flinksql API StreamTableEnvironment StreamStatementSet应用
1.问题描述
在应用flink实时消费kafka数据多端中,一般会使用flink原生的addsink或flinkSQL利用SqlDialect,比如消费kafka数据实时写入hive和kafka一般用两种方式:
第一种方式是写入hive利用SqlDialect,写入kafka利用flink的旁路输出流+原生addSink
第二种方式是写入hive和kafka都利用SqlDialect的方式,将kafka也当作一个刘表
2.第一种方式核心代码及现状
DataStream<String> dataStream = environment.addSource(new FlinkKafkaConsumer(topic, new SimpleStringSchema(), props));
SingleOutputStreamOperator<SipDataInfo> mainStream = dataStream.map(s -> {
SipDataInfo sipDataInfo = new SipDataInfo();
JSONObject jsonObject = SipFullauditMonitor.complex(s);
sipDataInfo.setRow(createRow(jsonObject, size, typeArray, column));
sipDataInfo.setJsonObject(jsonObject);
return sipDataInfo;
});
final OutputTag<SipDataInfo> kafkaOutputTag = new OutputTag<SipDataInfo>("kafka_stream") {
};
final OutputTag<SipDataInfo> hiveOutputTag = new OutputTag<SipDataInfo>("hive_stream") {
};
SingleOutputStreamOperator<SipDataInfo> sideOutputStream = mainStream.process(new ProcessFunction<SipDataInfo, SipDataInfo>() {
@Override
public void processElement(SipDataInfo sipDataInfo, Context context, Collector<SipDataInfo> collector) throws Exception {
context.output(kafkaOutputTag, sipDataInfo);
context.output(hiveOutputTag, sipDataInfo);
}
});
DataStream<SipDataInfo> kafkaStream = sideOutputStream.getSideOutput(kafkaOutputTag);
DataStream<SipDataInfo> hiveStream = sideOutputStream.getSideOutput(hiveOutputTag);
Properties producerProperties = new Properties();
producerProperties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ambari1:6667");
kafkaStream.map(sipDataInfo -> sipDataInfo.getJsonObject().toJSONString())
.filter(s -> JSONObject.parseObject(s, SipFullauditMonitor.class).getReftaskid() != null && JSONObject.parseObject(s, SipFullauditMonitor.class).getReftaskid() == 0)
.addSink(new FlinkKafkaProducer<String>("dwd_" + topic, new SimpleStringSchema(), props));
TypeInformation[] tfs = getSqlColumsType(typeArray);
DataStream<Row> hiveOdsSinkDataStream = hiveStream.map(sipDataInfo -> sipDataInfo.getRow())
.returns(Types.ROW_NAMED(column, tfs))
.filter(row -> CommonUtil.filter(row));
setHiveParam(parameter, tableEnv);
Table table = tableEnv.fromDataStream(hiveOdsSinkDataStream);
tableEnv.createTemporaryView("tmp_" + topic, table);
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
tableEnv.executeSql(BaseStreamLaucher.parseCreateTableSqlByColumn("ods_" + topic,column, typeArray,new String[]{"pdate","insterhour"},new String[]{"string","string"}));
//写hive表
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
String insertSql = "insert into ods_" + topic + " PARTITION(pdate='" +
new SimpleDateFormat("yyyy-MM-dd").format(new Date()) +
"') select " + sinkHiveColumnStr + " from tmp_" + topic;
tableEnv.executeSql(insertSql);
environment.execute();
}
}
3.第二种方式实现的核心代码
DataStream<String> dataStream = environment.addSource(new FlinkKafkaConsumer(topic, new SimpleStringSchema(), props));
TypeInformation[] tfs = getSqlColumsType(typeArray);
DataStream<Row> rowDataStream = dataStream.map(s -> createRow(SipFullauditMonitor.complex(s), size, typeArray, column))
.returns(Types.ROW_NAMED(column, tfs))
.filter(row -> CommonUtil.filter(row));
Table table = tableEnv.fromDataStream(rowDataStream);
setHiveParam(parameter, tableEnv);
tableEnv.createTemporaryView("tmp_" + topic, table);
//创建hive表
tableEnv.executeSql(BaseStreamLaucher.parseCreateTableSqlByColumn("ods_" + topic,column, typeArray,new String[]{"pdate","insterhour"},new String[]{"string","string"}));
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
//创建kafka表
tableEnv.executeSql("drop table dwd_sip_fullaudit_monitor");
String kafkaTableSql = createKafkaTableSqlByColumn("dwd_sip_fullaudit_monitor", parameter, column, typeArray);
tableEnv.executeSql(kafkaTableSql);
//写hive表
String insertHiveSql = "insert into ods_" + topic + " PARTITION(pdate='" +
new SimpleDateFormat("yyyy-MM-dd").format(new Date()) +
"',insterhour='" + new SimpleDateFormat("yyyyMMddHH").format(new Date()) + "') select " + sinkHiveColumnStr + " from tmp_" + topic;
//写kafka表
String insertKafkaSql = "insert into dwd_sip_fullaudit_monitor" + " select " + sinkHiveColumnStr + " from " + "tmp_" + topic;
tableEnv.executeSql(insertKafkaSql);
tableEnv.executeSql(insertHiveSql);
在以上两种实现方式中,发现flink都会在yarn上启动两个应用,这两个应用虽然都能将数据正常写入hive和kafka,但是不太好。

后面通过不断的尝试api发现StreamTableEnvironment StreamStatementSet可以解决该问题
4.应用StreamTableEnvironment StreamStatementSet的核心代码
DataStream<String> dataStream = environment.addSource(new FlinkKafkaConsumer(topic, new SimpleStringSchema(), props));
TypeInformation[] tfs = getSqlColumsType(typeArray);
DataStream<Row> rowDataStream = dataStream.map(s -> createRow(SipFullauditMonitor.complex(s), size, typeArray, column))
.returns(Types.ROW_NAMED(column, tfs))
.filter(row -> CommonUtil.filter(row));
Table table = tableEnv.fromDataStream(rowDataStream);
setHiveParam(parameter, tableEnv);
tableEnv.createTemporaryView("tmp_" + topic, table);
//创建hive表
tableEnv.executeSql(BaseStreamLaucher.parseCreateTableSqlByColumn("ods_" + topic,column, typeArray,new String[]{"pdate","insterhour"},new String[]{"string","string"}));
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
//创建kafka表
tableEnv.executeSql("drop table dwd_sip_fullaudit_monitor");
String kafkaTableSql = createKafkaTableSqlByColumn("dwd_sip_fullaudit_monitor", parameter, column, typeArray);
tableEnv.executeSql(kafkaTableSql);
StatementSet stmtSet = tableEnv.createStatementSet();
//写hive表
String insertHiveSql = "insert into ods_" + topic + " PARTITION(pdate='" +
new SimpleDateFormat("yyyy-MM-dd").format(new Date()) +
"',insterhour='" + new SimpleDateFormat("yyyyMMddHH").format(new Date()) + "') select " + sinkHiveColumnStr + " from tmp_" + topic;
System.out.println("insertHiveSql:"+insertHiveSql);
//写kafka表
String insertKafkaSql = "insert into dwd_sip_fullaudit_monitor" + " select " + sinkHiveColumnStr + " from " + "tmp_" + topic;
stmtSet.addInsertSql(insertHiveSql);
stmtSet.addInsertSql(insertKafkaSql);
stmtSet.execute();
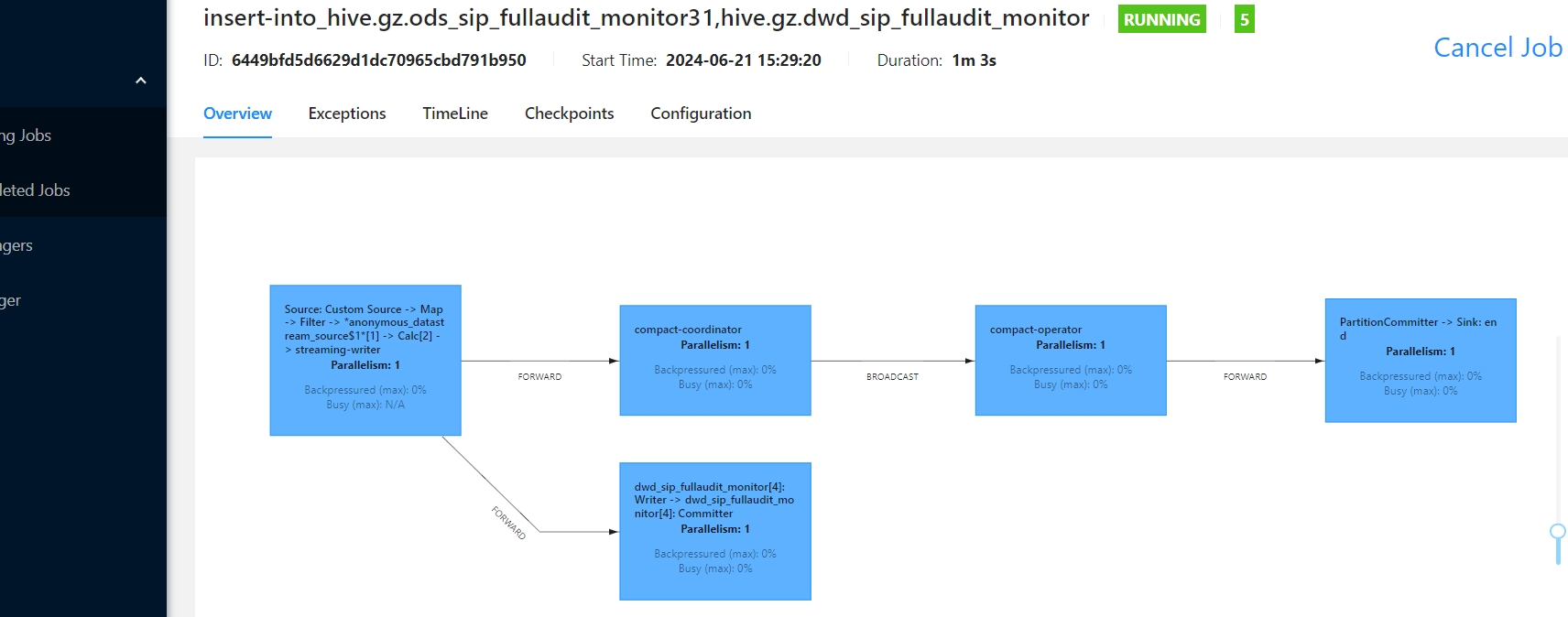
执行查看flink web界面

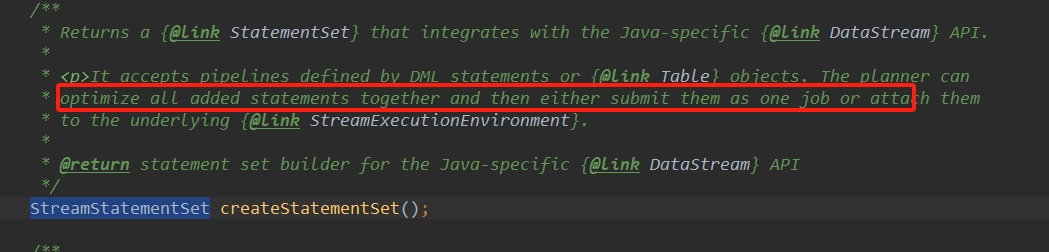
说明:
StreamStatementSet的这个的应用在初学或者一般场景应用下可能不太容易发现或应用,来看下flink源码的解释,红色部分大概意思是[可以一起优化所有添加的语句,然后将它们作为一个作业提交],重点是作为一个作业提交。但StreamStatementSet并没有解决前面的第一种场景。所以在实际的应用中不太建议流表和原生addsink混用,flink越往后的版本也是更加提倡应用流表方式去完成流批一体的体系