MySQL(3)
外部数据导入MySQL:
开发给一个sql脚本,导入到数据库里的方法:(sql脚本里有创建命令)
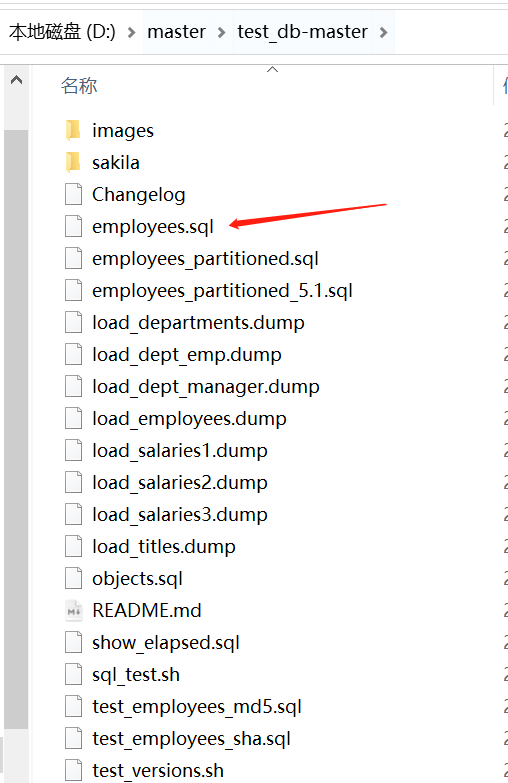
cmd →
进入这个文件的地址(sql脚本的地址)→
“连接mysql的命令<sql脚本名称”
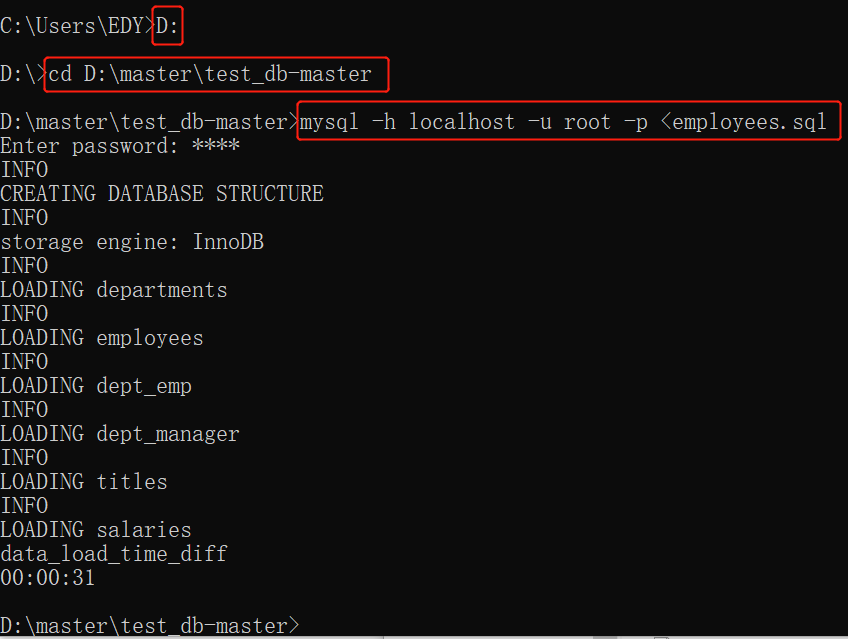
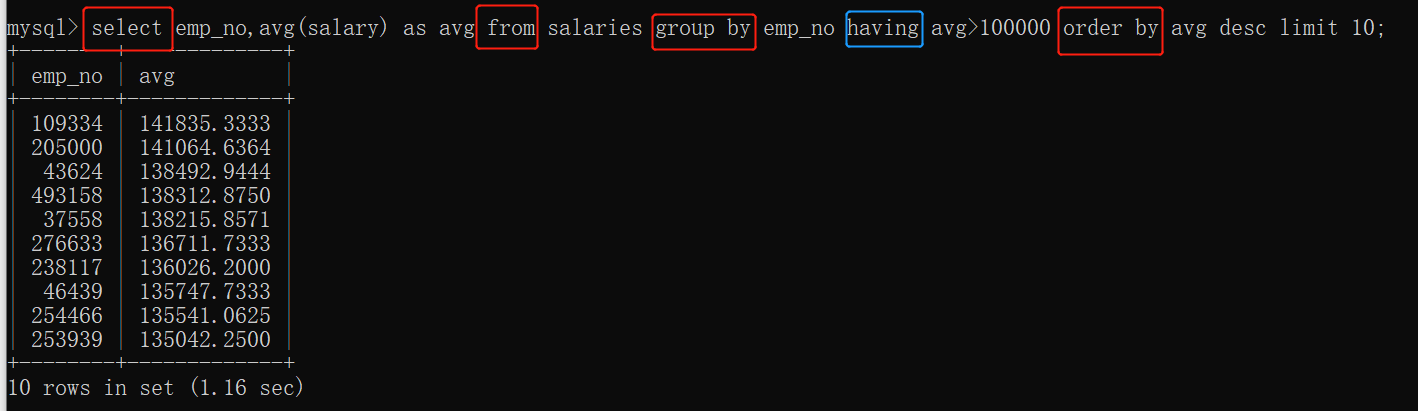
查询规定的多少行数据:
limit
select * from 表名 limit 数字;
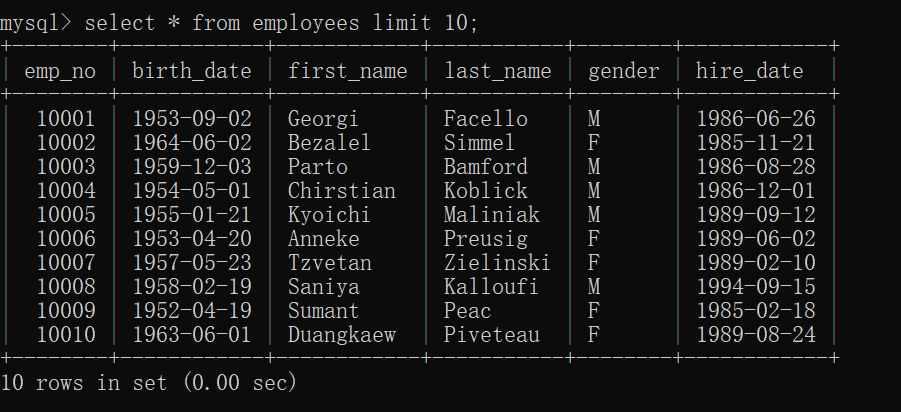
注意:limit是对计算后的数据显示行数,而不是计算前的数据
select 字段1,字段2 from 表名 limit 数字;
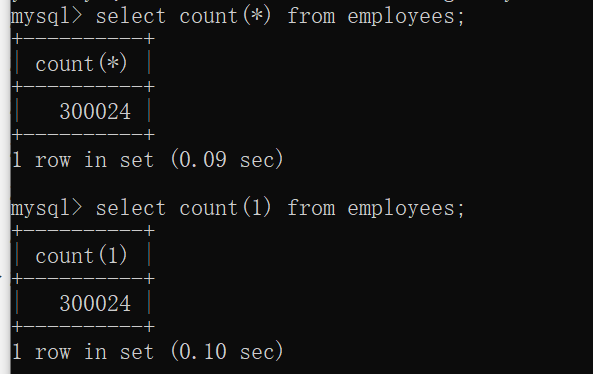
查询表有多少条记录:(数据行数)
select count(*) from 表名;
select count(1) from 表名;
条件过滤,用在where子句中
并且:
and
select * from 表名 where 条件1 and 条件2;
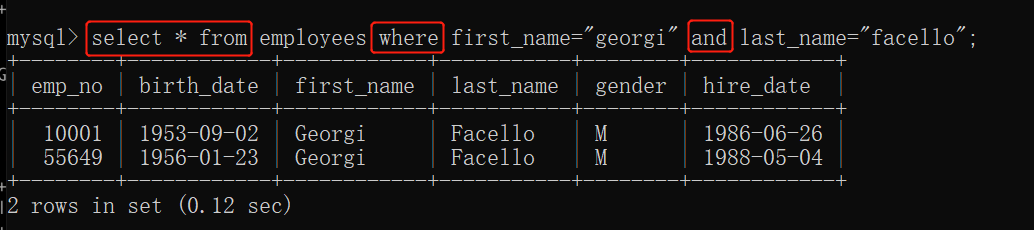
(同时满足条件1和条件2 的所有数据信息)
or
select * from 表名 where 条件1 or 条件2;
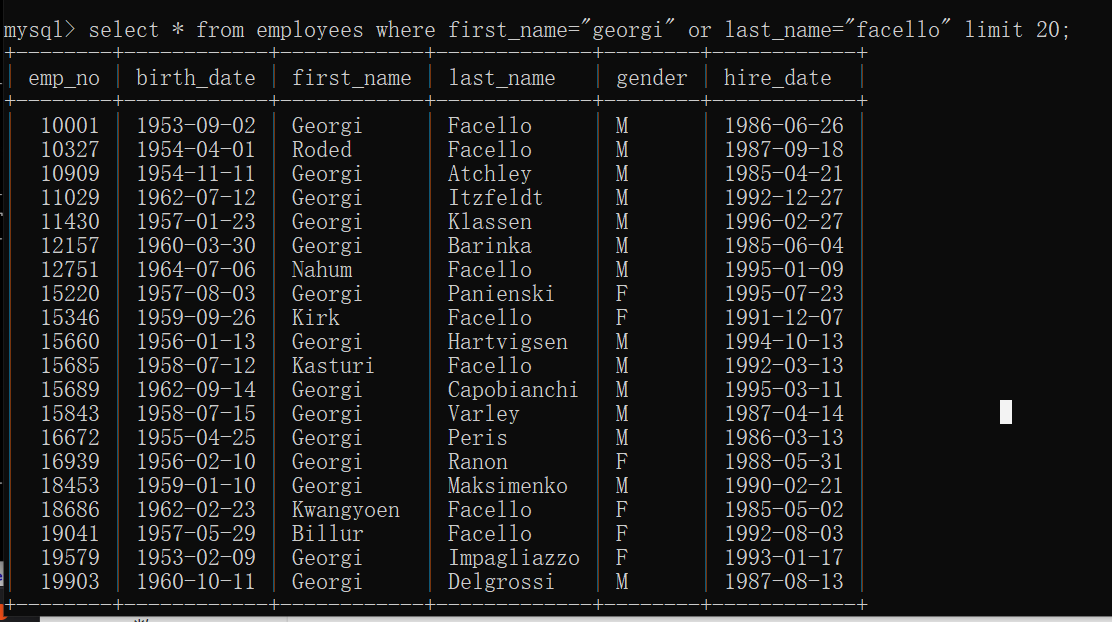
(满足条件1或条件2 的所有数据信息)
包含:
select * from 表名 where 字段 in(条件1,条件2);
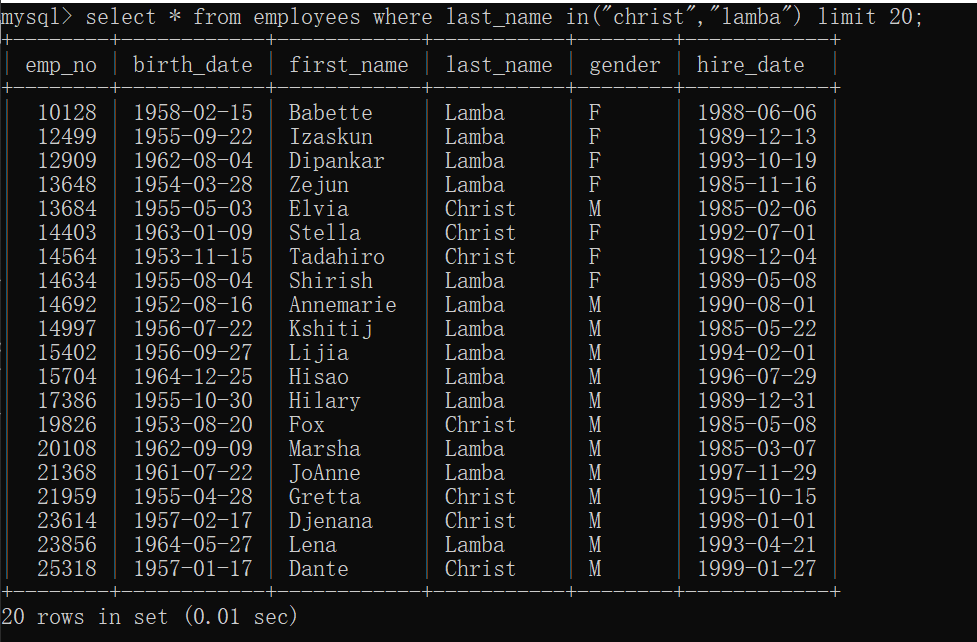
只要符合其中一个,就显示出来。
范围检查:
between ...and...
select * from 表名 where 字段 between “条件1” and “条件2” ;
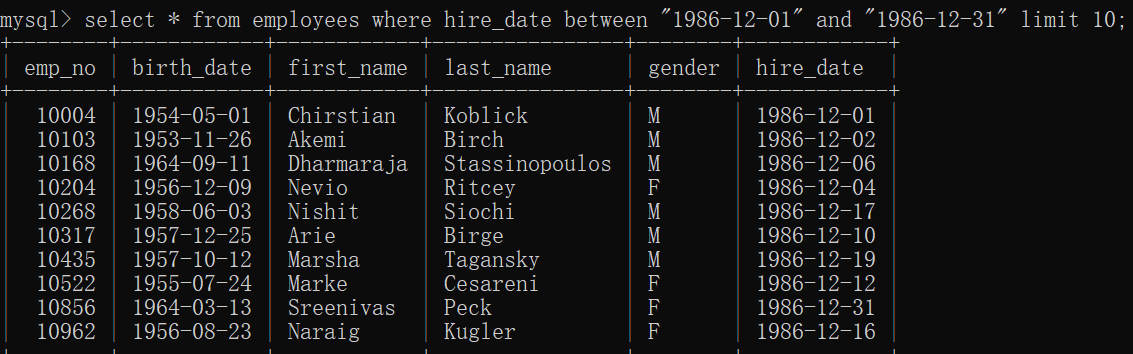
(条件1和条件2 之间的所有数据,包含开始和结束,一般用在一个范围内)
否定:
如:not in(不包含)
not between...and... (不在...范围内)
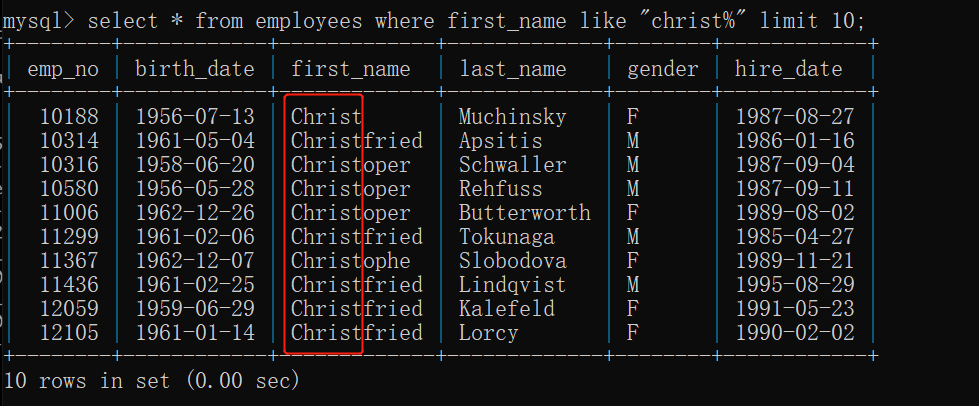
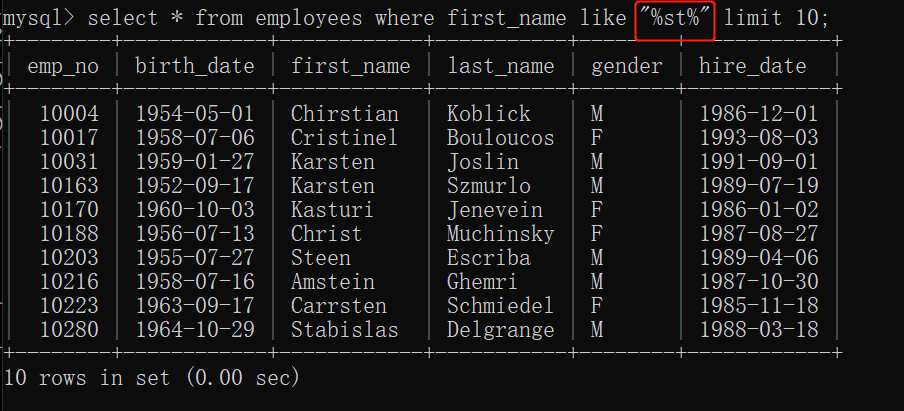
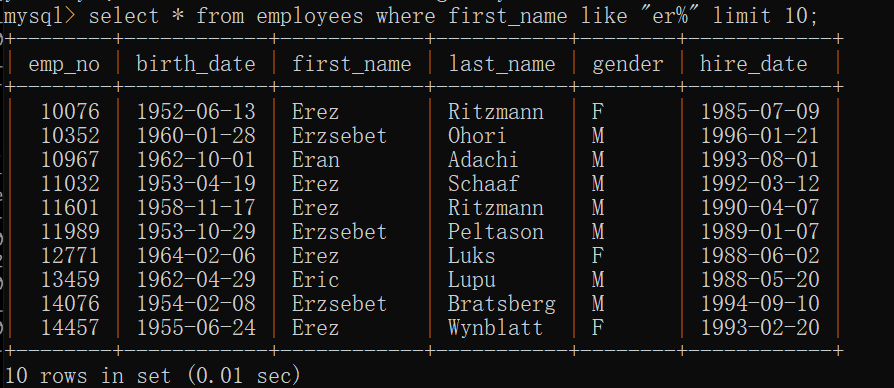
模糊查询
select * from 表名 where 字段 like “ % ” ;
匹配一个或多个任意字符,%的位置可以在前、后、中间。
下划线
几个下划线,表示有几个字符,可以和%结合使用。
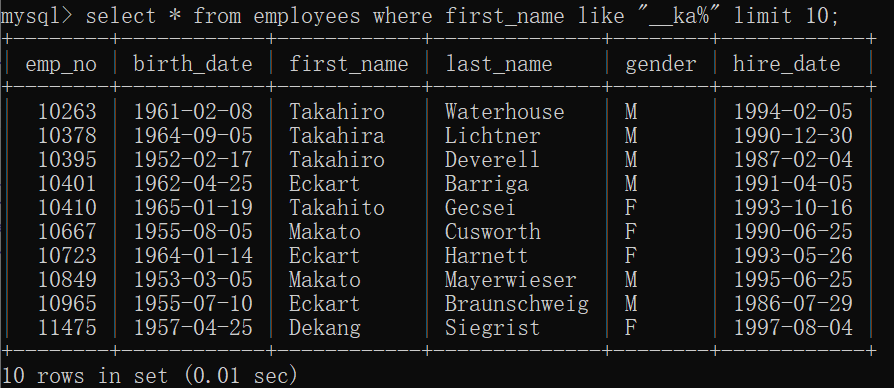
以什么开头:
“^ ”
(^放在字母前面。不能和%结合使用,注意引号前面是rlike)
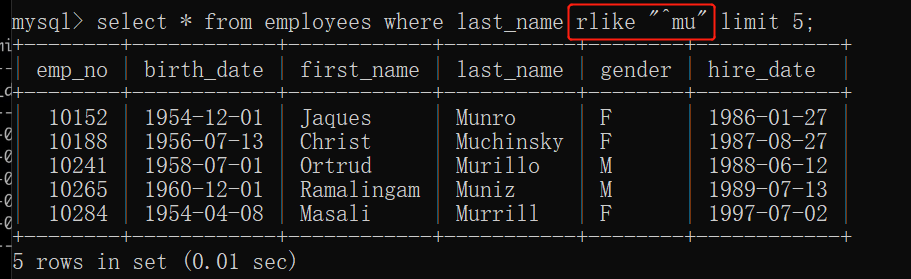
以什么结束:
“ $”
($放在字母后面。注意引号前面是rlike)
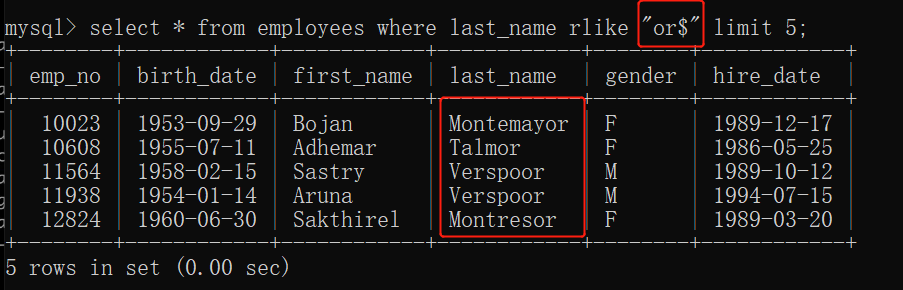
使用别名:
原字段 as 新起名
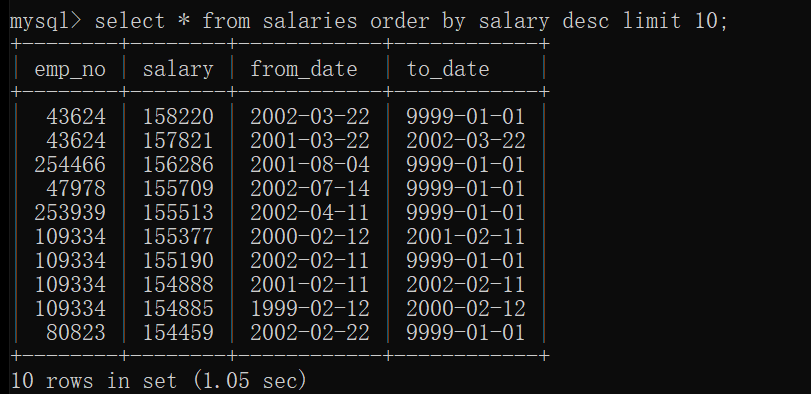
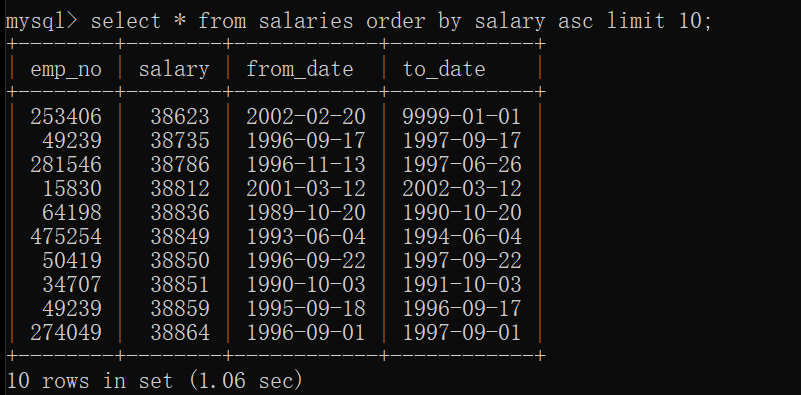
把字段进行排序:
select * from 表名 order by 字段 升序/降序;
(desc 降序 asc 升序, 不加顺序时 默认是升序)
聚合函数
聚合函数作用:把多个数据做整合输出一个数据。(对于一组数据进行计算返回单个结果的实现过程。) 使用聚合函数方便进行数据统计。
聚合函数不能在where子句中使用。(不能用在where后面,可以用在where前面)
having中可以使用聚合函数。
聚合分组:
按照字段分组,就是把这个字段 中相同的数据 的行都放到一行中,这时候可以想象出一个虚拟表。分组的目的是对每一组的数据进行统计(一般搭配使用聚合函数)。
(比如以性别分组,就是把所有男生分为一组,所有女生分为一组,至于这些人的别人信息你可以想象他们放在同一行中,然后再对这些信息做聚合函数。)
格式:
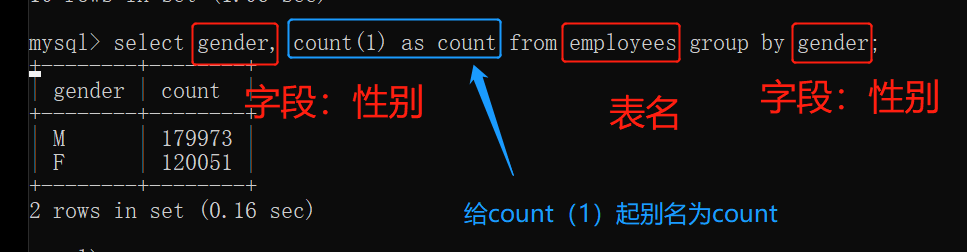
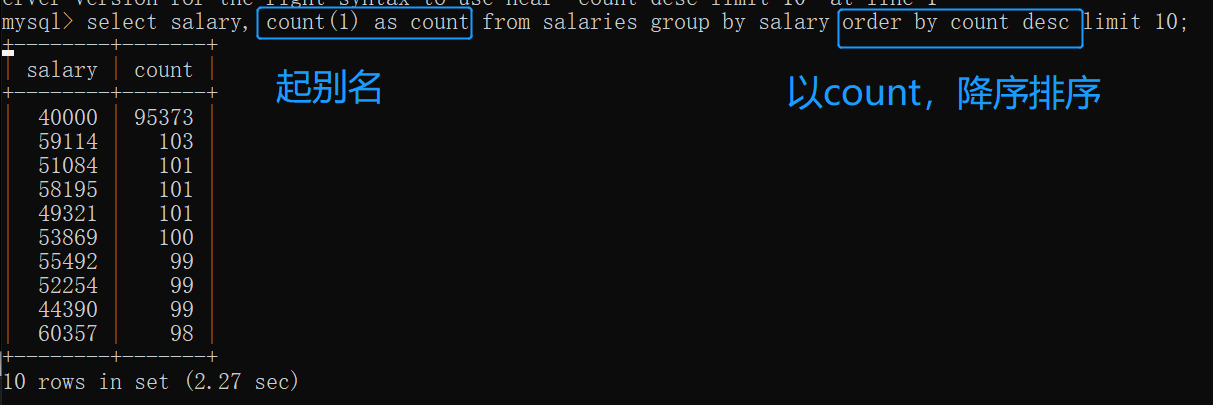
select 字段,聚合函数 from 表名 group by 字段;
(格式如上,可以理解成先分组再计算其中数据)
查询总行数(总记录数):
count(1)
例:
以性别做为聚合分组,查询这些不同性别的总人数信息:(男一共多少人,女一共多少人)
以薪资做为聚合分组,查询这些不同薪资的总人数信息:
查询最大/最小/平均/总数
最大 max( ),最小 min( ), 平均 avg( ), 总数sum( )
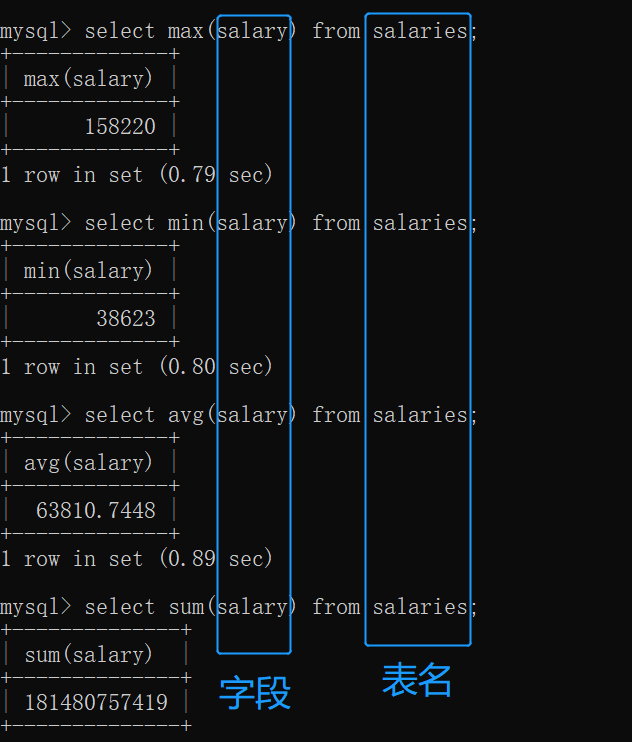
例:
从from_date字段中查找year 并且起别名为dateyear,以dateyear为聚合分组,查找这些不同年份的平均薪资,用平均薪资avg来降序排序。(字段后面as起别名)
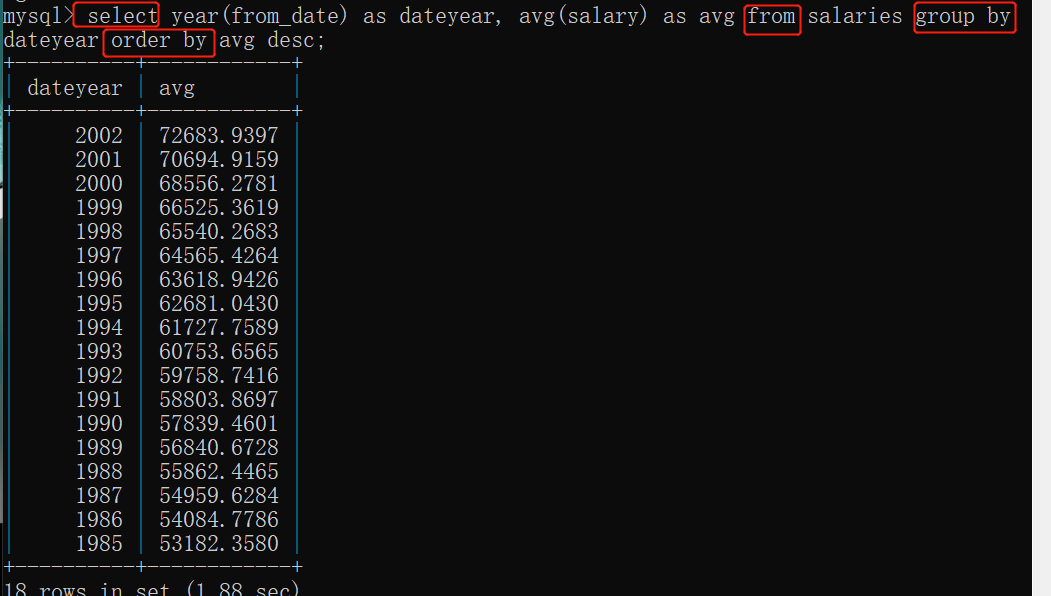
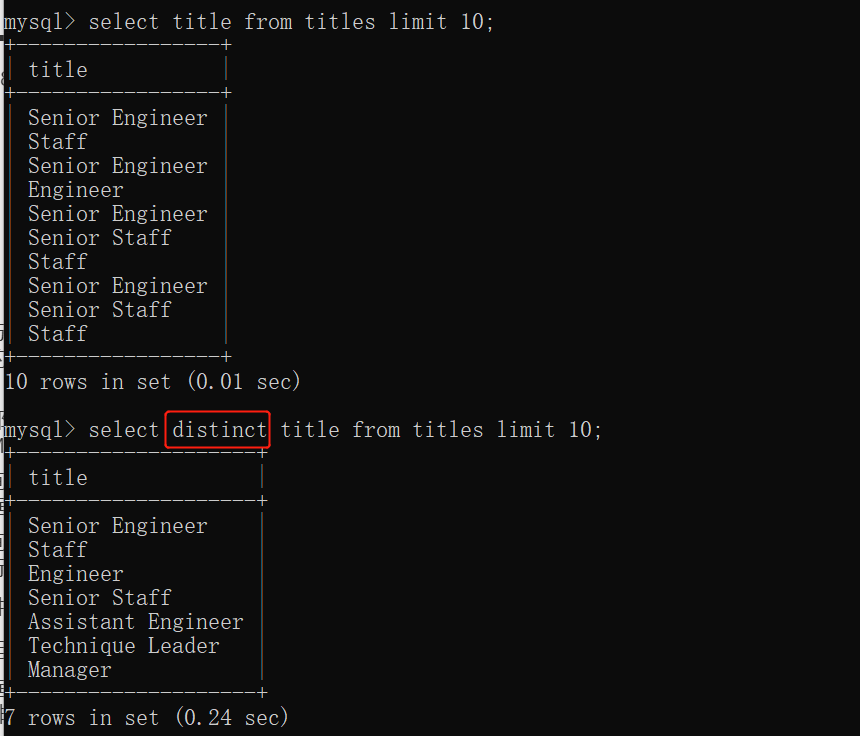
去重查询
distinct
查询出表的某个字段中所有不相同的数据
过滤
having where 聚合函数 where group by having 聚合函数
having和where的区别:
where是对from后面的表进行数据筛选,属于对原始数据的筛选,可以用在group by 分组之前。
having是对 group by 的结果进行筛选,只能用在分组之后。
having后面的条件中可以使用聚合函数,where后面不可以使用聚合函数,where前面可以。
-where前面可以有聚合函数、后面可以有分组;
-having前面可以有分组、后面可以有聚合函数。
navicat工具
连接:
1.点连接,选择mysql
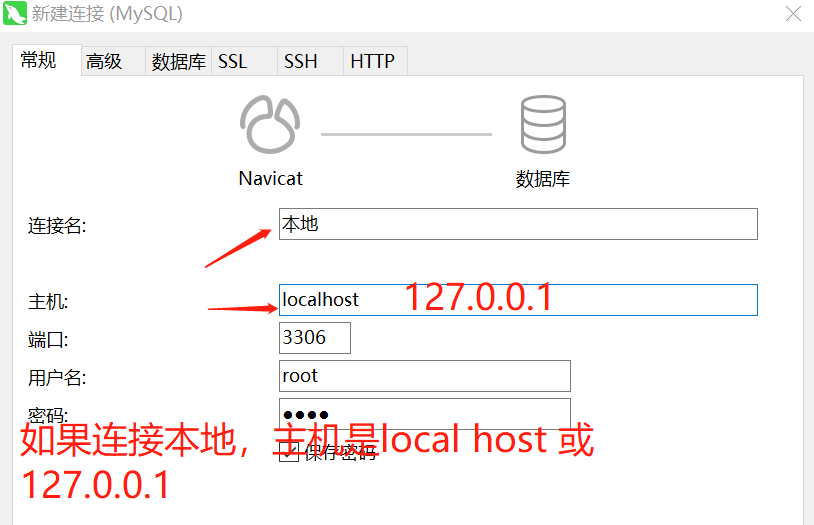
2.常规连接方法:
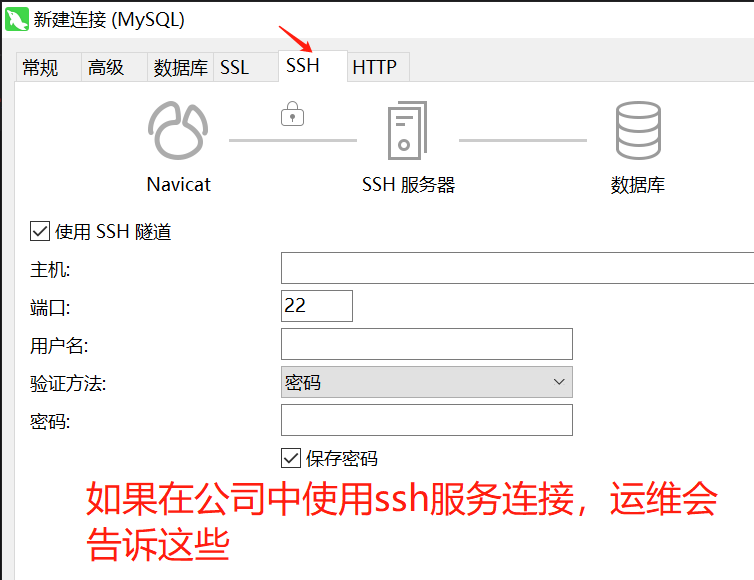
ssh服务连接:
使用:
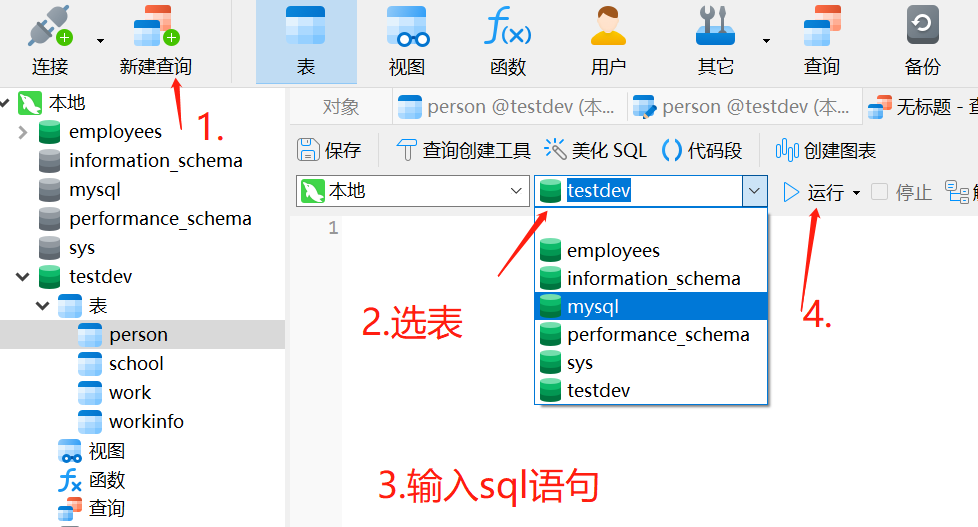
内连接:
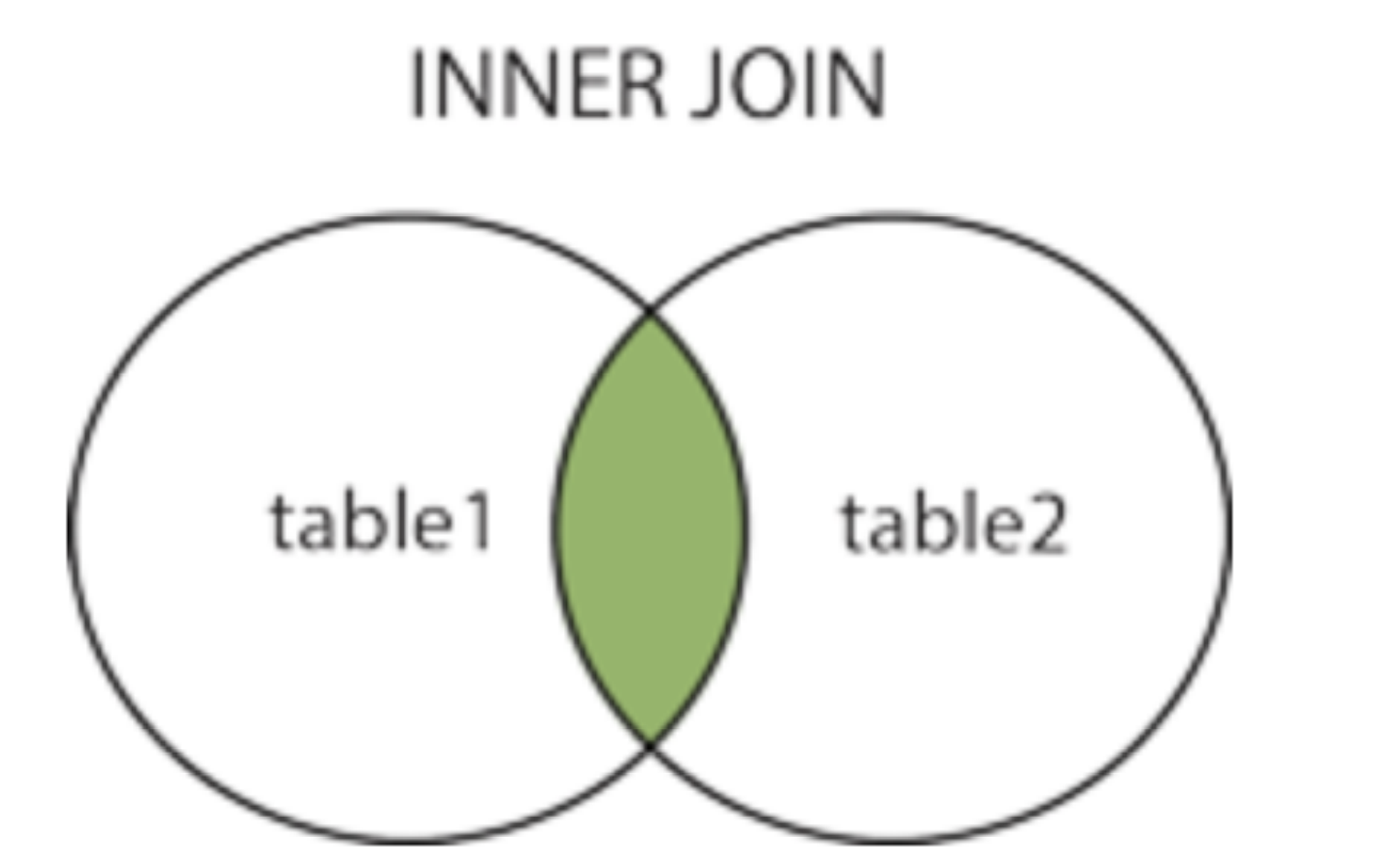
inner join....on........,⼜叫内连接的部分,主要是获取两个表中字段有匹配关系的部分。查询关联字段共同拥有的数据。(有交集的部分)
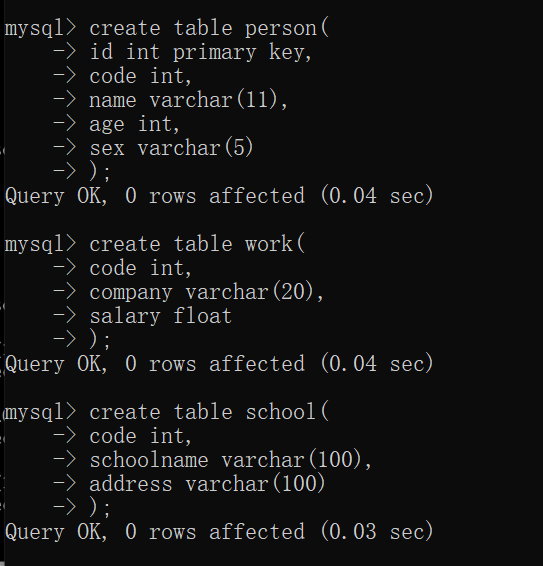
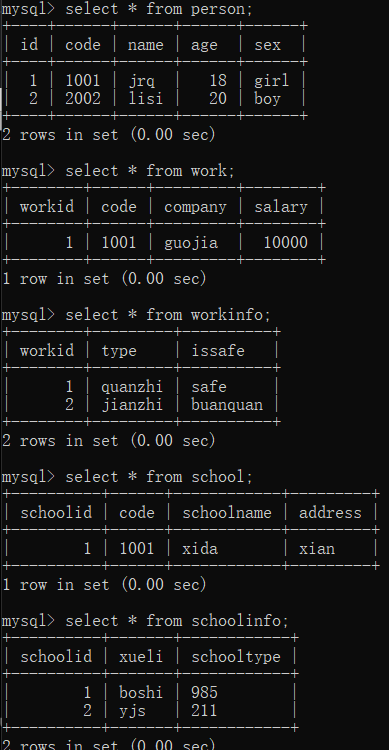
1.创建三个表,想要通过code连接起来,所以每个表中都添加code字段:
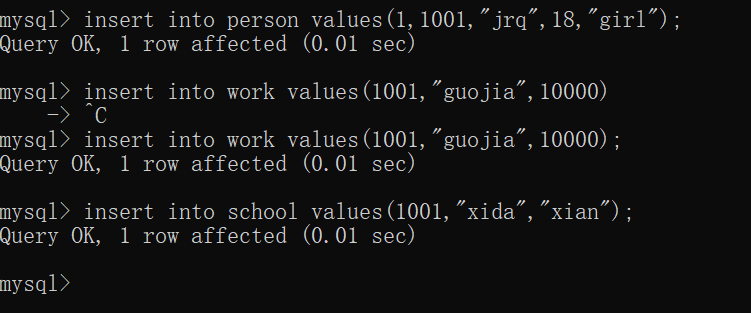
2.在表中插入数据,每个表的code都输入一样的数据,后面就可以通过code相等把三个表连接起来:
3.通过code三表连接,查询code=1001的人的名字、年龄、公司、学校:

格式:
select 表1/2数据... from 表1 inner join 表2 on 连接条件 where 表达式;
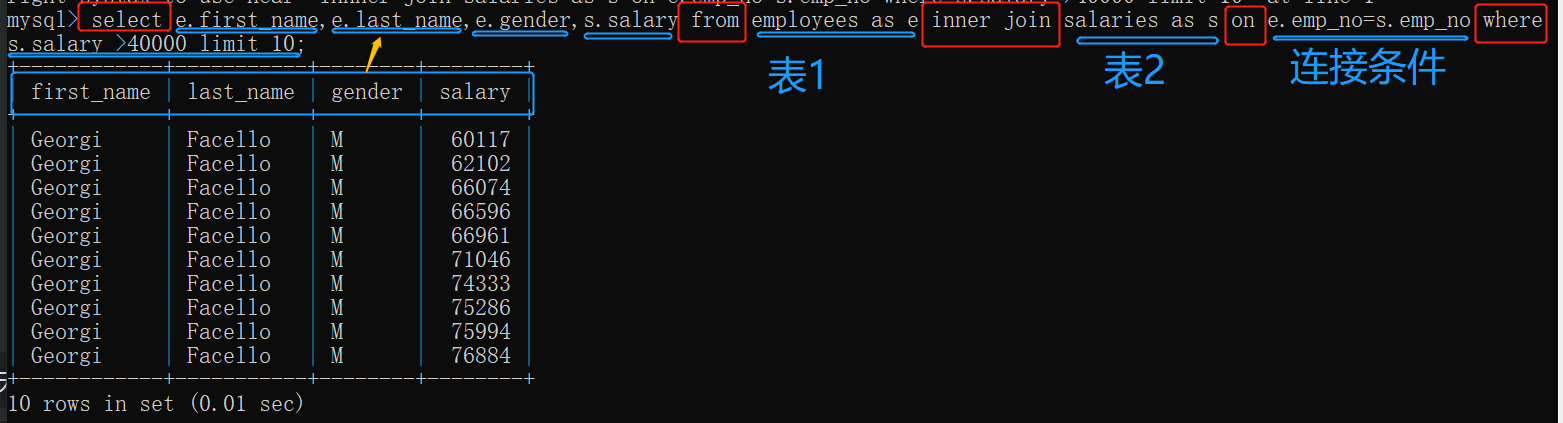
(在不同表中查找字段时,要标清字段所在的表,如上图,在前面直接使用别名,在后面给表起别名)
外连接:
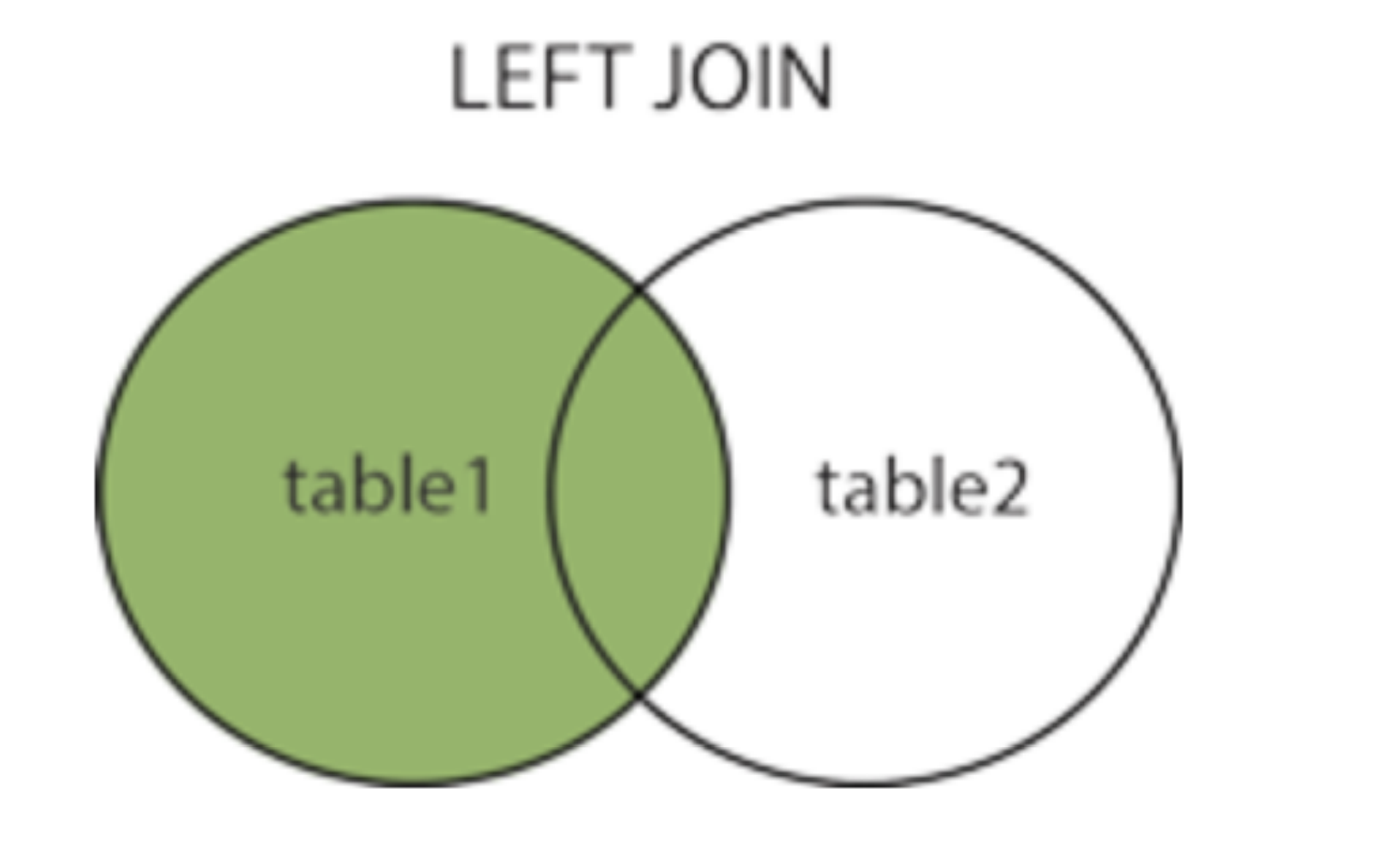
左连接 left join....on..... (left join的左边写的表是主表)
获取左表所有记录,获取左边数据表所有符合要求的字段数据信息。
在内连接的基础上保留左表没有对应关系的记录。
select 表1/2/3字段...
from 表1
left join 表2
on 连接条件
left join 表3
on 连接条件
left join 表4
on 连接条件
where 表达式;
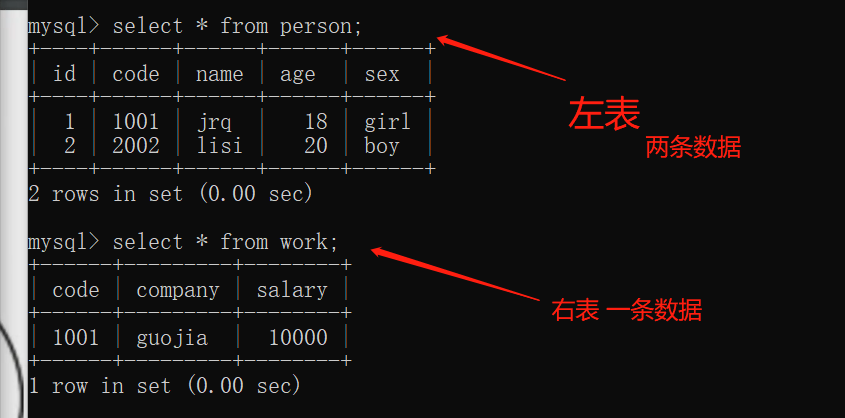
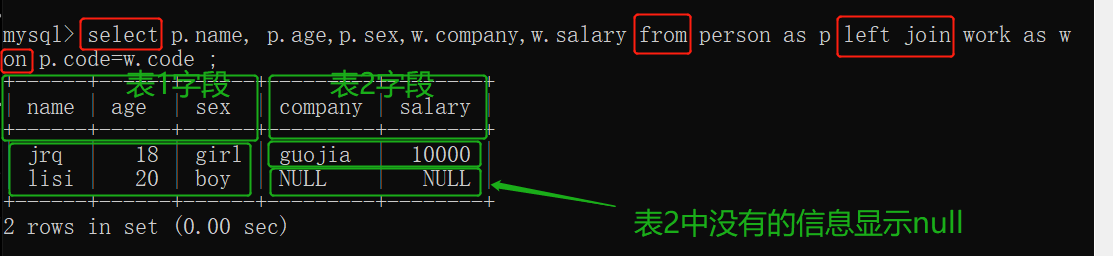
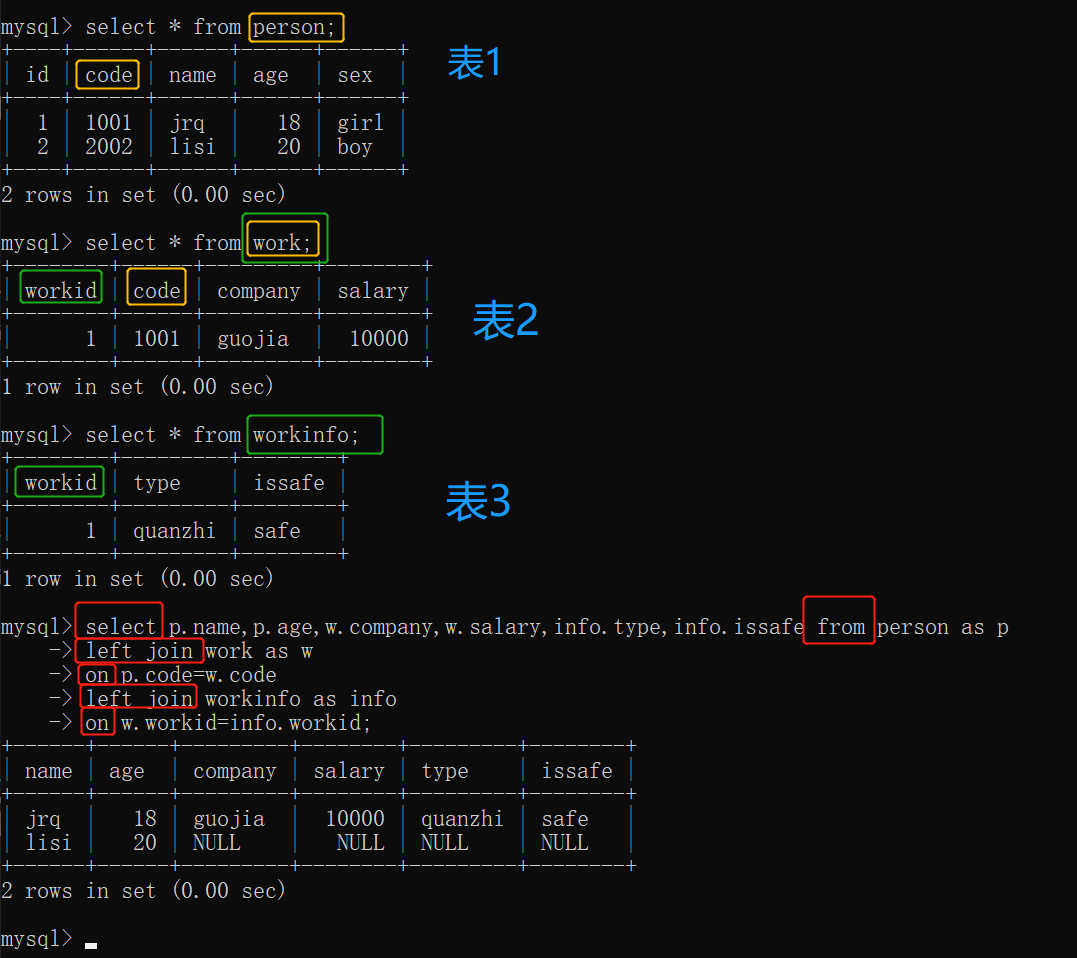
从person表中查询name age sex,从work表中查询company salary, person与work表进行左连接(也就是 以person为主表,person表中的数据全部显示),连接条件是两表的code相等(也就是 work表中显示和person表的code相等的数据信息)。
【总结】:左连接or右连接确定了 左边的表是主表还是右边的表是主表,连接条件决定了另一个表会显示的内容信息。
例1:
控制台:
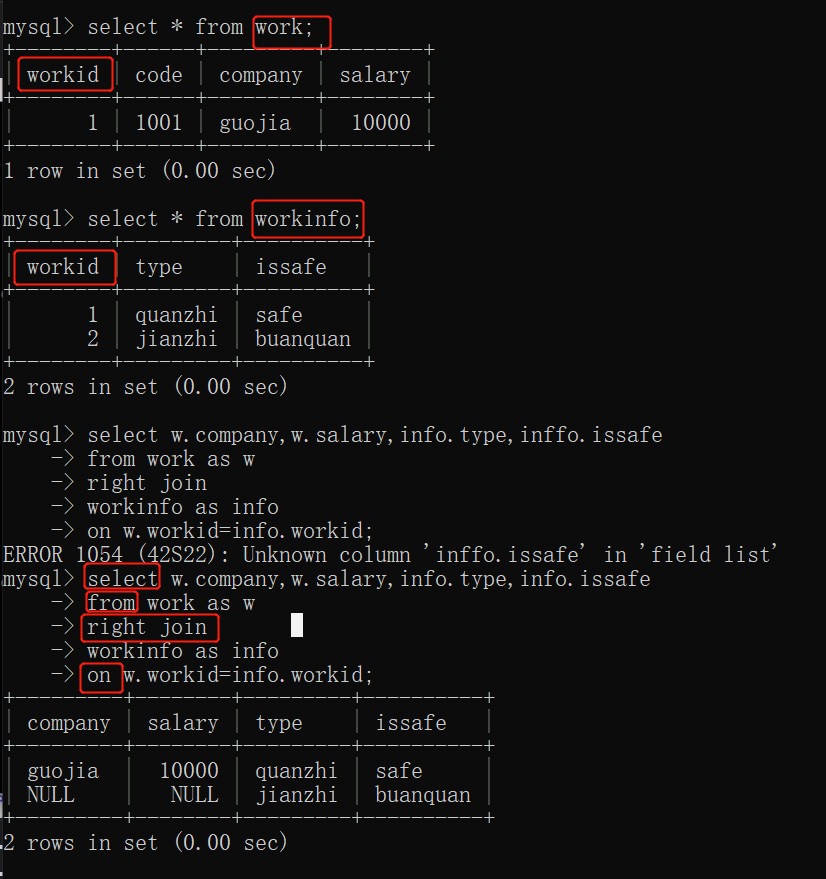
三表连接:表1和表2 通过code连接,表2和表3通过workid连接。
navicat:
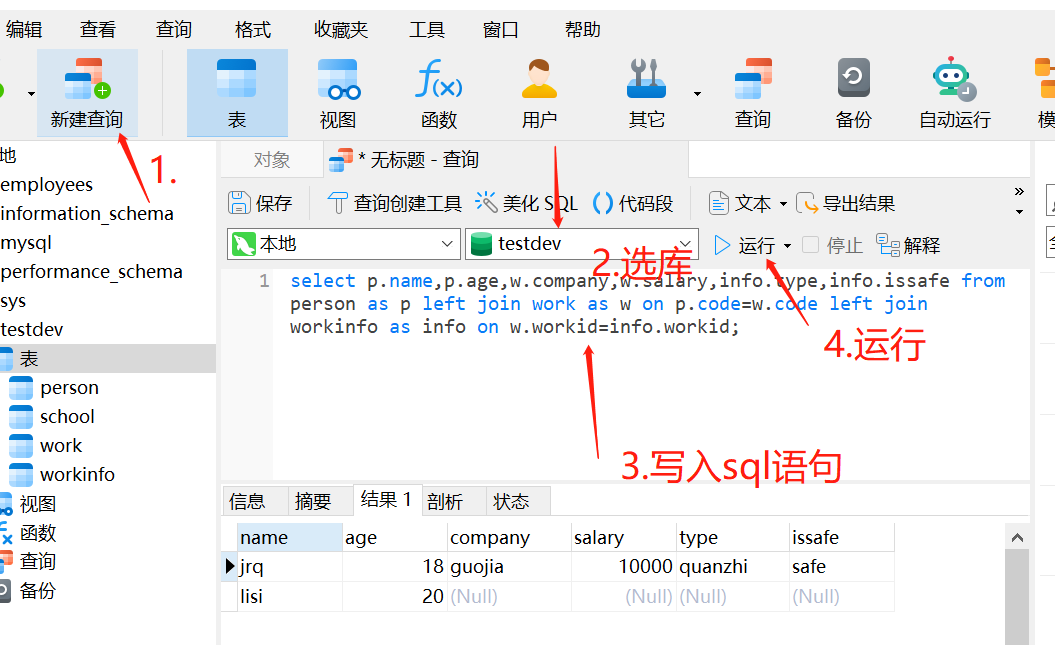
例2:
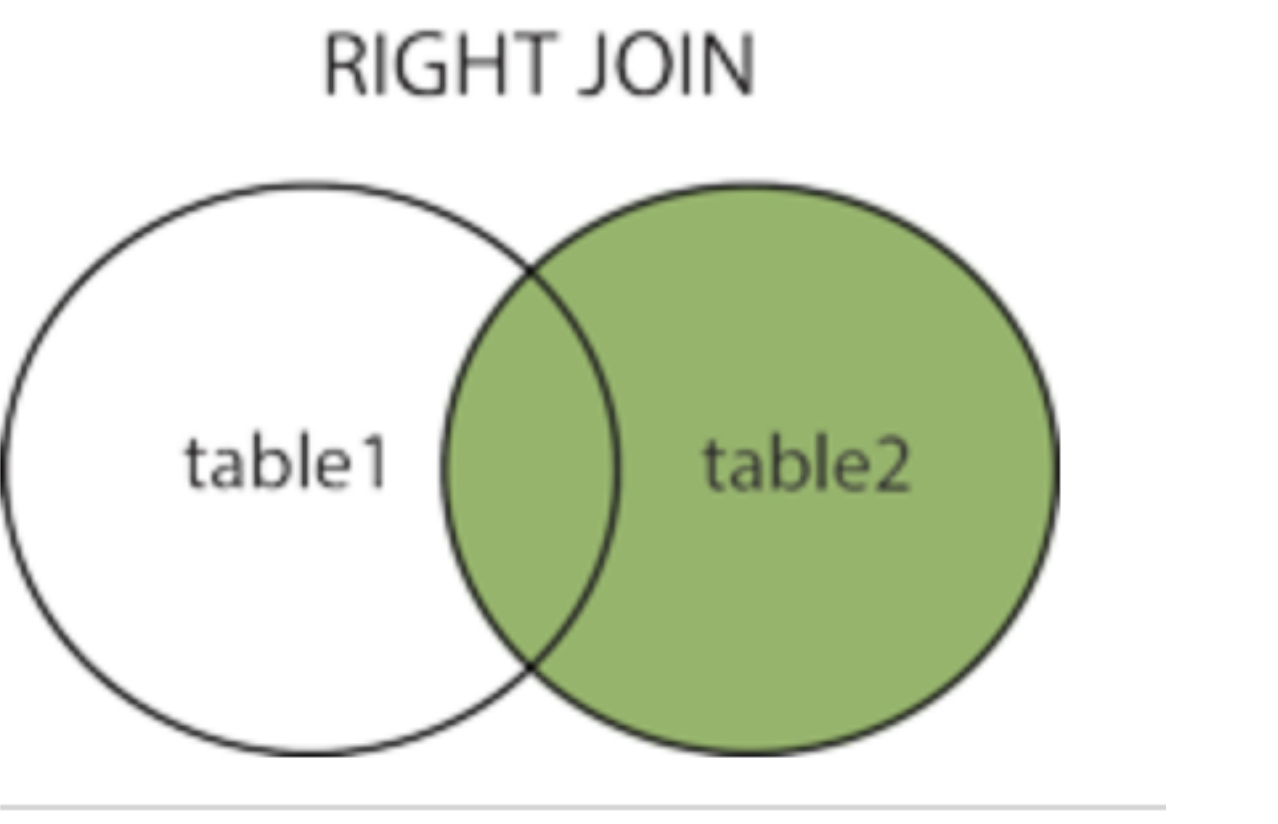
右连接 right join....on.... (right join的右边写的表是主表)
获取右表所有记录的信息,获取右边数据表所有的数据信息。
在内连接的基础上保留右表没有对应关系的记录。
select 表1/2/3字段...
from 表1
right join 表2
on 连接条件
right join 表3
on 连接条件
right join 表4
on 连接条件
where 表达式;
例1:
例2:
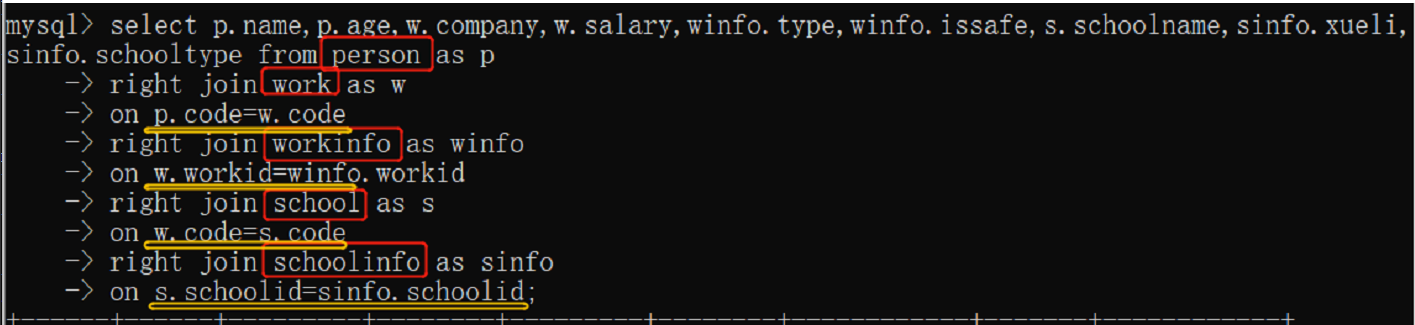

上图:school和workinfo没有连接条件,school就和work连接
注意:
左连接时:left join 左边的表作为主表,主要为了将左表的信息全部查询显示出来。捎带着关联查询满足连接条件的右表数据,关联不上的显示为null。
右连接时:right join右边的表作为主表,主要为了将右表的信息全部查询显示出来。捎带着关联查询满足连接条件的左表数据,关联不上的显示为null。
多表连接时:可以内连接和外连接结合使用。如果是内连接、顺序都可以,但如果是有外连接的话,要考虑外连接的顺序,谁作为外连接的主表。
总结:多表使用外连接时,要关注连接的顺序。(多表连接可以理解成两个表连接后再与第三个表连接)
使用什么连接,这个主要看需求。你主要要获取那个表的数据,一般应该作为主表。
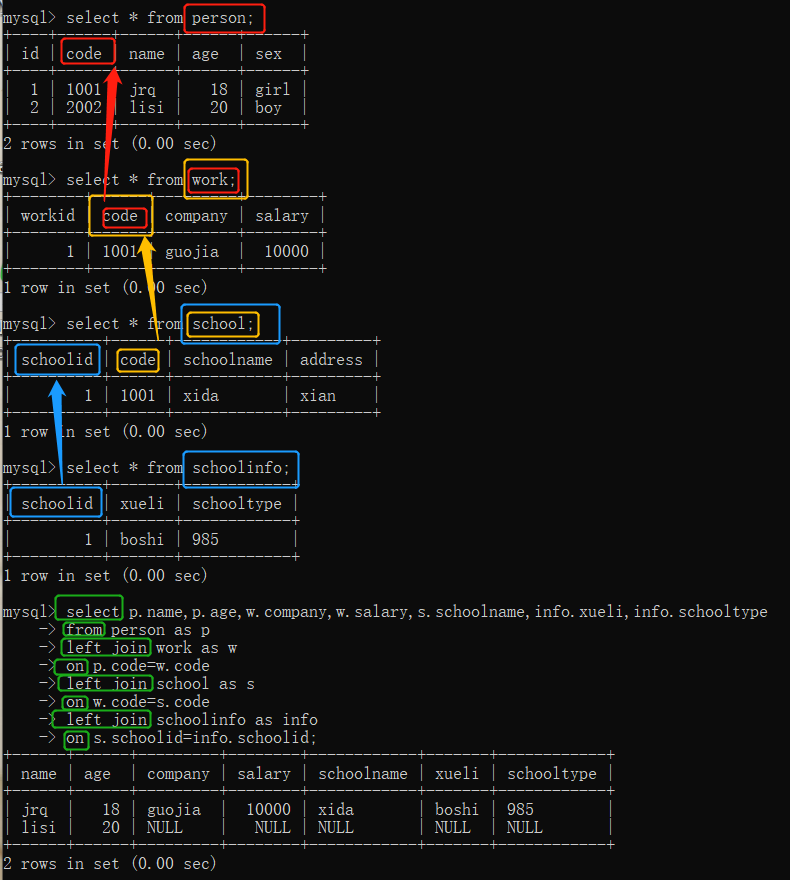
需求:
查询出姓名,学历,学校类型
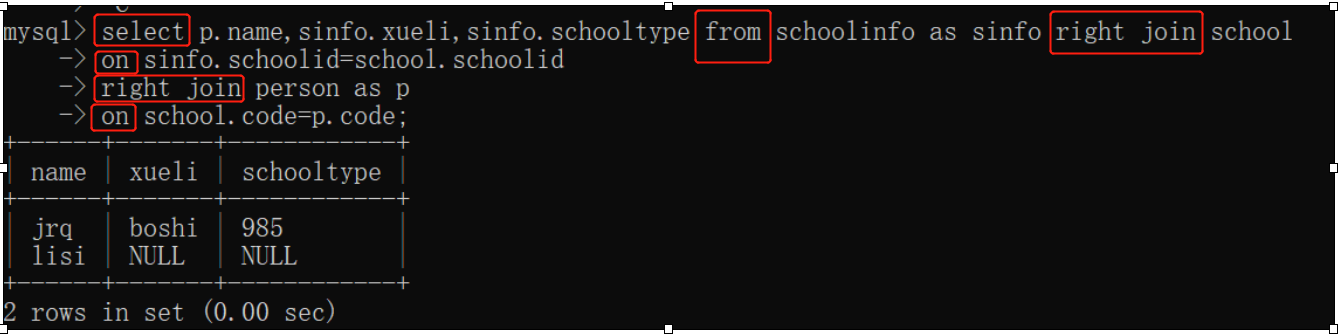
查找person表里的姓名,school表里的学历和学校类型,但是两表没有连接关系,所以借助中间的表schoolinfo来连接。
子查询:
后一句的结果 是前一句的入口。嵌套语句,被嵌套的语句称为子查询。
select * from 表1 where 字段 in (select 字段 from 表2 where 表达式);
表达式可带可不带。
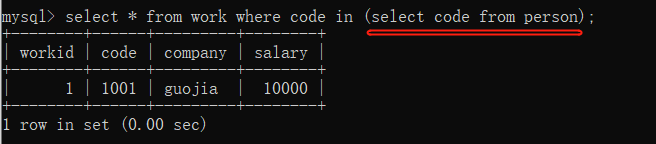
索引
在MySQL中,创建MySQL的索引主要是为了提⾼MySQL查询的效率。但是添加太多的索引也是会降低更新表的速度的,因为对表进行DML操作的时候,MYSQL的内部不仅仅要保存数据,还需要保存索引文件的。
添加表的时候添加索引:
index 索引名(字段)
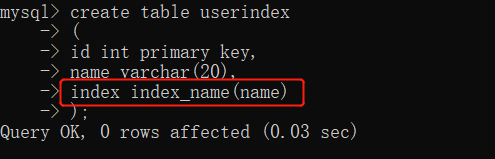
表已经存在时添加索引:

drop index 索引名 on 表名;
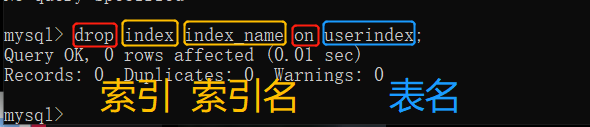
通过创表过程可以看到索引的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号