pytrhon re
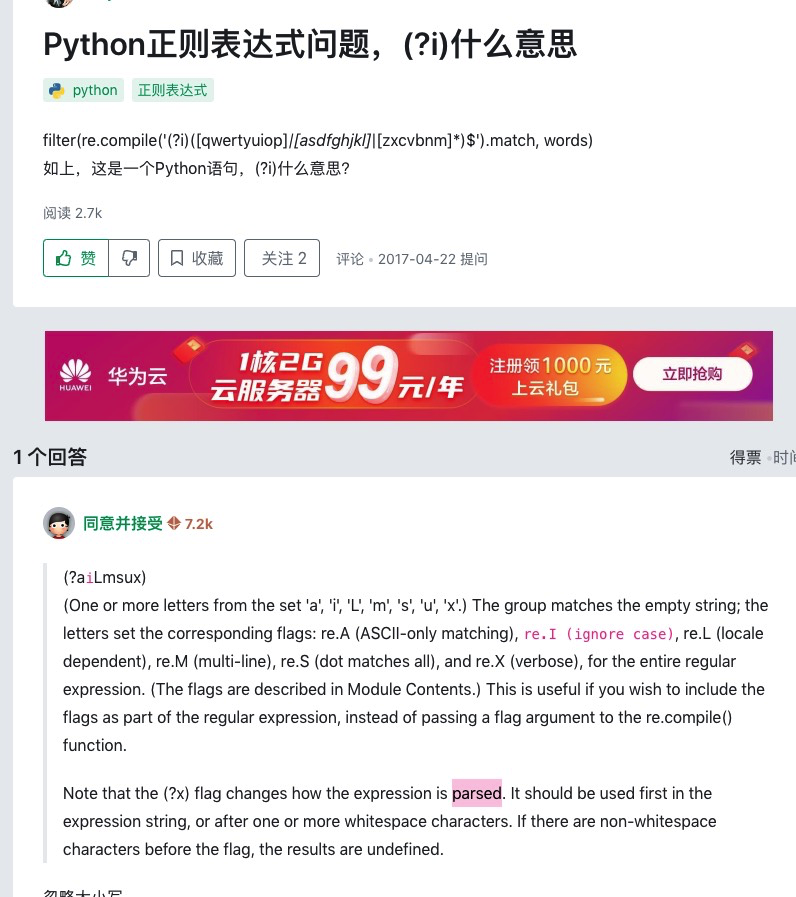
1, ?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容
2,match
match()函数(以后常用)
match,从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
match(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
import re
str="hello egon bcd egon lge egon acd 19"
r=re.match("h\w+",str) #match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None,非字母,汉字,数字及下划线分割
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
hello
()
{}
r2=re.match("h(\w+)",str) #match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
print(r2.group())
print(r2.groups())
print(r2.groupdict())
hello
('ello',)
{}
r3=re.match("(?P<n1>h)(?P<n2>\w+)",str) #?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容
print(r3.group())
print(r3.groups())
print(r3.groupdict())
hello
('h', 'ello')
{'n1': 'h', 'n2': 'ello'}
3, search
search()函数
search,浏览全部字符串,匹配第一符合规则的字符串,浏览整个字符串去匹配第一个,未匹配成功返回None
search(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
4,findall
findall()函数
findall(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表
注意:一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配
注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串
注意:正则只拿组里最后一位,如果规则里只有一个组,匹配到的字符串里在拿组内容是,拿的是匹配到的内容最后一位
import re
r=re.findall("(ca)*","ca2b3caa4d5") #浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串方到一个列表中
print(r)
['ca', '', '', '', 'ca', '', '', '', '', '']#用*号会匹配出空字符
5,split
根据正则匹配分割字符串,返回分割后的一个列表
split(pattern, string, maxsplit=0, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# maxsplit:指定分割个数
# flags : 匹配模式
6,替换
sub()函数
替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型
# repl : 要替换的字符串
# string : 要匹配的字符串
# count : 指定匹配个数
# flags : 匹配模式
复制代码
import re
r=re.sub("a\w","替换","sdfadfdfadsfsfafsff")
print(r)
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
sdf替换fdf替换sfsf替换sff
subn()函数
替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
subn(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型
# repl : 要替换的字符串
# string : 要匹配的字符串
# count : 指定匹配个数
# flags : 匹配模式
复制代码
import re
a,b=re.subn("a\w","替换","sdfadfdfadsfsfafsff") #替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
print(a) #返回替换后的字符串
print(b) #返回替换次数
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
sdf替换fdf替换sfsf替换sff
3
7,groups

#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
8,
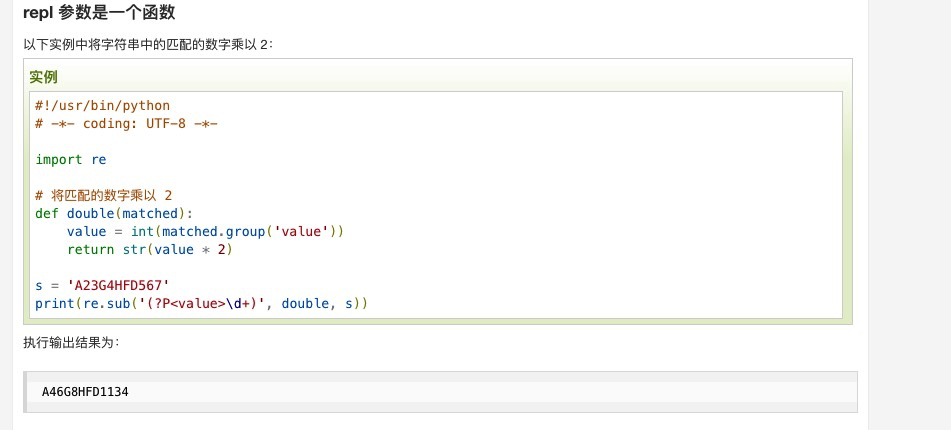
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
9,分组匹配
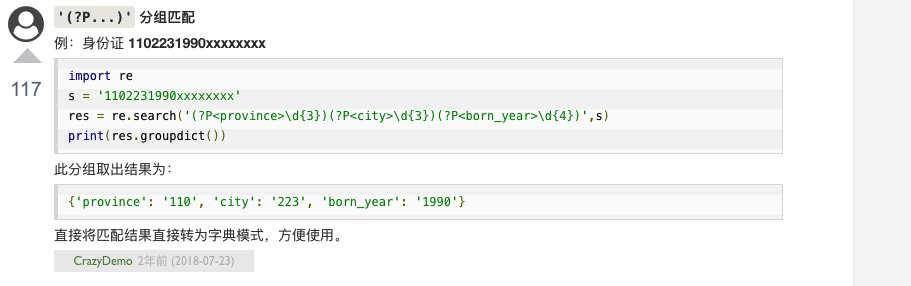
10,
(?P<pattern>)可以用来标记一些模糊的模式,然后在同一个正则表达式中,我们可以通过(?P=pattern)来复用之前的内容
通过上面的例子我们可以看出在组里面可以嵌套组,组的标记序号以左括号为准,从左到右依次增加。