
clickhouse核心引擎MergeTree子引擎
在clickhouse使用过程中,针对数据量和查询场景,MergeTree是最常用也是较为合适的表引擎。针对特定的业务,MergeTree的子引擎可以针对不同的业务而定,但都基于MergeTree引擎
1. ReplacingMergeTree
说明:
该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。同时ReplacingMergeTree在一定程度上可以弥补clickhouse不能对数据做更新的操作。
a. 创建ReplacingMergeTree表
创表语法:

ver — 版本列。类型为UInt*,Date或``DateTime,可选参数。其他参数与父引擎MergeTree一样
被弃用的创表语法:

CREATE TABLE rmt_tab(date Date,id UInt8,name String,version UInt8) ENGINE=ReplacingMergeTree(version) PARTITION BY date ORDER BY (id,name) SAMPLE BY name
b. 插入数据
insert into rmt_tab values ('2019-07-11',1,'Jason',1);
insert into rmt_tab values ('2019-07-11',1,'Jason',1);
insert into rmt_tab values ('2019-07-11',1,'Jason',2);
insert into rmt_tab values ('2019-07-12',2,'Tom',1);
insert into rmt_tab values ('2019-07-12',2,'Tom',1);
insert into rmt_tab values ('2019-07-12',2,'Tom',2);
c. 等待后台自动merge或通过optimize table rmt_tab命令手动Merge后查询

name为Jason的数据并未去重,而name为Tom的数据去重后只有一条。总共有四片数据
d. 使用场景
在数据过多重复场景对数据进行去重
2. SummingMergeTree
说明:
当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值
a. 创建SummingMergeTree表
创表语法:

被弃用的语法:

CREATE TABLE smt_tab(date Date,id UInt8,name String,a UInt16) ENGINE=SummingMergeTree(a) PARTITION BY date ORDER BY (id,name) SAMPLE BY name
b. 插入数据
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',1)
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',2)
insert into smt_tab (date,id,name,a) values ('2019-12-12',1,'Jason',3)
c. 等待后台自动merge或通过optimize table smt_tab命令手动Merge后查询
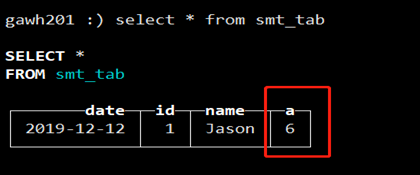
在非a列的相同的情况下,只有一行数据,a列被sum了。
相当于已经做了以下语句的操作:
select date,id,name,sum(a) from smt_tab group by a;
注意:
如果用于汇总的所有列中的值均为0,则该行会被删除。
如果汇总的类为主键则不会被汇总
d. 使用场景
对某个字段长期的汇总查询场景
3.AggregatingMergeTree
说明:
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将相同主键的所有行(在一个数据片段内)替换为单个存储一系列聚合函数状态的行。
可以使用 AggregatingMergeTree 表来做增量数据统计聚合,包括物化视图的数据聚合。
引擎需使用 AggregateFunction 类型来处理所有列。
如果要按一组规则来合并减少行数,则使用 AggregatingMergeTree 是合适的。
对于AggregatingMergeTree不能直接使用insert来查询写入数据。一般是用insert select。但更常用的是创建物化视图
a. 先创建一个MergeTree引擎的基表
CREATE TABLE amt_basic_tab(date Date,D1 String,D2 String,D3 String,M1 UInt16) ENGINE MergeTree() PARTITION BY date ORDER BY (D1,D2,D3)
b. 往基表写入数据
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'a', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'a', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '甲', 'b', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '乙', 'b', '3', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丙', 'b', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丙', 'c', '1', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丁', 'c', '2', 1);
insert into amt_basic_tab (date, D1, D2, D3, M1) values ('2017-07-10', '丁', 'a', '1', 1);
c. 创建一个AggregatingMergeTree的物化视图
create materialized view amt_tab_view ENGINE = AggregatingMergeTree() PARTITION BY date ORDER BY (D2,D3) as select date,D2, D3, uniqState(D1) as uv from amt_basic_tab group by date,D2,D3;
d. 根据b往基表写数据的方法重写写一次将数据填充到物化视图amt_tab_view中并查询
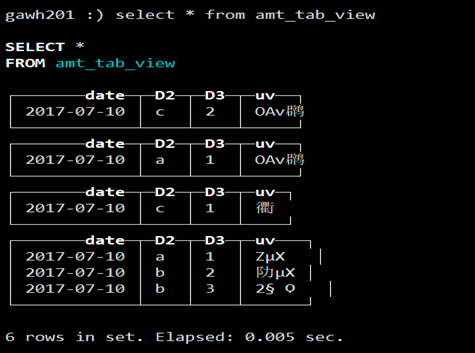
可以看出数据有四片
e. 通过optimize table amt_tab_view命令手动Merge后查询
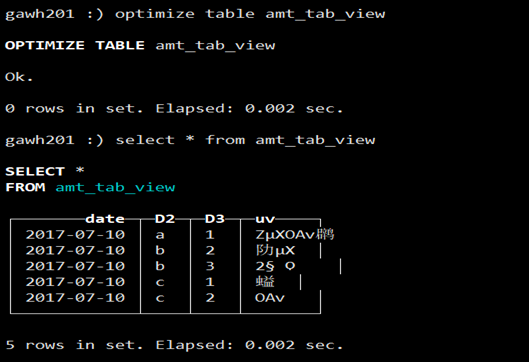
数据只有一片了
这里可能还是没有明白AggregatingMergeTree的作用
对比基表amt_basic_tab和物化视图amt_tab_view的数据就很清晰了
amt_basic_tab:
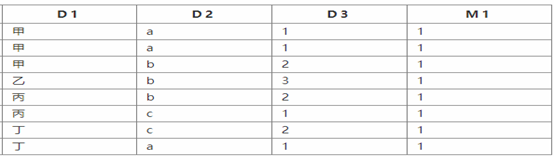
amt_tab_view

f. 使用场景
可以使用AggregatingMergeTree表来做增量数据统计聚合,包括物化视图的数据聚合。
4. CollapsingMergeTree
说明:
yandex官方给出的介绍是CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。该引擎可以显著的降低存储量并提高 SELECT 查询效率。
CollapsingMergeTree引擎有个状态列sign,这个值1为”状态”行,-1为”取消”行,对于数据只关心状态列为状态的数据,不关心状态列为取消的数据
a. 创建CollapsingMergeTree表
创表语法:

CREATE TABLE cmt_tab(sign Int8,date Date,name String,point String) ENGINE=CollapsingMergeTree(sign) PARTITION BY date ORDER BY (name) SAMPLE BY name
b. 插入数据:
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','cctv','100000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','cctv','100000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hntv','10000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hntv','10000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-13','hbtv','11000')
insert into cmt_tab(sign,date,name,point) values (-1,'2019-12-13','hbtv','11000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','cctv','200000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hntv','15000')
insert into cmt_tab(sign,date,name,point) values (1,'2019-12-14','hbtv','16000')
c. 通过optimize table amt_tab_view命令手动Merge后查询
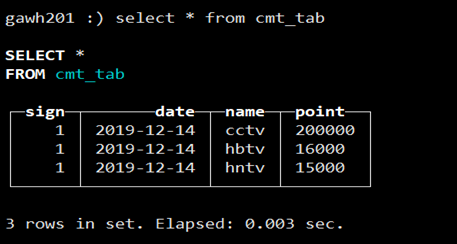
d.使用场景
大数据中对于数据更新很难做到,比如统计一个网站或TV的在用户数,更多场景都是选择用记录每个点的数据,再对数据进行一定聚合查询。而clickhouse通过CollapsingMergeTree就可以实现,所以使得CollapsingMergeTree大部分用于OLAP场景
5. VersionedCollapsingMergeTree
这个引擎和CollapsingMergeTree差不多,只是对CollapsingMergeTree引擎加了一个版本,比如可以适用于非实时用户在线统计,统计每个节点用户在在线业务
a. 创表语法


