LLM增强LLM;通过预测上下文来提高文生图质量;Spikformer V2;同时执行刚性和非刚性编辑的通用图像编辑框架
文章首发于公众号:机器感知
LLM增强LLM;通过预测上下文来提高文生图质量;Spikformer V2;同时执行刚性和非刚性编辑的通用图像编辑框架
LLM Augmented LLMs: Expanding Capabilities through Composition
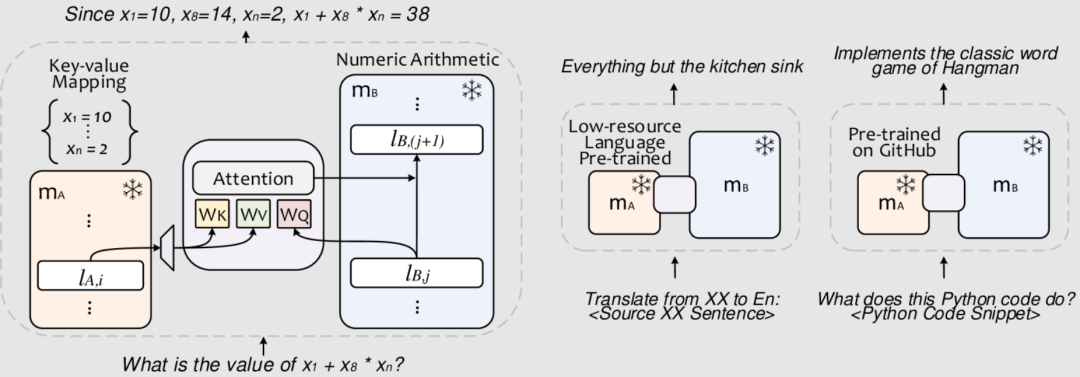
本文研究了如何高效地组合现有的基础模型以实现新功能的问题,文章提出了CALM(Composition to Augment Language Models)方法,通过跨模型注意力机制来组合模型表示,以此实现新功能。CALM的主要特点是:(i) 通过“重用”现有LLM以及一些额外的参数和数据扩展LLM到新任务上;(ii) 保持现有模型权重不变,从而保留现有功能;(iii) 适用于不同领域和场景。将PaLM2-S与一个小模型相结合实现了最高13%的绝对提升,当PaLM2-S与特定代码模型相结合时,在代码生成和解释任务上的相对提升达到了40%,与完全微调后的模型相当。
Improving Diffusion-Based Image Synthesis with Context Prediction

本文提出了一种名为ConPreDiff的扩散模型,该模型通过预测上下文来提高图像生成的语义连接性和质量。ConPreDiff在训练阶段使用一个上下文解码器来强化每个点的预测,但在推理时移除解码器。这一方法可应用于任意离散或连续的扩散backbones,且在无条件图像生成、文本到图像生成和图像补全任务中取得了显著优于之前方法的性能。
Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket
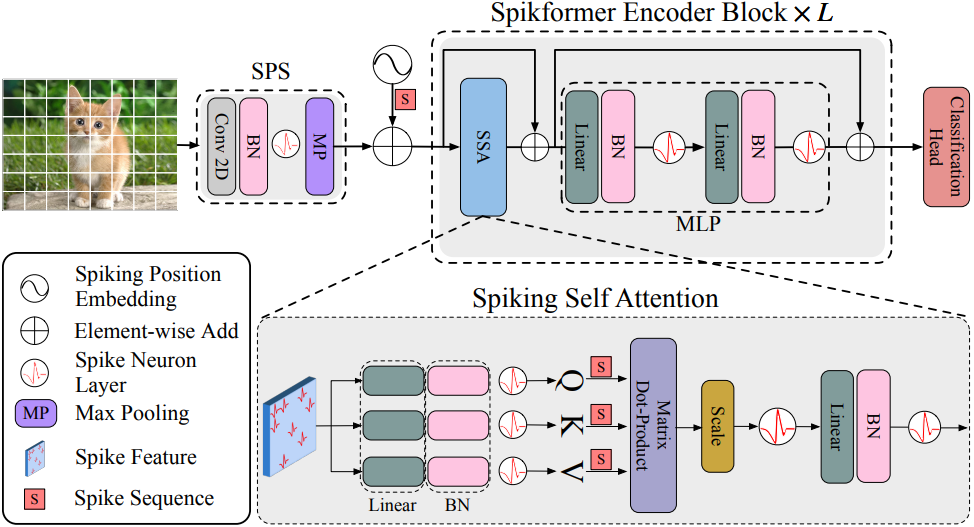
本文提出了一种新型的Spiking神经网络结构,称为Spiking Self-Attention(SSA)和Spiking Transformer(Spikformer),这种结构借鉴了生物神经网络的原理和Transformer的自注意力机制来提高性能。SSA机制通过使用基于脉冲的Query、Key和Value,消除了softmax的需要,并捕获稀疏视觉特征。此外,还开发了一种Spiking Convolutional Stem(SCS)结构来增强Spikformer。为了训练更大更深的Spikformer V2,引入了自监督学习(SSL)方法。实验结果表明,Spikformer V2在性能上优于先前的方法,并首次在ImageNet上实现了80%以上的准确率。
Understanding LLMs: A Comprehensive Overview from Training to Inference
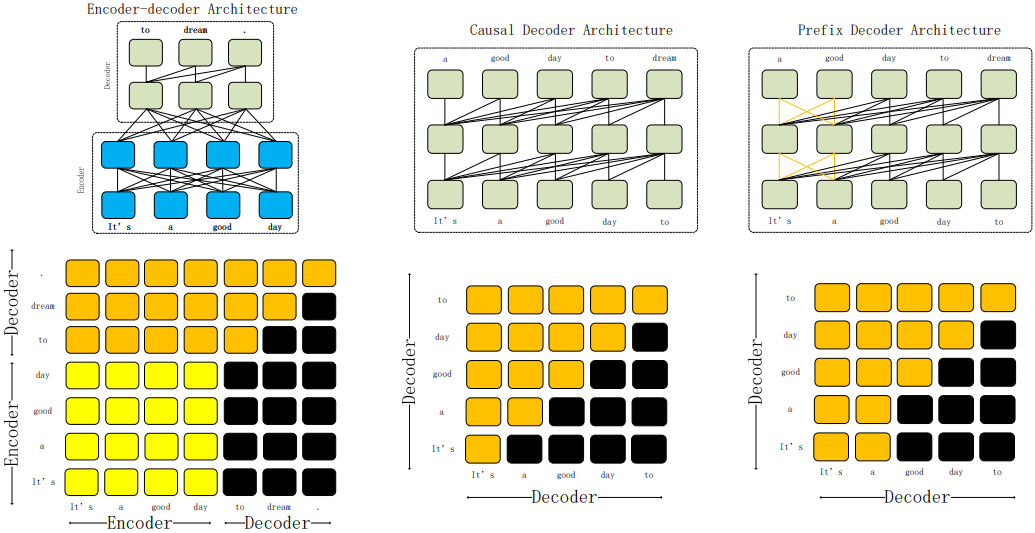
随着ChatGPT的引入,大语言模型(LLMs)在下游任务中的应用显著增加,低成本训练和部署成为未来发展趋势。本文回顾了大语言模型训练技术和推理部署技术的演变,并探讨了模型压缩、并行计算、内存调度和结构优化等主题。同时,本文还探索了LLMs的应用,并对其未来发展提供了见解。
Unified Diffusion-Based Rigid and Non-Rigid Editing with Text and Image Guidance

现有的文本到图像编辑方法在刚性或非刚性编辑方面表现优秀,但在结合两者时却无法得到与文本提示对齐的输出。为了解决这些问题,本文提出了一种能够执行刚性和非刚性编辑的通用图像编辑框架。该方法利用双路径注入方案来处理各种编辑场景,并引入集成的自注意力机制来融合外观和结构信息。为了减少潜在的视觉伪影,还采用了潜码融合技术来调整中间潜码。与现有方法相比,该方法在实现精确和通用图像编辑方面取得了重大进展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号