
大数据时序分析组件Druid集群安装配置部署
1.节点服务规划
master:coordinator,overlord
slave1:historical,middle_manager
slave2:router,broker
2.下载安装包解压
从druid官网(https://druid.apache.org/downloads.html) 下载,我这里下载的是druid-0.17.0
tar -zxvf apache-druid-0.17.0-bin.tar.gz
解压后的目录结构如下:
3.在mysql中创建druid元数据库
CREATE DATABASE druid DEFAULT CHARACTER SET utf8;
4.开始配置
现在master节点上配置,配置好后scp到slave1,slave2节点上
配置信息如下:
在解压后druid文件的当前目录vim conf/druid/cluster/_common/common.runtime.properties
# If you specify `druid.extensions.loadList=[]`, Druid won't load any extension from file system.
# If you don't specify `druid.extensions.loadList`, Druid will load all the extensions under root extension directory.
# More info: https://druid.apache.org/docs/latest/operations/including-extensions.html
druid.extensions.loadList=["druid-hdfs-storage","mysql-metadata-storage"]
# If you have a different version of Hadoop, place your Hadoop client jar files in your hadoop-dependencies directory
# and uncomment the line below to point to your directory.
#druid.extensions.hadoopDependenciesDir=/my/dir/hadoop-dependencies
#
# Hostname
#
druid.host=master
#
# Zookeeper
#
druid.zk.service.host=master:2181,slave1:2181,slave2:2181
druid.zk.paths.base=/druid
##将Metadata storage配置为mysql,默认是derby注释掉
# For MySQL (make sure to include the MySQL JDBC driver on the classpath):
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://master:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456
#将数据文件存储到hdfs,默认的注释掉
# For HDFS:
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#将indexer.log文件存储到hdfs,默认的注释掉
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
目钱主要需要根据默认配置项更改的如上,其他的采用默认配置项
5.配置个各个服务的内存消耗(尤为重要)
该项配置根据自己的服务器的资源情况而定
配置coordinator-overlord的jvm内存值
vim conf/druid/cluster/master/coordinator-overlord/jvm.config
-server
-Xms512m
-Xmx512m
-XX:+ExitOnOutOfMemoryError
-XX:+UseG1GC
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=var/druid/derby.log
主要配置-Xms512m和-Xmx512m
配置数据节点的historical的jvm内存值,vim conf/druid/cluster/data/historical/jvm.config
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
主要配置-Xms512m,-Xmx512m和-XX:MaxDirectMemorySize=128m
配置数据节点的historical的线程并发数,vim conf/druid/cluster/data/historical/runtime.properties
druid.processing.buffer.sizeBytes=5000000
druid.processing.numMergeBuffers=2
druid.processing.numThreads=10
druid.server.maxSize=300000000
主要是以上四项根据自己服务器资源调整,其他默认配置
配置数据节点的middleManager的jvm内存值,vim conf/druid/cluster/data/middleManager/jvm.config
-server
-Xms128m
-Xmx128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
主要配置-Xms128m,-Xmx128m和-XX:MaxDirectMemorySize=128m
配置数据节点的middleManager的线程并发数,vim conf/druid/cluster/data/middleManager/runtime.properties
druid.indexer.fork.property.druid.processing.numMergeBuffers=2
druid.indexer.fork.property.druid.processing.buffer.sizeBytes=1000000
druid.indexer.fork.property.druid.processing.numThreads=1
主要是以上三项根据自己服务器资源调整,其他默认配置
配置查询节点的broker的jvm内存值,vim conf/druid/cluster/query/broker/jvm.config
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
主要配置-Xms512m-Xmx512m和-XX:MaxDirectMemorySize=128m
配置查询节点的broker的线程并发数,vim conf/druid/cluster/qury/broker/runtime.properties
druid.server.http.numThreads=30
# HTTP client settings
druid.broker.http.numConnections=50
druid.broker.http.maxQueuedBytes=10000000
# Processing threads and buffers
druid.processing.buffer.sizeBytes=5000000
druid.processing.numMergeBuffers=3
druid.processing.numThreads=1
主要是以上几项根据自己服务器资源调整,其他默认配置
配置查询节点router的jvm内存值,vim conf/druid/cluster/query/router/jvm.config
-server
-Xms512m
-Xmx512m
-XX:+UseG1GC
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
主要配置-Xms512m-Xmx512m和-XX:MaxDirectMemorySize=128m
配置查询节点的router的线程并发数,vim conf/druid/cluster/qury/router/runtime.properties
druid.router.http.numConnections=20
druid.router.http.readTimeout=PT5M
druid.router.http.numMaxThreads=50
druid.server.http.numThreads=50
主要是以上几项根据自己服务器资源调整,其他默认配置
注意:
Historical和MiddleManager节点配置MaxDirectMemorySize必须满足下面这个公式:
MaxDirectMemorySize >= druid.processing.buffer.sizeBytes[536,870,912] * (druid.processing.numMergeBuffers[2] + druid.processing.numThreads[2] + 1)
一般启动不成功都是因为以上配置不合理,如果遇到一些启动不成功问题,可以参照这边博客解决(https://www.cnblogs.com/yinghun/p/9224701.html)
6.配置各个节点
在master节点上按4、5中配置完全后将整个druid目录scp到slave1、slave2节点
scp -r druid-0.17.0 root@slave1:/home/bigdata/software/
scp -r druid-0.17.0 root@slave2:/home/bigdata/software/
再将slave1,和slave2中的配置文件conf/druid/cluster/_common/common.runtime.properties的host改为对应节点的host
7.启动druid集群
按照1中的规划在各个节点分别启动
在master节点的druid目录执行:
./bin/start-cluster-master-no-zk-server
在slave1节点的druid目录执行:
./bin/start-cluster-data-server
在slave2节点的druid目录执行:
./bin/start-cluster-query-server
以上第一次执行直接按上面方式打印出来,看会不会报错,如果报错大部分是因为内存和并发数超过了服务器节点能提供的,所以出现线程数据不足,java内存溢出问题。如果没有报错,证明启动成功。
注意:druid的每个模块是独立存在的相互不影响的,所以如果某些模块启动成功,某些模块启动失败,可以单独排除没有启动成功模块的异常。当然更多的jvm资源和线程数配置的异常
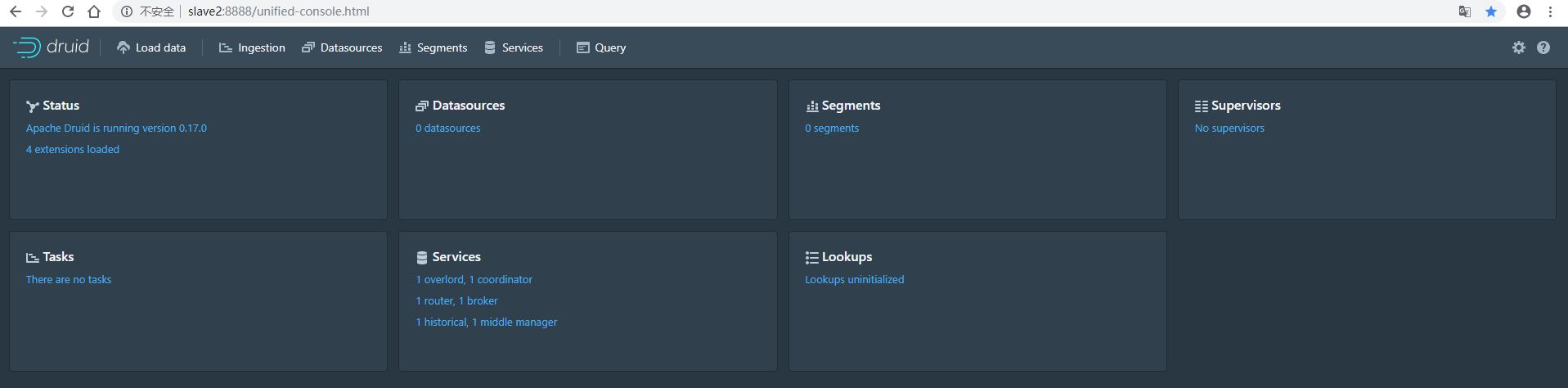
druid的管理页面(http://slave2:8888),页面信息如下:
也注意每个模块都没有异常信息才算集群完全启动正确。后续会逐渐介绍Druid在大数据中的实际应用

