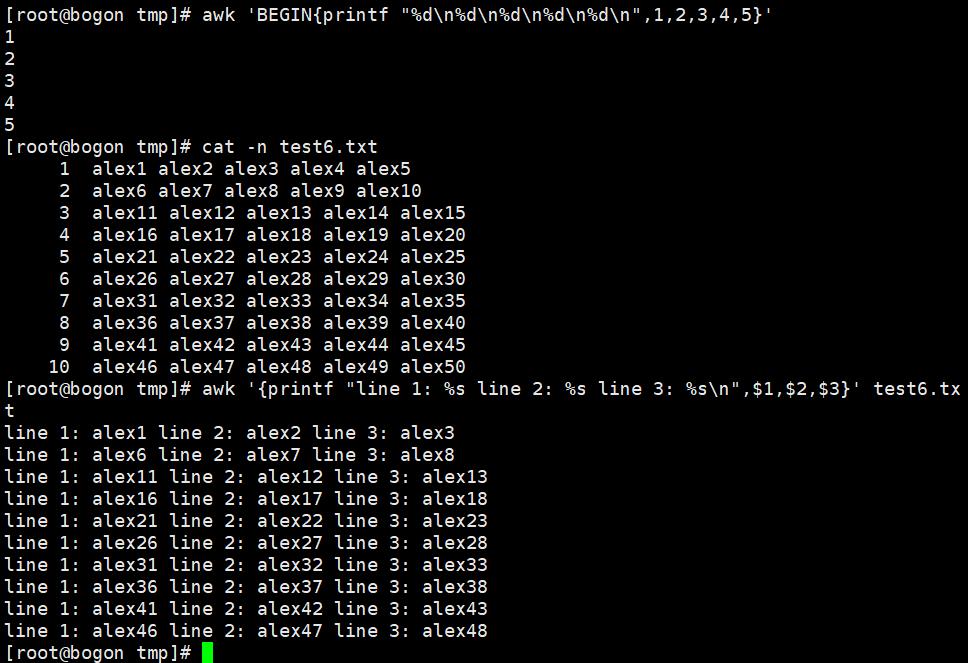
printf格式化输出,需要指定format,format用于指定后面的每个item的输出格式。printf语句不会自动打印出换行符。format格式的指示符都以%开头,后跟一个字符。printf修饰符:-:表示左对齐;默认是右对齐;+:显示数值符号;printf "%+d"
printf对输出的文本不会换行,必须添加对应的格式替换符和\n
使用printf动作,‘{printf "%s\n",$1}’ 替换的格式和变量之间得有逗号。%d %s等替换符必须和被格式化的数据一一对应。
7. awk模式pattern
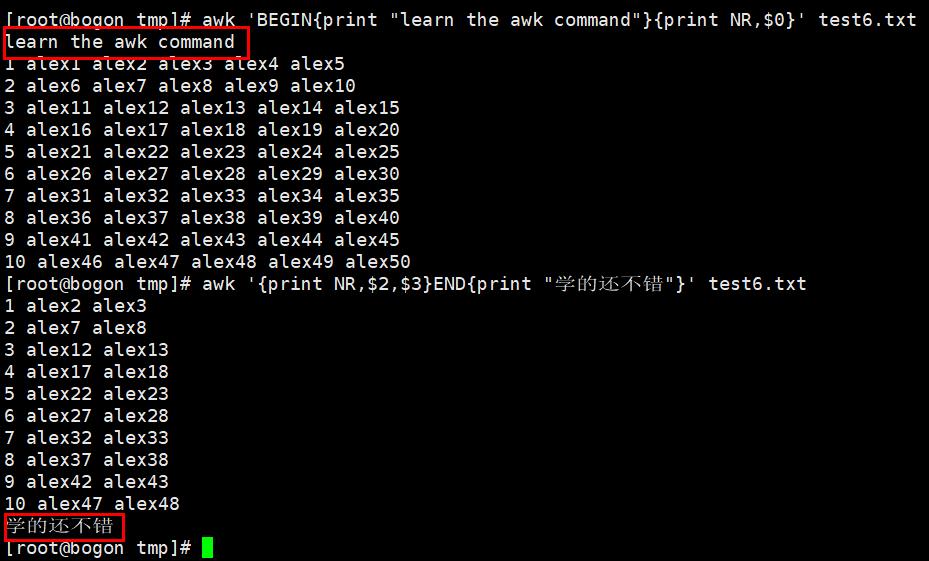
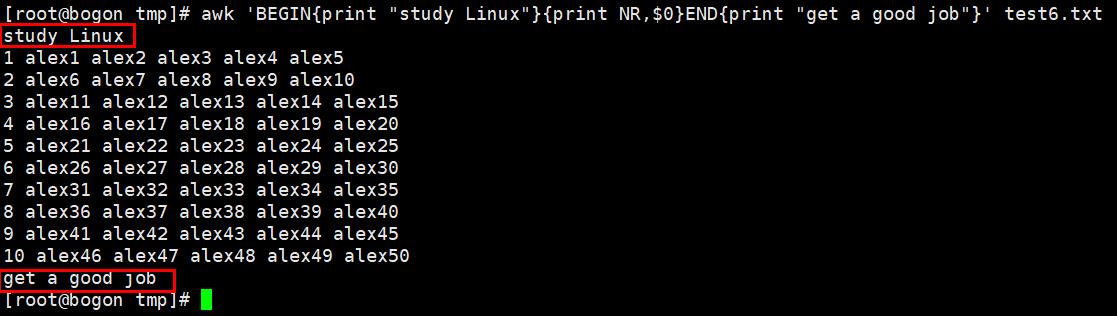
特殊的pattern:BEGIN和END
BEGIN:是处理文本之前需要执行的操作
END:是处理完所有行之后要执行的操作
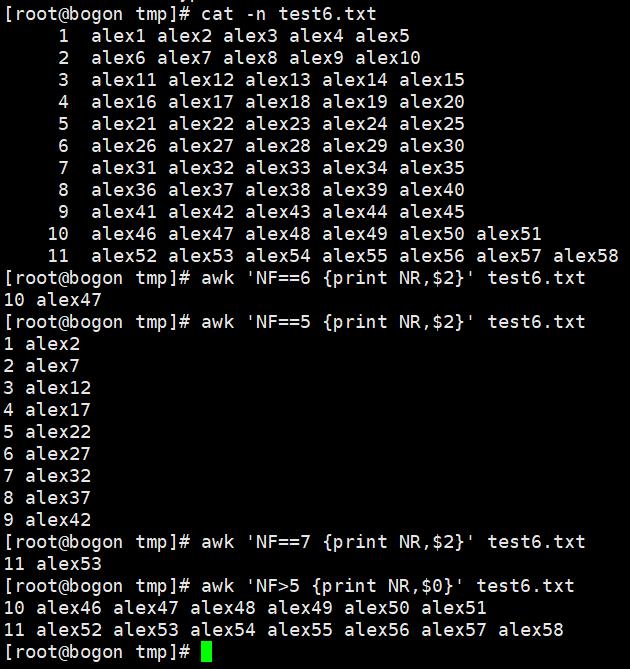
awk默认是按行处理文本,如果不指定任何模式(条件),awk默认一行行处理。如果指定了模式,只符合模式的才会被处理。
awk模式
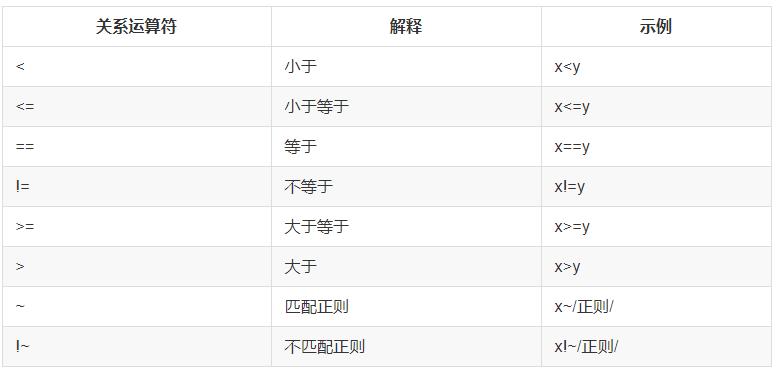
awk和sed命令使用正则表达式,必须把正则放入‘//’中,匹配到结果后执行动作。
awk命令执行流程
awk 'BEGIN{commands} pattern { commands} END{commands} '
优先执行BEGIN{}模式中的语句;然后执行pattern{commands}进行匹配,找到了执行命令;最后当awk读取文件数据流的结尾时,会执行END{commands}
awk实战统计企业nginx日志ip数量
使用awk函数功能实现,将文件中的/sbin/nologin替换成/bin/bash
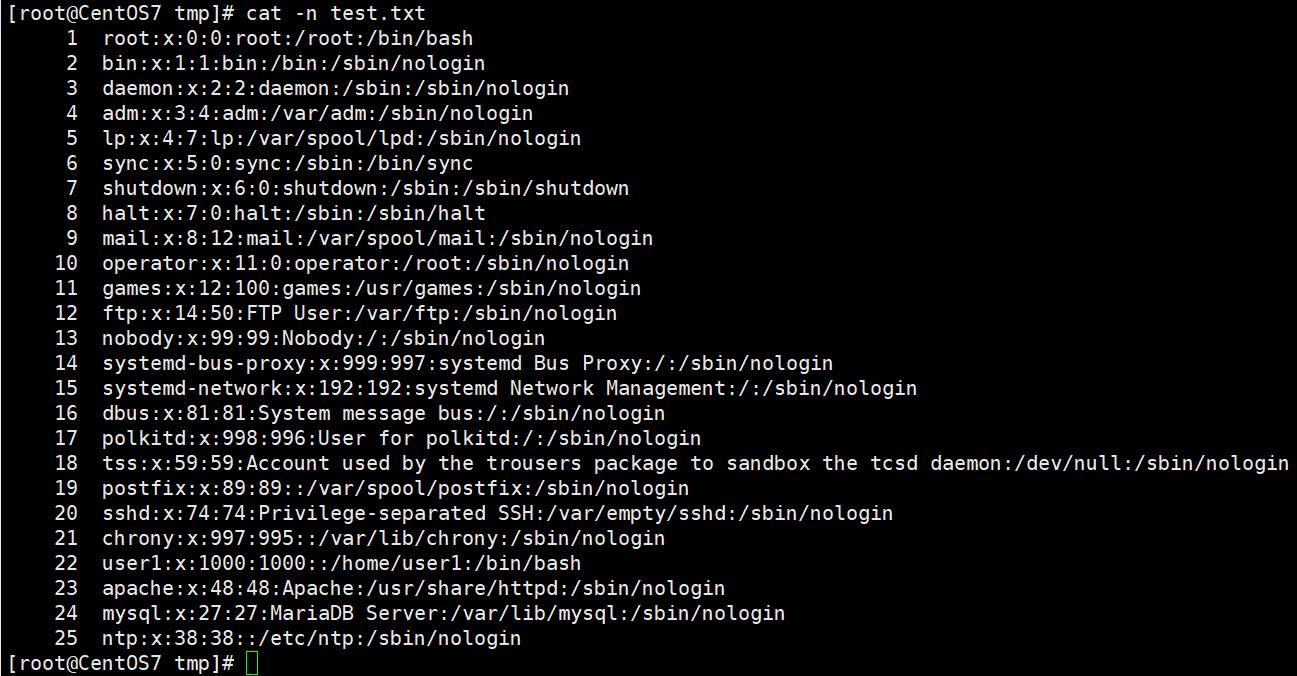
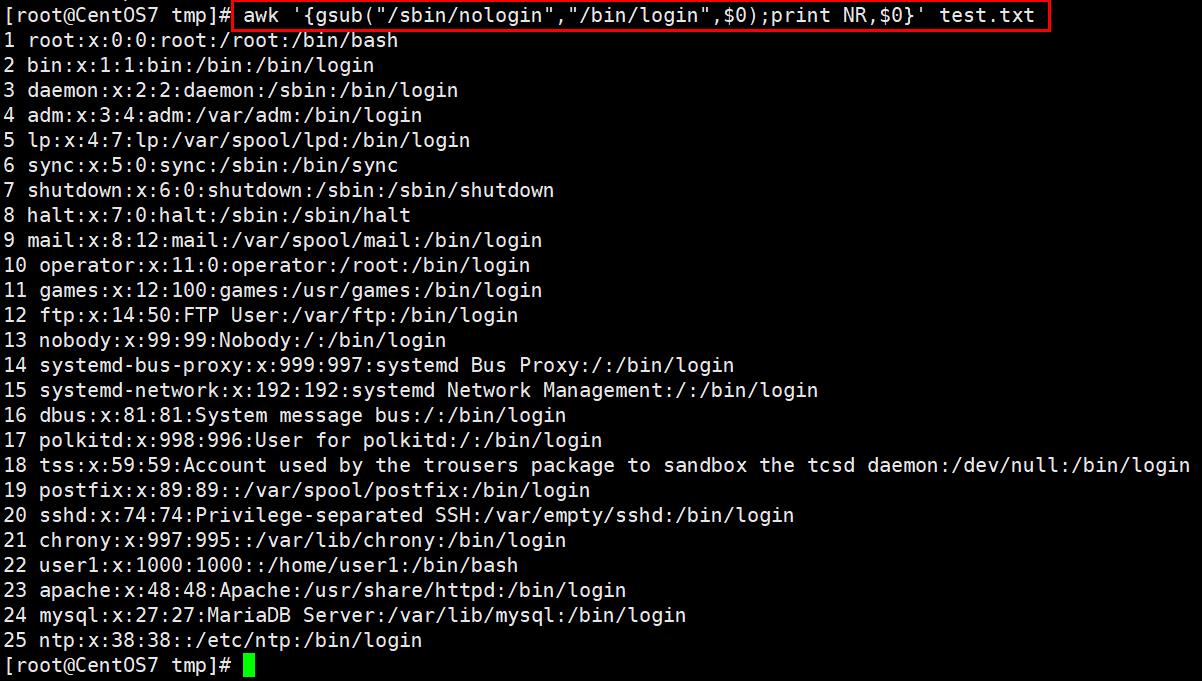
使用了awk里面的查找功能,即gsub函数。
gsub的格式:gsub("替换对象“,”替换成什么内容“,哪一列)
注:
gsub与后面的括号之间不能有空格
替换对象、替换成什么内容以及哪一列之间要用逗号分隔开
替换对象的外面要有双引号或者双斜线包裹起来,即”替换对象“或/替换对象/
替换成什么内容就只能用双引号包裹起来,即”替换成什么内容“
最后一个是哪一列,这个是可以省略的,省略的时候表示要替换整行内容,相当于写上了$0.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏