
Flink时间语义、窗口,水位线(watermark)介绍与应用
1.时间语义
Flink是一个实时计算引擎,谈到实时概念,就必然会设计到时间概念。Flink的时间语义是保证实时及实时数据处理的一致性,及时性。Flink时间语义分为下面三种
Event Time:事件创建时间
Ingestion Time:事件摄入时间(数据进入Flink的时间)
Processing Time:时间创建时间(执行操作算子的本地系统时间)
通过一个实际的场景就很好理解
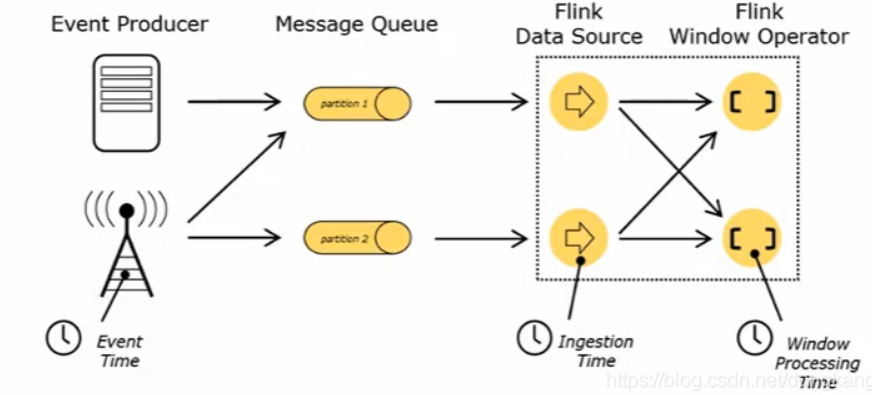
在实际业务场景中,为保证实时性和数据的正确性通常对Event Time<事件创建时间>处理比较常见。
2.窗口(Window)
Flink的核心在处理流式数据及无限流(个人觉得在有限流及批数据处理上Spark在应用和处理上是优于Flink),无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。这里读者就会有疑问了,这不就是微批吗?为什么不用sparkstreaming,sparkstreaming的核心就是微批处理。这里个人认为在底层逻辑上是有很大差别的。flink-window本身对摄取数据的方式不做改变,只是在算子计算中根据时间控制截取有限数据块,而且这个时间控制和有限数据块不宜过大,过大就失去核心意义了。而sparkstreaming是在摄入的时候就是一批一批的摄入,而每批的摄入不宜国小,如果过小会有急剧的性能压力,会使数据计算阻塞。
Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的buckets桶,我们可以在这些桶上做计算操作。
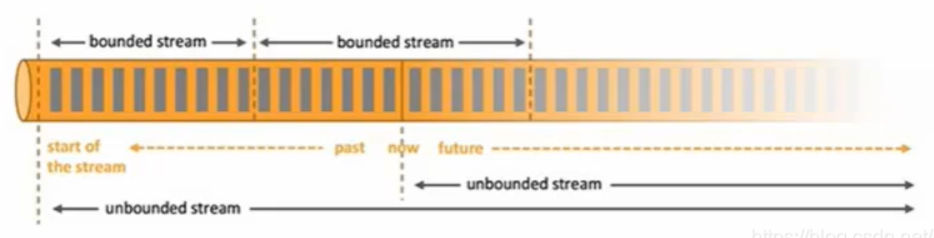
Window类型
时间窗口(Time Window),按照时间生成Window
滚动时间窗口
滑动时间窗口
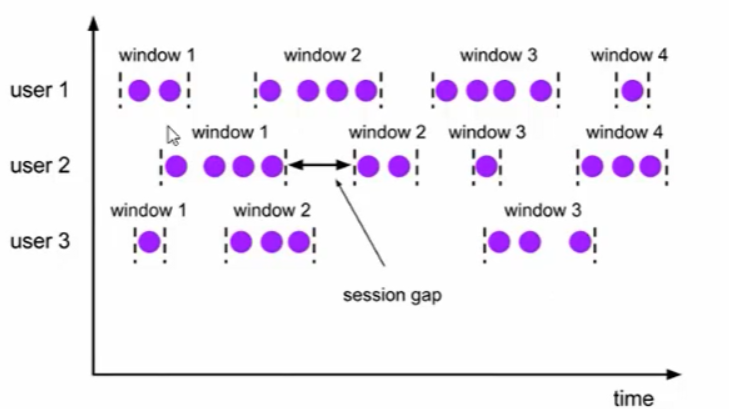
会话窗口
计数窗口(Count Window),按照指定的数据条数生成一个Window,与时间无关
滚动计数窗口
滑动计数窗口
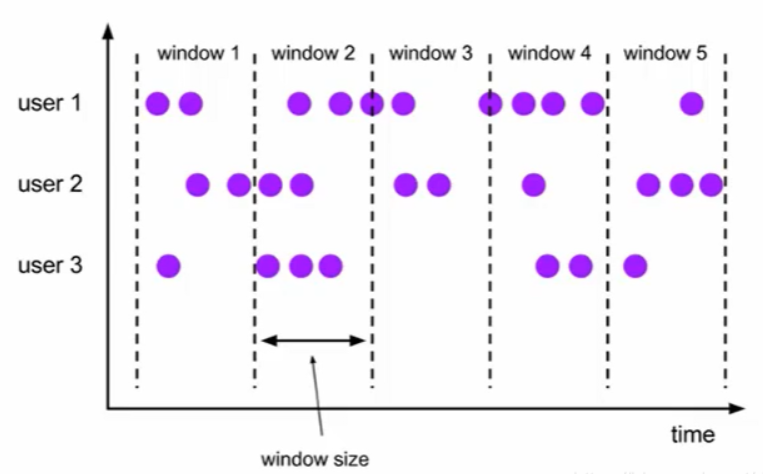
滚动窗口
依据固定的窗口长度对数据进行切分,时间对齐,窗口长度固定,没有重叠
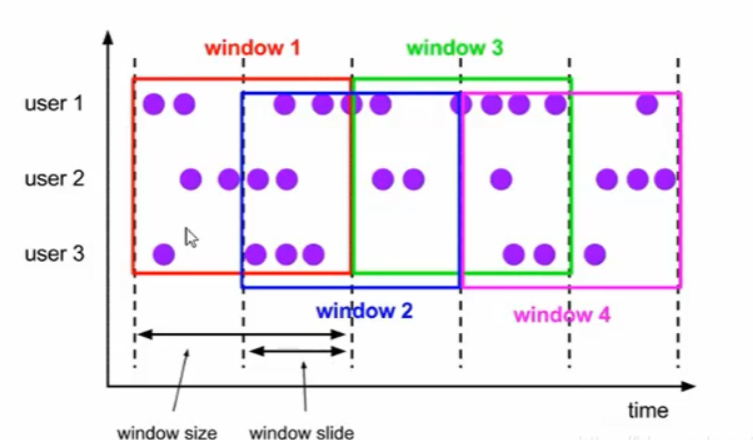
滑动窗口
可以按照固定的长度向后滑动固定的距离,滑动窗口由固定的窗口长度和滑动间隔组成,可以有重叠(是否重叠和滑动距离有关系)
滑动窗口是固定窗口的更广义的一种形式,滚动窗口可以看做是滑动窗口的一种特殊情况(即窗口大小和滑动间隔相等)
会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
创建不同类型的窗口
滚动时间窗口(tumbling time window)
.timeWindow(Time.seconds(15))
滑动时间窗口(sliding time window)
.timeWindow(Time.seconds(15),Time.seconds(5))
会话窗口(session window)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
滚动计数窗口(tumbling count window)
.countWindow(5)
滑动计数窗口(sliding count window)
.countWindow(10,2)
3.水位线(watermark)
watermark概念
流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
Flink对于迟到数据有三层保障,先来后到的保障顺序是:
WaterMark => 约等于放宽窗口标准
allowedLateness => 允许迟到(ProcessingTime超时,但是EventTime没超时)
sideOutputLateData => 超过迟到时间,另外捕获,之后可以自己批处理合并先前的数据
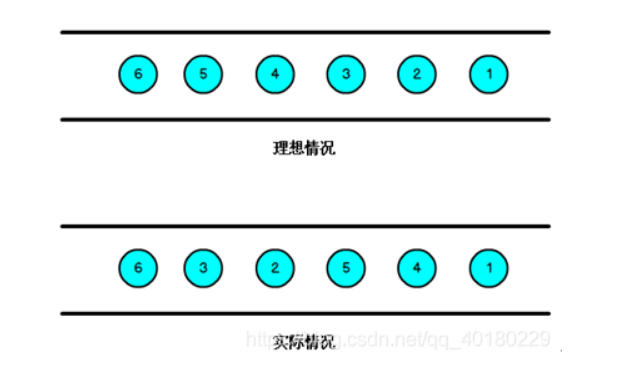
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
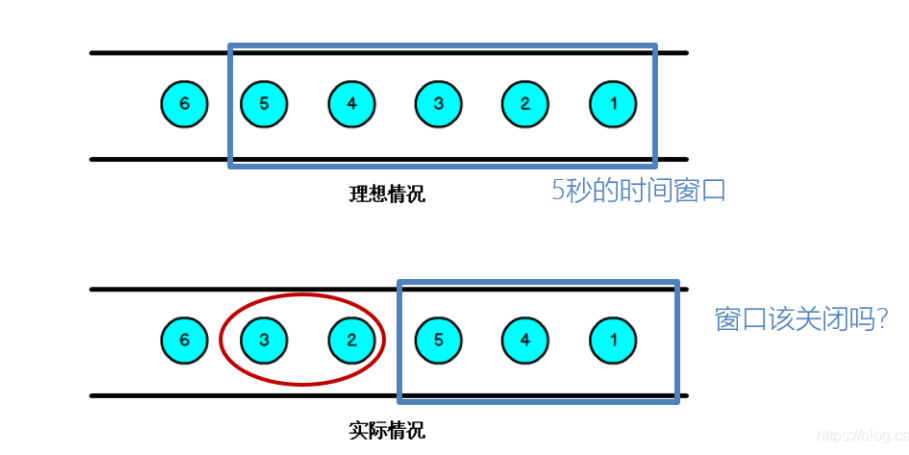
Watermark在flink中本质是解决数据的一致性(顺序性),那么如何避免乱序数据带来的计算不正确?
a.遇到一个时间戳达到了窗口关闭时间,不应该立即触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口
b.Watermark是一种衡量Event Time进展的机制,可以设定延迟触发
c.Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现
d.数据流中的Watermark用于表示”timestamp小于Watermark的数据,都已经到达了“,因此,window的执行也是由Watermark触发的。
e.Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
Watermark = maxEventTime-延迟时间t
watermark特点
a.watermark是一条特殊的数据记录
b.watermark必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
c.watermark与数据的时间戳相关
案例
测试代码
package com.meijs;
import java.io.Serializable;
public class Temperature implements Serializable {
private String id;
private double temperature;
private long eventTime;
//这里必须有空构造方法,不然flink会报错
public Temperature() {
}
public Temperature(String id, double temperature, long eventTime) {
this.id = id;
this.temperature = temperature;
this.eventTime = eventTime;
}
@Override
public String toString() {
return "Temperature{" +
"id='" + id + '\'' +
", temperature=" + temperature +
", eventTime=" + eventTime +
'}';
}
public String getId() {
return id;
}
public double getTemperature() {
return temperature;
}
public long getEventTime() {
return eventTime;
}
public void setId(String id) {
this.id = id;
}
public void setTemperature(double temperature) {
this.temperature = temperature;
}
public void setEventTime(long eventTime) {
this.eventTime = eventTime;
}
}
package com.meijs;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
public class WatermarkTest {
public static void main(String args[]) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.getConfig().setAutoWatermarkInterval(100);
DataStream<String> dataStream = env.socketTextStream("192.168.154.130", 7777);
SingleOutputStreamOperator<Temperature> minTemp = dataStream.map(line -> {
String[] lines = line.split(",");
return new Temperature(lines[0], Double.parseDouble(lines[1]), Long.parseLong(lines[2]));
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Temperature>(Time.seconds(2)) {
@Override
public long extractTimestamp(Temperature element) {
return element.getEventTime()*1000L;
}
}).keyBy("id")
.timeWindow(Time.seconds(5))
.minBy("temperature");
minTemp.print();
env.execute("WatermarkTest");
}
}
运行测试
a.启动一个sock服务
nc -lk 7777
b.启动Java测试类,启动后往sock中一行行输入数据,观察现象如下
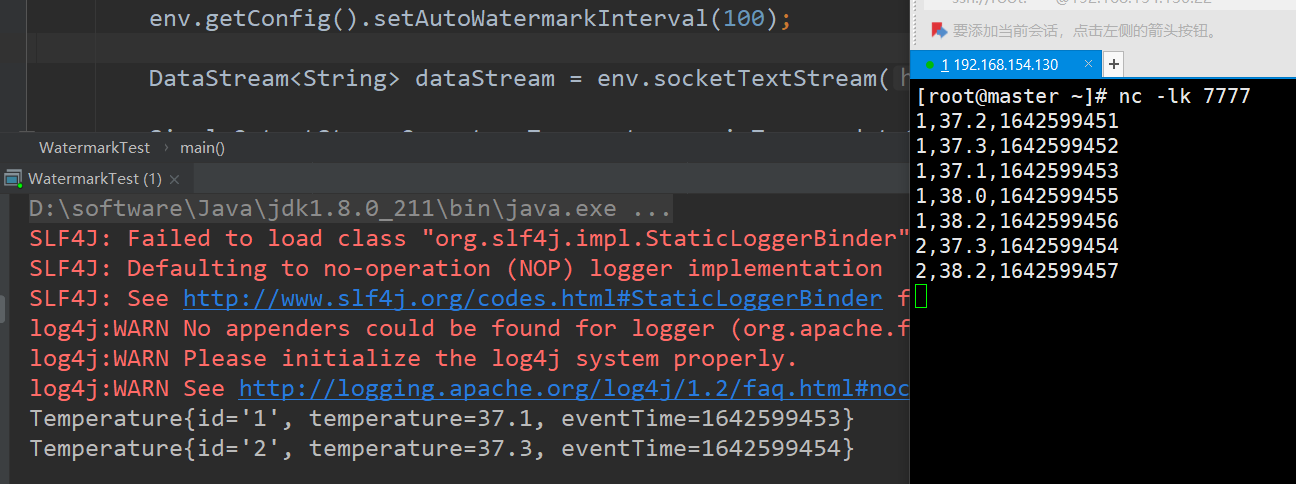
可以看到第一次sock输入的数据如下
1,37.2,1642599451
1,37.3,1642599452
1,37.1,1642599453
1,38.0,1642599455
1,38.2,1642599456
2,37.3,1642599454
2,38.2,1642599457
输出的结果如下
Temperature{id='1', temperature=37.1, eventTime=1642599453}
Temperature{id='2', temperature=37.3, eventTime=1642599454}
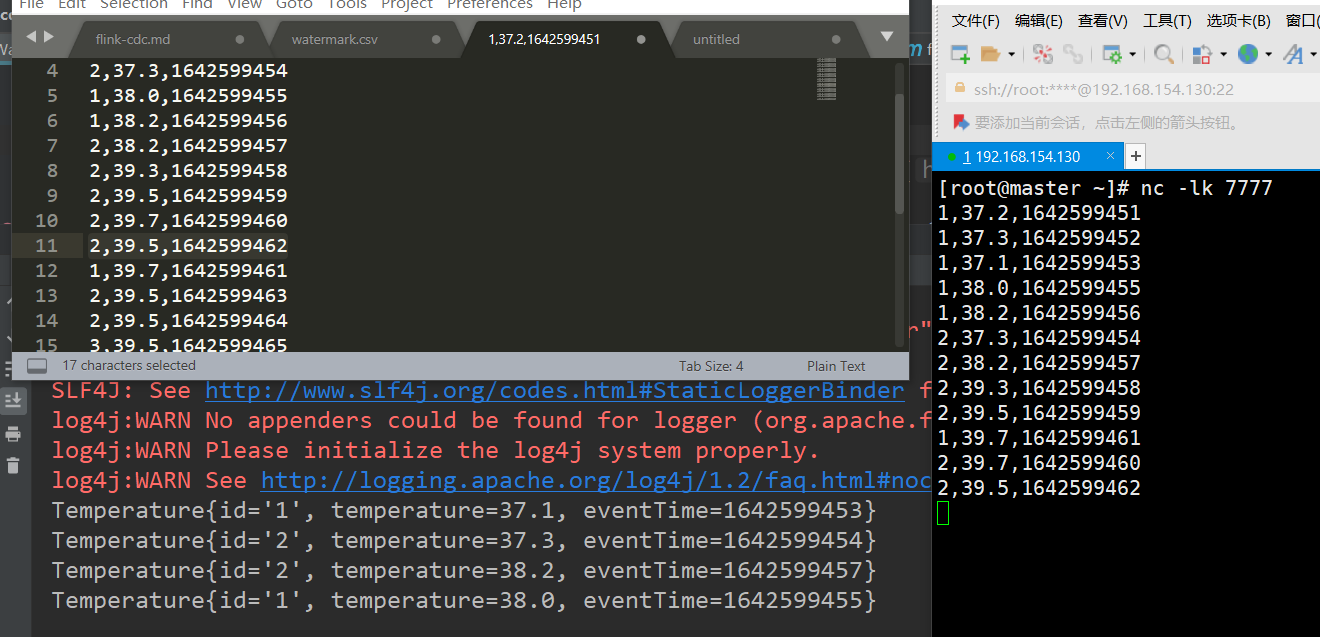
可以看到第二次sock输入的数据如下
1,37.2,1642599451
1,37.3,1642599452
1,37.1,1642599453
1,38.0,1642599455
1,38.2,1642599456
2,37.3,1642599454
2,38.2,1642599457
2,39.3,1642599458
2,39.5,1642599459
1,39.7,1642599461
2,39.7,1642599460
2,39.5,1642599462
输出的结果如下
Temperature{id='2', temperature=38.2, eventTime=1642599457}
Temperature{id='1', temperature=38.0, eventTime=1642599455}
通过对watermark,window,时间语义的综合分析,我们知道正常情况下
第一个事件时间窗口应该是如下:
[1642599450,1642599451,1642599452,1642599453,1642599454)
第二个事件时间窗口应该是如下:
[1642599455,1642599456,1642599457,1642599458,1642599459)
在第一个时间窗口中
原本应该按时到的1642599454的数据延迟了两秒才到,1642599455,1642599456早到了一秒,而我们设置的watermark为2,刚好晚到两秒的数据可以在第一个时间窗口内。
同理第二个也是如此
思考:
a.为什么时间事件语义是从1642599450开始的,而不是从我们输入的第一个数据1642599451开始的,这里我们跟一下源码
从timeWindow->KeyedStream(从timeWindow)->TumblingProcessingTimeWindows(assignWindows)->TimeWindow(getWindowStartWithOffset)
@Override
public Collection<TimeWindow> assignWindows(Object element, long timestamp, WindowAssignerContext context) {
final long now = context.getCurrentProcessingTime();
if (staggerOffset == null) {
staggerOffset = windowStagger.getStaggerOffset(context.getCurrentProcessingTime(), size);
}
long start = TimeWindow.getWindowStartWithOffset(now, (globalOffset + staggerOffset) % size, size);
return Collections.singletonList(new TimeWindow(start, start + size));
}
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}
这里我们的timestamp=1642599451,offset=0,windowsize=5,最后计算得出的结果即起始位置为1642599450,offset为偏移量,即对当前数据是否需要往前或往后偏移。
b.我们这里设置可以修正晚2s到来导致的数据的顺序性,如果大于2s如何处理?
在flink中对于该类数据可以设置侧输出流,如下代码
package com.meijs;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
public class WatermarkTest {
public static void main(String args[]) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.getConfig().setAutoWatermarkInterval(100);
DataStream<String> dataStream = env.socketTextStream("192.168.154.130", 7777);
OutputTag<Temperature> outputTag = new OutputTag<Temperature>("late") {
};
SingleOutputStreamOperator<Temperature> minTemp = dataStream.map(line -> {
String[] lines = line.split(",");
return new Temperature(lines[0], Double.parseDouble(lines[1]), Long.parseLong(lines[2]));
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Temperature>(Time.seconds(2)) {
@Override
public long extractTimestamp(Temperature element) {
return element.getEventTime()*1000L;
}
}).keyBy("id")
.timeWindow(Time.seconds(5))
.allowedLateness(Time.seconds(4))
.sideOutputLateData(outputTag)
.minBy("temperature");
minTemp.print("watermark");
minTemp.getSideOutput(outputTag).print("late");
env.execute("WatermarkTest");
}
}
输入数据和输出结果如下:
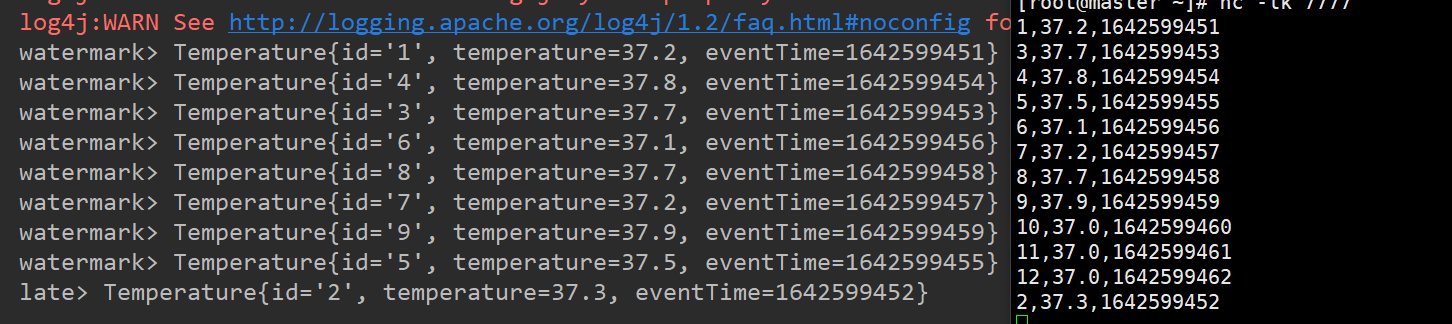
注意:
a.watermark事件时间不建议设置过大,也就是说不建议处理过大的延迟,最好小于分钟级别。也不能过小。对于过大的延迟可以采取侧输出流合并。
b.不建议时间窗口设置过大,过大会影响实时流的时效。
关于flink watermark推荐一篇文章(https://blog.csdn.net/lmalds/article/details/52704170),


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~