
大数据之数据仓库
1. 摘要
对于大数据而言,数据仓库承载着整个企业的全业务的数据。早期数仓在关系型数据如Oracle,MySql上。到大数据时代,基于hadoop生态的大数据架构,数仓基本上都是基于hive的数仓。对于很多大数据开发者而言,特别是早期,很多开发者认为hive数仓就是和业务相关,隐射Hdfs数据文件的一张张表。针对于hive数仓而言,最终看到的确实是一张纸表,但这些表是如何根据业务抽象出来的、表之间的关系、表如何更好的服务应用这些问题是数仓建模、数仓技术架构的核心。一个好的数仓技术架构和数仓建模。可以减少开发的难度,提高数据服务性能,同时能够在很大层面上对业务形成数据中心,降低存储,计算资源的消耗等等
2.数仓架构的演变
传统经典数仓架构->离线数仓架构->实时数仓架构->Lambda数仓架构->Kappa数仓架构->混合数仓架构

a.传统数仓架构在大数据领域应用不多了,这类架构在早期数据量不大,对性能的要求不高,业务较单一的场景中应用比较多,这类数仓主要以oracle,mysql这种关系型数据库的范式设计原则设计
b.离线数仓架构是在大数据领域应运而生的。主要是基于hadoop生态组件的大数据技术架构方案中以hive为主的,在设计层面遵循和借鉴传统数仓的设计思路和规范,在计算上则以分布式计算为主提高数据的操作性能
c.实时数仓是近几年提出的一种数仓架构,与离线数仓方案有相似之处,不同之处在于数据是实时的。这也是整个大数据从离线分布式计算迈向实时流计算过程中产生的。但个人认为实时数仓方案还有很多不成熟的地方,在业务场景中还是有很多局限性
d.对于Lambda数仓架构,Kappa数仓架构,混合数仓架构这些架构更多的是应对与特定场景,这类数仓架构方案不具备一定的通用性
3.数仓的逻辑分层

4.数仓的设计步骤与原则
4.1.数据调研
a.业务场景调研
需要明确业务场景的分类,比如行业类大概有电商场景,电信运营商场景,社交场景等等,这些场景不同带来的是需求不同,需求不同则带来的是模型之间的差异化
b.需求调研
不同的场景不同的需求,比如很多企业的数仓更多是服务于数据可视化BI,有的服务于应用系统,有的服务于2C端。这些业务需求在统计、用户画像,推荐上等等的功能都有差异化
c.模型调研
根据实际业务场景,将业务侧对齐,遵循关系型数据库建模方式,从概念模型(cdm)->逻辑模型(ldm)->物理模型(pdm)建模套路,是一个从抽象到具体的一个不断细化完善的分析,设计和开发的过程。
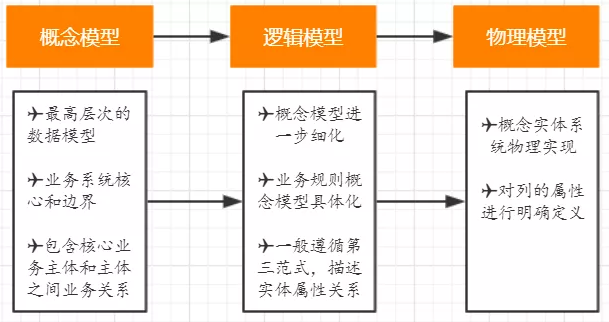
4.2.数仓建模
经典抽象建模四步骤:选择业务过程->声明粒度->确定维度->确定事实 进行维度建模。
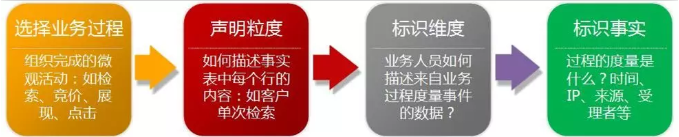
常用的业务实体建模方法:维度模型、范式模型、Data-Valut模型、Anchor模型
其中维度模型是大数据数仓的最常用的模型,范式模型是传统的数仓常用的,其他两种模型较为少见,针对特点的场景。而维度模型根据数据组织类型又划分为星型模型、雪花模型、星座模型
a.星型模型
星型模型主要是维表和事实表,以事实表为中心,所有维度直接关联在事实表上,呈星型分布。可以初略理解为如果用星型模型设计数仓的表时。一个业务实体中多个表的关系是一对多,one(事实表)2many(维度表)。星型模型是基于hadoop生态的大数据用的最多的一种模型
什么是维度表?
维度表可以看成是用户用来分析一个事实的窗口,它里面的数据应该是对事实的各个方面描述,比如时间维度表,它里面的数据就是一些日,周,月,季,年,日期等数据,维度表只能是事实表的一个分析角度。
什么是事实表?
事实表其实质就是通过各种维度和一些指标值得组合来确定一个事实的,比如通过时间维度,地域组织维度,指标值可以去确定在某时某地的一些指标值怎么样的事实。事实表的每一条数据都是几条维度表的数据和指标值交汇而得到的
示例:
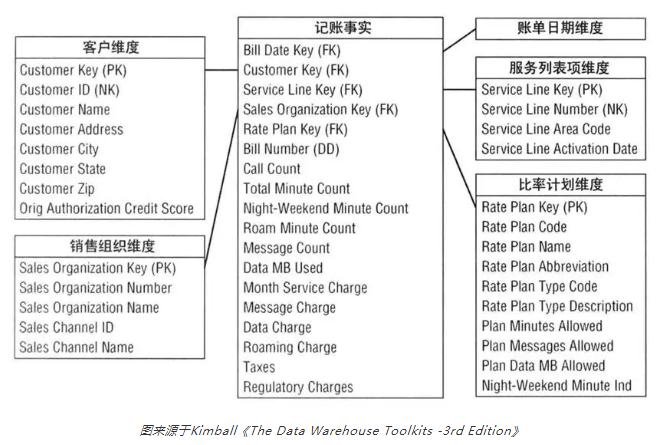
b.雪花模型
雪花模型,在星型模型的基础上,维度表上又关联了其他维度表。这种模型使用过程中会造成大量的join,维护成本高,性能方面也较差,所以一般不建议使用。尤其是基于hadoop体系构建数仓,减少join就是减少shuffle,性能差距会很大。
c.星座模型
星座模型,是对星型模型的扩展延伸,多张事实表共享维度表。数仓模型建设后期,当一个星型模型为一个实体,又有多个是实体,实体间又共用维表(这个是很常见的),就自然成了星座模型了。大部分维度建模都是星座模型。
4.2.数仓规范
构建企业级数据仓库,必不可少的就是制定数仓规范。包括 命名规范,流程规范,设计规范,开发规范 等。
开发规范 示例:

4.3.基于模型的数据开发语言
开发语言,传统数仓一般SQL/Shell为主,互联网数仓又对Python、Java、Scala提出了新的要求。不管是传统数仓,还是基于Hadoop生态的构建的(hive、spark、flink)数仓,SQL虽然戏码在下降,但依然是重头戏。
在数仓中sql的基本操作既简单又实用,sql中比较复杂和重要的就是join,下面用一张图清晰的解释了各种join的逻辑

SQL开发规范:
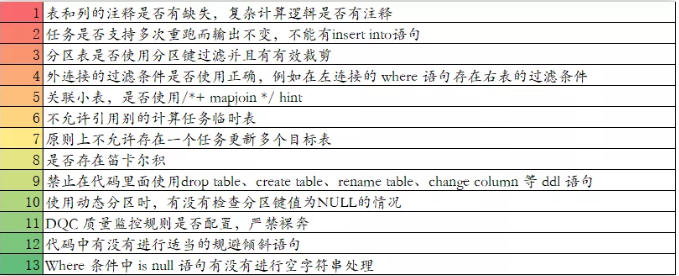
在大数据生态,不管哪种数据处理框架,总有一天都会孵化出强大SQL的支持。如Hive SQL,Spark SQL,Blink SQL 等。但本质上还是SQL
5.数据治理
大数据时代必不可少的一个重要环节,可从元数据管理、业务实体数据,数据质量、数据安全、数据生命周期等方面开展实施。数据治理是一个企业安身立命的根本。
元数据:
业务实体数据的标识,在大数据领域,一个数仓可以有成百上千,甚至成千上万或更多的表。这些表的含义,表的每个字段的含义只有通过元数据才能知道。
业务实体数据:
业务产生的数据的数据内容,业务实体数据以外的数据表都是为其服务的。
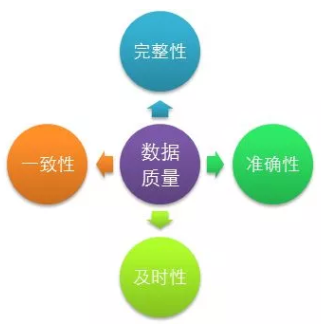
数据质量:
保证业务实体数据完整性、准确性、一致性、时效性。每一个操作业务实体数据的任务都应该配置数据质量监控,严禁任务裸奔。可建设统一数据质量告警中心从以下四个方面进行监控、预警和优化任务。
数据安全:
即数据的保密性、真实性、完整性、未授权拷贝和所寄生系统的安全性。
数据生命周期:
对于某些数据,用完可以删除掉,以便减少存储空间,数据生命周期数据定义了每个业务实体数据的周期,是否为热数据或冷数据,是否需要永久保留还是完成对应功能即可删除等
6.数仓的衍生
随着大数据的发展及互联网巨头对大数据技术的深耕及奉献,特别是阿里。在数仓的基础上衍生了数据湖和数据集市的概念
数据湖:
是一个集中化存储海量的、多个来源,多种类型数据,并可以对数据进行快速加工,分析的平台,本质上是一套先进的企业数据架构,关于数据湖的更多个人觉得这篇博文(http://www.raincent.com/content-10-14037-1.html)说的比较详细
数据集市
满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号