hadoop三大核心组件
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
(1)HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode/SecondaryNameNode。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(3)MapReduce:它其实是一个应用程序开发包。
一、HDFS
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。架构如下图:
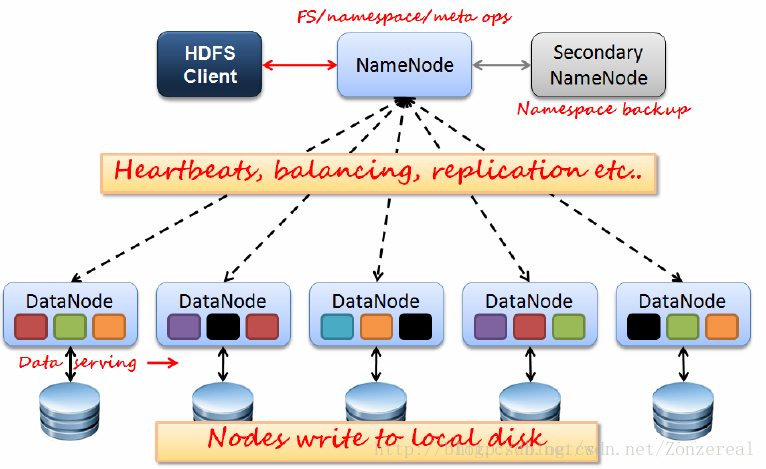
A、NameNode
一般情况下,单namenode集群的最大集群规模为4000台
NameNode负责:文件元数据信息的操作以及处理客户端的请求
NameNode管理:HDFS文件系统的命名空间NameSpace。
NameNode维护:文件系统树(FileSystem)以及文件树中所有的文件和文件夹的元数据信息(matedata)
维护文件到块的对应关系和块到节点的对应关系
NameNode文件:namespace镜像文件(fsimage),操作日志文件(edit log)
这些信息被Cache在RAM中,当然这两个文件也会被持久化存储在本地硬盘。
NameNode记录:每个文件中各个块所在的数据节点的位置信息。
但它并不永久保存块的位置信息,因为这些信息在系统启动时由数据节点重建。
从数据节点重建:在nameNode启动时,DataNode向NameNode进行注册时发送给NameNode1、NameNode元数据信息
文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个文件的块列表。
以及列表中的块与块所在的DataNode之间的地址映射关系
在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、block、datanode之间的映射信息)
数据会定期保存到本地磁盘,但不保存block的位置信息而是由DataNode注册时上报和在运行时维护
2、NameNode文件操作
NameNode负责文件元数据的操作
DataNode负责处理文件内容的读写请求,数据流不经过NameNode,会询问它跟那个DataNode联系
3、NameNode职责
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
若接受到心跳信息,NN认为DN工作正常,如果在10分钟后还接受到不到DN的心跳,那么NN认为DN已经宕机
这时候NN准备要把DN上的数据块进行重新的复制。
块的状态报告包含了一个DN上所有数据块的列表,blocks report 每个1小时发送一次
4、NameNode容错机制
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统(NFS)。
第二种方式是运行一个辅助的Namenode(SecondaryNamenode)。 事实上SecondaryNamenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,SecondaryNamenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
5、文件系统元数据的持久化
Namenode上保存着HDFS的名字空间。对于任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来。例如,在HDFS中创建一个文件,Namenode就会在Editlog中插入一条记录来表示;同样地,修改文件的副本系数也将往Editlog插入一条记录。Namenode在本地操作系统的文件系统中存储这个Editlog。整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在Namenode所在的本地文件系统上。
Namenode在内存中保存着整个文件系统的名字空间和文件数据块映射(Blockmap)的映像。这个关键的元数据结构设计得很紧凑,因而一个有4G内存的Namenode足够支撑大量的文件和目录。当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用在内存中的FsImage上,并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。这个过程称为一个检查点(checkpoint)。在当前实现中,检查点只发生在Namenode启动时,在不久的将来将实现支持周期性的检查点。
Datanode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息。它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。Datanode并不在同一个目录创建所有的文件,实际上,它用试探的方法来确定每个目录的最佳文件数目,并且在适当的时候创建子目录。在同一个目录中创建所有的本地文件并不是最优的选择,这是因为本地文件系统可能无法高效地在单个目录中支持大量的文件。当一个Datanode启动时,它会扫描本地文件系统,产生一个这些本地文件对应的所有HDFS数据块的列表,然后作为报告发送到Namenode,这个报告就是块状态报告。
B、DataNode
存储节点,真正存放数据的节点,用于保存数据,保存在磁盘上(在HDFS上保存的数据副本数默认是3个,这个副本数量是可以设置的)。基本单位是块(block),默认128M。
Block块的概念
先不看HDFS的Block,每台机器都有磁盘,机器上的所有持久化数据都是存储在磁盘上的。磁盘是通过块来管理数据的,一个块的数据是该磁盘一次能够读写的最小单位,一般是512个字节,而建立在磁盘之上的文件系统也有块的概念,通常是磁盘块的整数倍,例如几kb。
HDFS作为文件系统,一样有块的概念,对于分布式文件系统,使用文件块将会带来这些好处:
1.一个文件的大小不限制于集群中任意机器的磁盘大小
2.因为块的大小是固定的,相对比不确定大小的文件,块更容易进行管理和计算
3.块同样方便进行备份操作,以提高数据容错性和系统的可靠性
为什么HDFS的块大小会比文件系统的块大那么多呢?
操作数据时,需要先从磁盘上找到指定的数据块然后进行传输,而这就包含两个动作:
1)数据块寻址:找到该数据块的起始位置
2)数据传输:读取数据
也就是说,操作数据所花费的时间是由以上两个步骤一起决定的,步骤1所花费的时间一般比步骤2要少很多,那么当操作的数据块越多,寻址所花费的时间在总时间中就越小的可以忽略不计。所以块设置的大,可以最小化磁盘的寻址开销。但是HDFS的Block块也不能设置的太大,会影响到map任务的启动数,并行度降低,任务的执行数据将会变慢。
★名词扩展:心跳机制、宕机、安全模式
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
C、SecondaryNameNode
辅助节点,用于同步元数据信息。辅助NameNode对fsimage和edits进行合并(冷备份),下面用SNN代替
NameNode 的元数据信息先往 edits 文件中写,当 edits 文件达到一定的阈值(3600 秒或大小到 64M)的时候,会开启合并的流程。合并流程如下:
①当开始合并的时候,SNN 会把 edits 和 fsimage 拷贝到自己服务器所在内存中,开始合并,合并生成一个名为 fsimage.ckpt 的文件。
②将 fsimage.ckpt 文件拷贝到 NameNode 上,成功后,再删除原有的 fsimage,并将 fsimage.ckpt文件重命名为 fsimage。
③当 SNN 将 edits 和 fsimage 拷贝走之后,NameNode 会立刻生成一个 edits.new 文件,用于记录新来的元数据,当合并完成之后,原有的 edits 文件才会被删除,并将 edits.new 文件重命名为 edits 文件,开启下一轮流程。
二 yarn
首先让我们看一看Yarn的架构

1.ResourceManager概述
是全局的,负责对于系统中的所有资源有最高的支配权。ResourceManager作为资源的协调者有两个主要的组件:Scheduler和ApplicationsManager(AsM)。
Scheduler负责分配最少但满足application运行所需的资源量给Application。Scheduler只是基于资源的使用情况进行调度,并不负责监视/跟踪application的状态,当然也不会处理失败的task。
ApplicationsManager负责处理client提交的job以及协商第一个container以供applicationMaster运行,并且在applicationMaster失败的时候会重新启动applicationMaster。
2.NodeManager概述
NM主要负责启动RM分配给AM的container以及代表AM的container,并且会监视container的运行情况。
在启动container的时候,NM会设置一些必要的环境变量以及将container运行所需的jar包、文件等从hdfs下载到本地,也就是所谓的资源本地化;当所有准备工作做好后,才会启动代表该container的脚本将程序启动起来。
启动起来后,NM会周期性的监视该container运行占用的资源情况,若是超过了该container所声明的资源量,则会kill掉该container所代表的进程。
3.ApplicationMaster概述
由于NodeManager 执行和监控任务需要资源,所以通过ApplicationMaster与ResourceManager沟通,获取资源。换句话说,ApplicationMaster起着中间人的作用。
转换为更专业的术语:AM负责向ResourceManager索要NodeManager执行任务所需要的资源容器,更具体来讲是ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
所以我们看到JobTracker的功能被分散到各个进程中包括ResourceManager和NodeManager:
比如监控功能,分给了NodeManager,和Application Master。
ResourceManager里面又分为了两个组件:调度器及应用程序管理器。
也就是说Yarn重构后,JobTracker的功能,被分散到了各个进程中。同时由于这些进程可以被单独部署所以这样就大大减轻了单点故障,及压力。
最后要提醒在yarn上写应用程序并不同于我们熟知的MapReduce应用程序,必须牢记yarn只是一个资源管理的框架,并不是一个计算框架,计算框架可以运行在yarn上。我们所能做的就是向RM申请container,然后配合NM一起来启动container。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号