
大数据时序分析组件druid获取kafka和hdfs数据示例
1.说明
a. druid支持获取数据种类较多,包括本地离线数据,hdfs数据和kafka实时流数据。在实际基于hadoop生态系统的大数据开发应用中,获取hdfs数据和kafka流式数据较为常见。本篇文档着重说明获取kafka和hdfs数据的实例。
b. 想要获取什么样类型的数据,就需要在配置文件配置(这里默认druid集群或单击已经搭建完成,如果没有搭建,参照上篇博客)。vim ${DRUID_HOME}/conf/druid/cluster/_common/common.runtime.properties
druid.extensions.loadList=["druid-hdfs-storage","mysql-metadata-storage","druid-kafka-indexing-service"]
c. 获取数据的方法有两种,第一种就是通过页面傻瓜式的下一步,如图
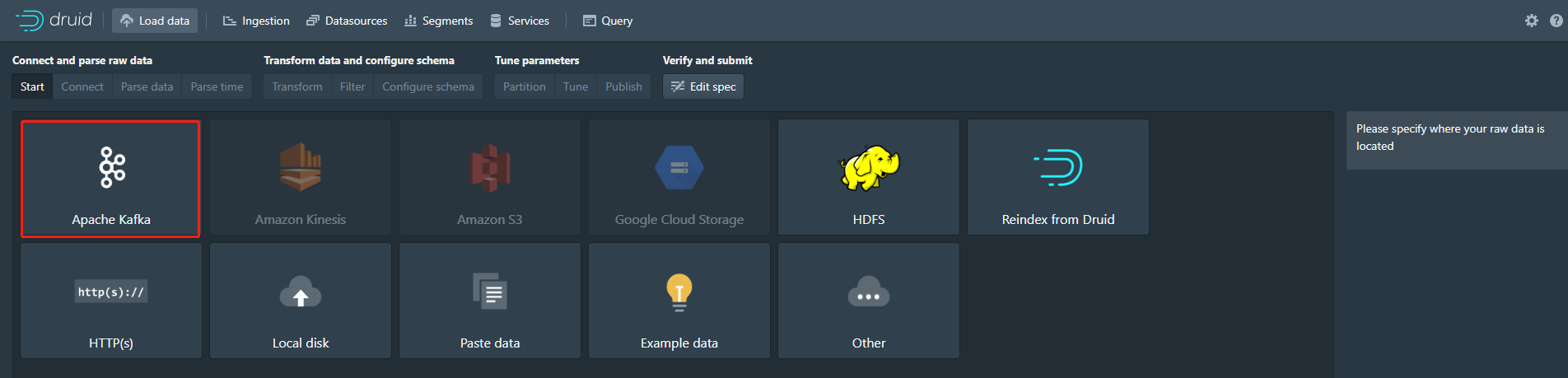
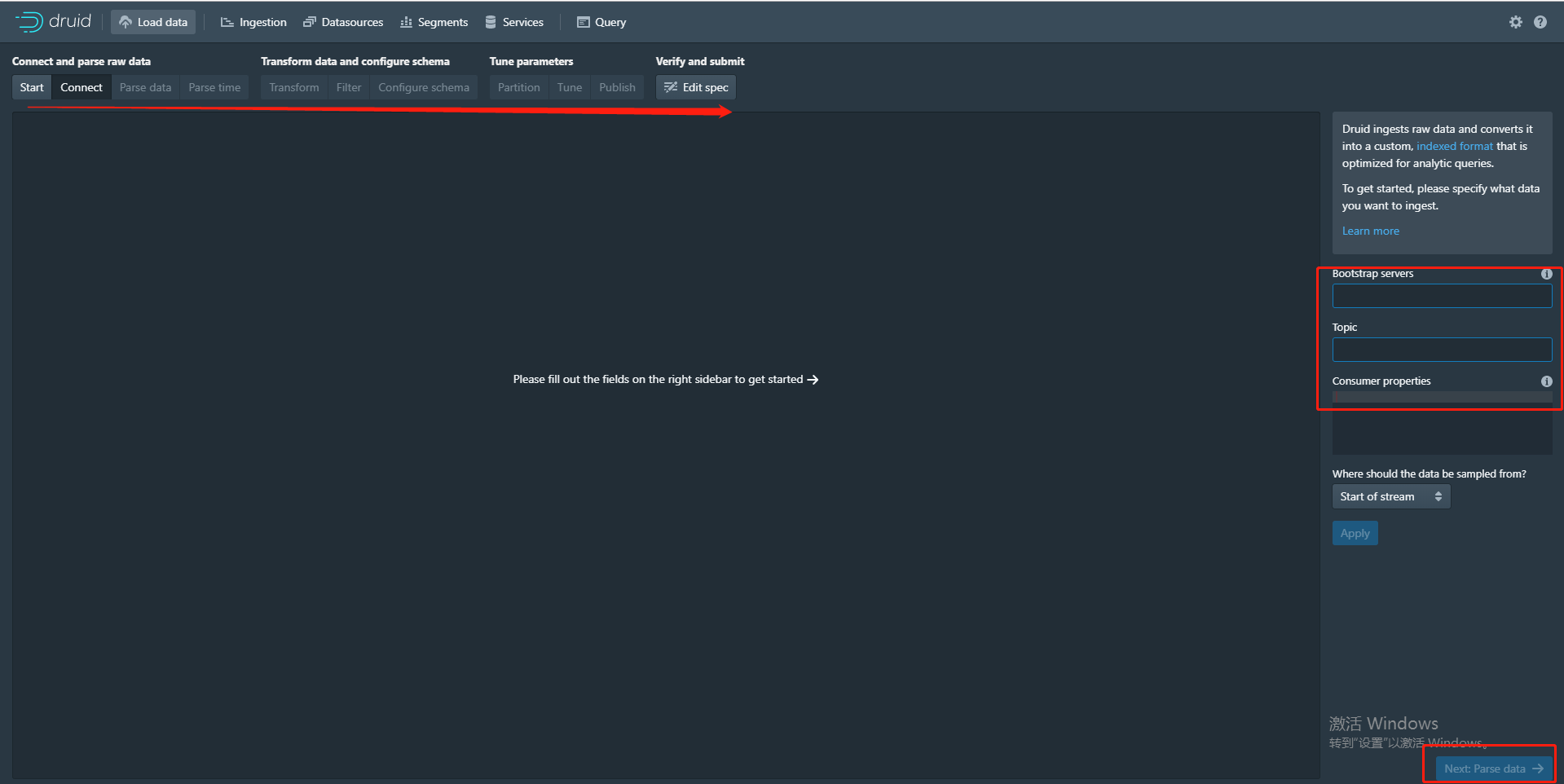
只需要相关信息填写正确,按照箭头方向每一步正确操作即可
第二种方式是自己写json配置文件,通过执行命令。其实这两种方式本事是一样的。只不过第一种方式是在页面操作后生成了json文件。但实际开发中,还是建议选择第二种方式。下面基于获取kafka和hdfs上的数据来介绍第二种方式。
2.实时获取kafka数据流
a. druid自带了一个获取kafka数据样例,${DRUID_HOME}/quickstart/tutorial/wikipedia-kafka-supervisor.json,直接在此基础上改成自己的正确的配置
{
"type": "kafka",
"spec" : {
"dataSchema": {
"dataSource": "my-wikipedia",
"timestampSpec": {
"column": "time",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{
"name": "added",
"type": "long"
},
{
"name": "deleted",
"type": "long"
},
{
"name": "delta",
"type": "long"
}
]
},
"metricsSpec": [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "NONE",
"rollup": false
}
},
"tuningConfig": {
"type": "kafka",
"reportParseExceptions": false
},
"ioConfig": {
"topic": "my-wikipedia",
"inputFormat": {
"type": "json"
},
"replicas": 1,
"taskDuration": "PT10M",
"completionTimeout": "PT20M",
"consumerProperties": {
"bootstrap.servers": "master:9092"
}
}
}
}
b. 执行命令
curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/wikipedia-kafka-supervisor.json http://master:8081/druid/indexer/v1/supervisor
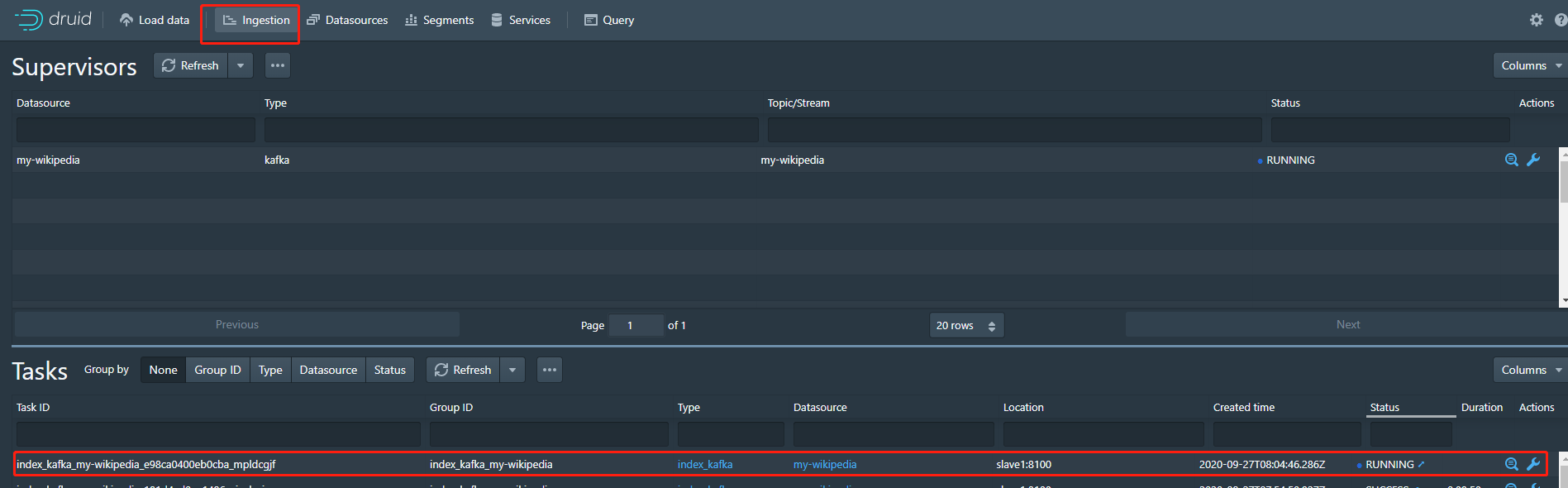
执行上述命令出现{"id":"my-wikipedia"}的结果证明是成功的
在druid页面也正确看到任务的状况,如下图,表示完全成功
c.往kafka写和配置匹配的样例数据,就可以在query页面查看到写入的数据了
3. 获取hdfs数据
a. 获取hdfs数据和kafka数据只是在配置文件上有所区别,druid也自带了一个获取hdfs数据样例,${DRUID_HOME}/quickstart/tutorial/wikipedia-index-hadoop.json,这里我将其给名为my-wikipedia-index-hadoop.json,直接在此基础上改成自己的正确的配置
{
"type" : "index_hadoop",
"spec" : {
"dataSchema" : {
"dataSource" : "my-hdfs-wikipedia",
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "json",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"timestampSpec" : {
"format" : "auto",
"column" : "time"
}
}
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2015-09-12/2015-09-13"],
"rollup" : false
}
},
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "/test-data/druid/wikiticker-2015-09-12-sampled.json.gz"
}
},
"tuningConfig" : {
"type" : "hadoop",
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000
},
"forceExtendableShardSpecs" : true,
"jobProperties" : {
"fs.default.name" : "hdfs://master:8020",
"fs.defaultFS" : "hdfs://master:8020/",
"dfs.datanode.address" : "master",
"dfs.client.use.datanode.hostname" : "true",
"dfs.datanode.use.datanode.hostname" : "true",
"yarn.resourcemanager.hostname" : "master",
"yarn.nodemanager.vmem-check-enabled" : "false",
"mapreduce.map.java.opts" : "-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.job.user.classpath.first" : "true",
"mapreduce.reduce.java.opts" : "-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.map.memory.mb" : 1024,
"mapreduce.reduce.memory.mb" : 1024
}
}
},
"hadoopDependencyCoordinates": ["org.apache.hadoop:hadoop-client:2.8.5"]
}
这里需要注意"hadoopDependencyCoordinates": ["org.apache.hadoop:hadoop-client:2.8.5"]这项配置。这里的配置需要跟随druid自带的hadoop-dependencies版本,比如这里是${DRUID_HOME}/hadoop-dependencies/hadoop-client/2.8.5/。但是这里还需要注意hadoop版本和该版本是否一致,如果不至于是会报错的。这个时候最好的方式是将druid版本作调整。
b. 执行命令
curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/my-wikipedia-index-hadoop.json http://master:8081/druid/indexer/v1/task

