
数据仓库中数据模型之拉链表
1.数据仓库及数仓中的数据模型及操作描述
在大数据设计与开发过程中,数据仓库是必不可少的一部分。但很多开发者将数仓理解为很多业务库和业务表的汇总集合,这是不全面的。数仓存在很多设计,架构,业务建模等多个维度的问题。关于数仓的大体介绍可以参照之前的文章(https://www.cnblogs.com/jiashengmei/p/12092691.html), 本篇只分享数据仓库中的数据模型及操作。落地到实际中就是在某些业务场景下,数仓的表怎样去设计。
有过大数据开发经验的开发者都明白,在大数据环节,数据的操作不能像RDMS数据库那样。比如最常见的,在RDMS库中,假设是mysql数据库,对数据的单条或根据一定条件修改更新,单条或根据一定条件删除等等一些操作是再正常不过的。可能会因为数据库表记录多存在一定的性能问题。而在大数据环节,很多开发者都知道,大数据的很多数据服务组件其实不支持单条删除或者更新操作的,比如hive,clickhouse等等数据组件。虽然某些大数据组件在高版本也做到对数据进行特殊的删除修改,但是也是不建议使用的。为什么会有这样的问题或者设计?,很多大数据开发人员都清楚,在大数据开发中,往往是面对TB、PB甚至更多的数据,也会面对光一个表就可能是10亿、100亿甚至更多的条数的数据。在这种情况下,如果不按分而治之的思想去对数据进行操作,而是采用传统的RDMS数据组件的方式去操作,有一半的操作是没法进行的,同时会对数据质量,数据的一致性、完整性、时效性造成破坏,同时会对数据服务带来问题。而分而治之的设计其实就是对数据进行分区,最常见的有按天分区(T-1)模式,按小时分区(H-1)模式。在这些前提下,数仓的数据模型,表结构,及表对数据的存储和操作都需要区别于传统的RDMS单独设计。当然,如何设计一定是站在业务的基础上,只是某些设计方案和方法具备共用性。下面就举例介绍在以hive为数仓基础上的几个常用的数据模型表设计。
2.数仓之拉链表
以电商中的订单为例,经常会遇到这样的需求
a.表中的部分字段会被update,最常见的如订单的状态
b.需要查看某一个时间点或者时间段的历史快照信息,比如查看某一个订单在历史某一个时间点的状态,比如查看某一个用户在过去某一段时间内,更新过几次。
c.变化的比例和频率不是很大,比如,总共有1000万的会员,每天新增和发生变化的有10万左右。
举个简单例子,比如有一张订单表,6月20号有3条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 创建订单 |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 支付完成 |
到6月21日,表中有5条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 支付完成(从创建到支付) |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 支付完成 |
| 2020-06-21 | 004 | 创建订单 |
| 2020-06-21 | 005 | 创建订单 |
可以看出从2020-06-20到2020-06-21,订单编号为001的订单状态有修改操作,订单编号为004、005是新增操作
到6月22日,表中有6条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 支付完成(从创建到支付) |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 已发货(从支付到发货) |
| 2020-06-21 | 004 | 创建订单 |
| 2020-06-21 | 005 | 支付完成(从创建到支付) |
| 2020-06-22 | 006 | 创建订单 |
如果按照上述方式数据存储下来,会遇到以下几个问题
a.只保留一份全量,如当前时间为6月22号,数据如6月22日的记录一样,如果需要查看6月21日订单003的状态,则无法满足。
b.每天都保留一份全量,即将每天的状态作全量的保留,则数据仓库中的该表共有14条记录,有记录是重复的,没有任务变化,如订单002,004,数据量大了,会造成很大的存储浪费
基于以上问题,采用拉链表来设计订单表
从6月20号到6月22号拉链表的记录如下::
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
|---|---|---|---|---|
| 2012-06-20 | 001 | 创建订单 | 2012-06-20 | 2012-06-20 |
| 2012-06-20 | 001 | 支付完成 | 2012-06-21 | 9999-12-31 |
| 2012-06-20 | 002 | 创建订单 | 2012-06-20 | 9999-12-31 |
| 2012-06-20 | 003 | 支付完成 | 2012-06-20 | 2012-06-21 |
| 2012-06-20 | 003 | 已发货 | 2012-06-22 | 9999-12-31 |
| 2012-06-21 | 004 | 创建订单 | 2012-06-21 | 9999-12-31 |
| 2012-06-21 | 005 | 创建订单 | 2012-06-21 | 2012-06-21 |
| 2012-06-21 | 005 | 支付完成 | 2012-06-22 | 9999-12-31 |
| 2012-06-22 | 006 | 创建订单 | 2012-06-22 | 9999-12-31 |
拉链表字段描述
a. dw_begin_date表示该条记录的生命周期开始时间,dw_end_date表示该条记录的生命周期结束时间。
b. dw_end_date='9999-12-31'表示该条记录目前处于有效状态。
下面来几个查询:
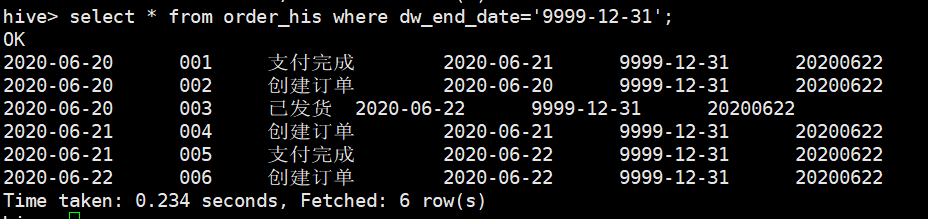
a.查询当前订单的最新有效状态
select * from order_his where dw_end_date='9999-12-31';
查询结果
b.如果查询2020-06-21的历史快照
select * from order_his where dw_begin_date<='2020-06-21' and dw_end_date>='2020-06-21';
查询结果

从以上结果可以看出,这样的拉链表,既能满足对历史数据的需求,又能很大程度的节省存储资源。
3.拉链表的更新操作
现在有如下需求:
a.数据仓库中订单历史表的刷新频率为一天,当天更新前一天的增量数据。
b.如果一个订单在一天内有多次状态变化,则只会记录最后一个状态的历史。
c.订单状态包括三个:创建、支付、完成。
d.创建时间和修改时间只取到天,如果源订单表中没有状态修改时间,那么抽取增量就比较麻烦,需要有个机制来确保能抽取到每天的增量数据。
基于以上需求,需要创建三张表
源系统中订单表
CREATE TABLE orders(
order_id string,
create_time string,
modified_time string,
status string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
数仓的ODS层,有一张订单的增量数据表,按天分区,存放每天的增量数据
CREATE TABLE t_ods_orders_inc(
order_id string,
create_time string,
modified_time string,
status string)
PARTITIONED BY (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
数仓的DW层,有一张订单的历史数据拉链表,存放订单的历史状态数据
CREATE TABLE t_dw_orders_his (
order_id string,
create_time string,
modified_time string,
status string,
dw_start_date string,
dw_end_date string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
orders表在2020-08-21的全量数据
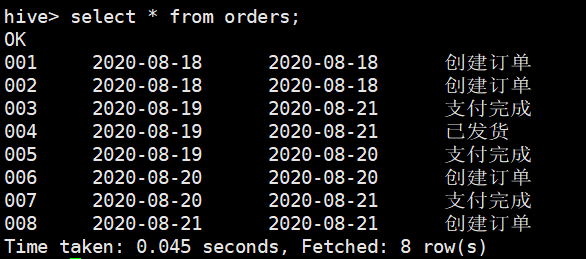
在2020-08-22这天抽取orders全量数据到t_ods_orders_inc
INSERT overwrite TABLE t_ods_orders_inc PARTITION (day = '2020-08-21')
SELECT order_id,create_time,modified_time,status
FROM orders WHERE create_time<='2020-08-21';
在2020-08-22这天抽取t_ods_orders_inc全量数据到t_dw_orders_his
INSERT overwrite TABLE t_dw_orders_his
SELECT order_id,create_time,modified_time,status,
create_time AS dw_start_date,
'9999-12-31' AS dw_end_date
FROM t_ods_orders_inc WHERE day = '2020-08-21';
t_dw_orders_his数据明细如下
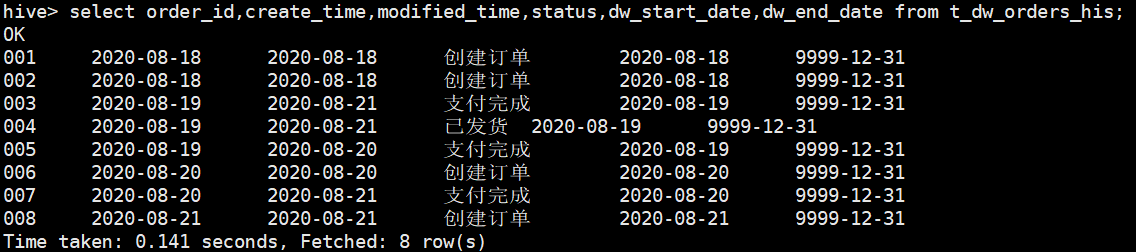
因为这是第一次通过拉链表同步数据,可能看不出什么特殊的情况,现在来演示增量更新
orders表在2020-08-22的全量数据
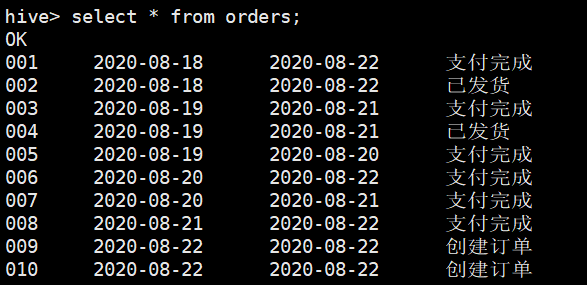
在2020-08-23号只做增量同步抽取2020-08-22的数据到t_ods_orders_inc
INSERT overwrite TABLE t_ods_orders_inc PARTITION (day = '2020-08-22')
SELECT order_id,create_time,modified_time,status
FROM orders
WHERE create_time = '2020-08-22' OR modified_time = '2020-08-22';
查询结果如下
通过DW历史数据(数据日期为2015-08-21),和ODS增量数据(2020-08-22),刷新历史表
先把数据放到一张临时表中:
DROP TABLE IF EXISTS t_dw_orders_his_tmp;
CREATE TABLE t_dw_orders_his_tmp AS
SELECT order_id,
create_time,
modified_time,
status,
dw_start_date,
dw_end_date
FROM (
SELECT a.order_id,
a.create_time,
a.modified_time,
a.status,
a.dw_start_date,
CASE WHEN b.order_id IS NOT NULL AND a.dw_end_date > '2020-08-22' THEN '2020-08-21' ELSE a.dw_end_date END AS dw_end_date
FROM t_dw_orders_his a
left outer join (SELECT * FROM t_ods_orders_inc WHERE day = '2020-08-22') b
ON (a.order_id = b.order_id)
UNION ALL
SELECT order_id,
create_time,
modified_time,
status,
modified_time AS dw_start_date,
'9999-12-31' AS dw_end_date
FROM t_ods_orders_inc
WHERE day = '2020-08-22'
) x
ORDER BY order_id,dw_start_date;
最后把临时表中数据插入历史表
INSERT overwrite TABLE t_dw_orders_his SELECT * FROM t_dw_orders_his_tmp;
最后t_dw_orders_his全表的数据如下:

现在来几个查询,看拉链表是否能够满足基本的业务需求
查询订单编号为001的整个状态流程

查询订单编号为002的目前状态

查询2020-08-21的历史快照

说明
a.在实际实践中,只要数据到了DW层的拉链表,其他临时相关的表就可以删除了,以便减少数据的存储
b.实际开发设计时,上述过程是完全自动化的
4.数仓模型中其他几种类型的表
全量表:每天的所有的最新状态的数据
增量表:每天的新增数据
流水表:对于表中的每一个修改都会记录,可以用于反映实际记录的变更

