性能常见的失败情况
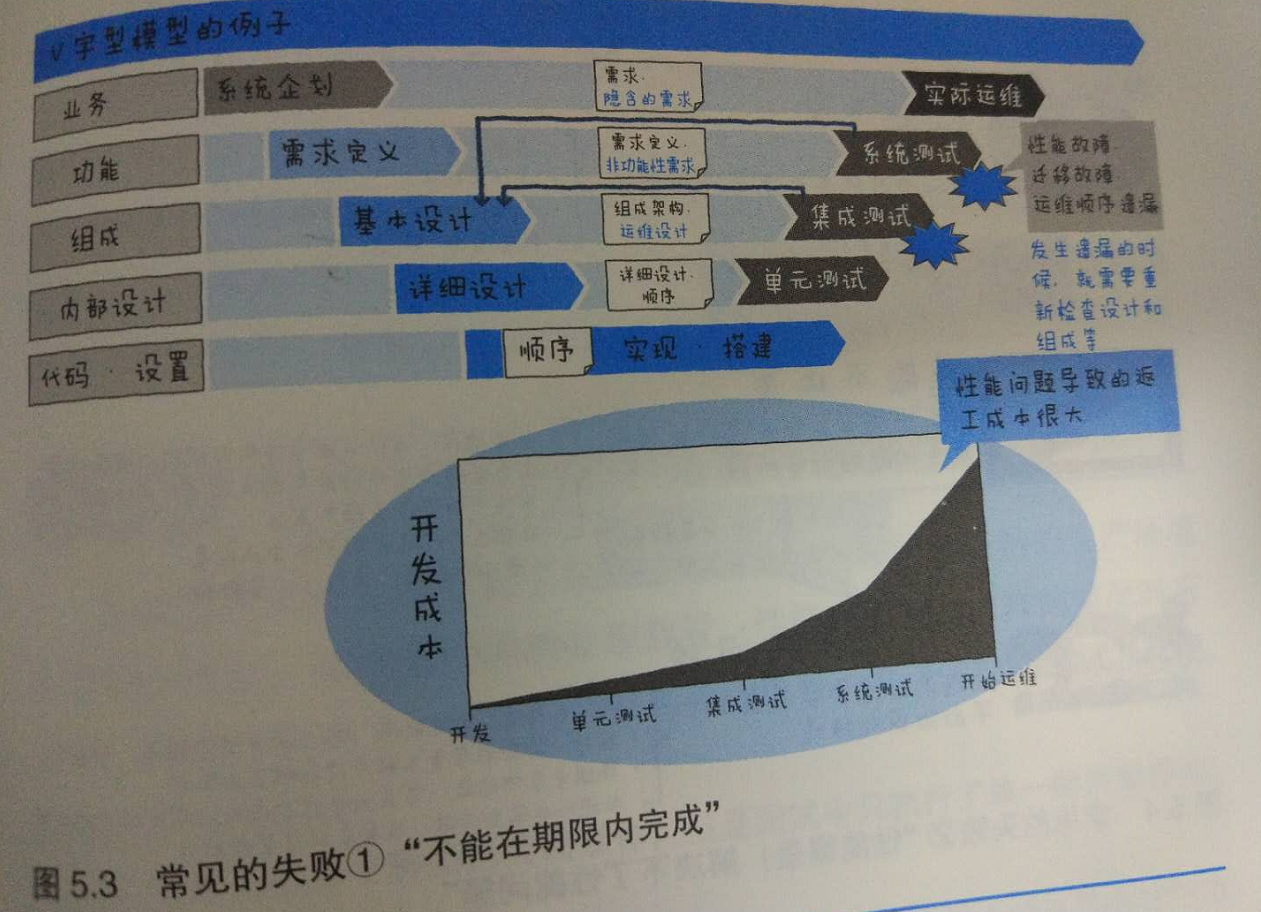
不能在期限内完成
在制作应用程序的过程中第一次执行性能测试时,这是种比较常见的模式,即使你期待着在系统测试阶段仪式性地做以下性能测试,然后就这样告一段落,也还是有可能发生诸多状况,比如执行完性能测试后性能完全达不到要求,或者发生了意外之外的性能方面的故障,于是被迫解析、调优、重新进行测试,甚至有些情况下需要重新设计等,致使原本已经临近的发布日期延迟。
像这样,之所以后期工程中隐藏这性能问题,原因有如下几点。
1)只有在生产环境中才会发现
2)问题的显现需要很多条件(环境、数据、负载生成)
3)因为特定的操作才导致发生性能问题
基于以上原因,我一般会告诉客户至少为系统测试中的性能测试留出1个月的时间。我认为,即使是认真地进行了准备、规划的项目,也需要这么久的时间。虽说在项目中收尾阶段很难保证这样长的时间来做性能测试,但如果不事先确保这么久的时间,非但不能完成完整的性能测试,更有可能因为没有达到预期的性能目标而被迫修改日程等,对自己的业务产生不良影响。
性能很差!解决不了性能问题
如果执行性能测试后发生了性能问题,那该怎么办呢?首先,调查导致性能变差的原因。虽说如此,但可以怀疑的地方却有很多。比如网络、负载均衡器、Web服务器、AP服务器、开发应用程序的方式、数据库、存储、与其他系统有数据关联的部分、数据大小、SQL等。
为了详细调查这些因素,需要各个模块的专业知识。此外,对横跨多个领域的性能问题进行排查的时候,如果不能综合多个领域来考虑,负责人就只会一直说“我负责的那部分没有问题”,导致问题无法解决。此外,即使汇集了有专业知识的员工及体制,若没有采用正确的验证和分析方法,非但会使效率变差,有时甚至会让调查朝着错误的方向进行,最终也就找不到答案了。于是,我们就会陷入这样一种状态:虽然知道性能很差,但却无法查明原因,问题始终得不到解决。
特别是最近几年Web系统中,模块的层级愈加复杂,问题越来越难排查,需要的专业知识范围越来越广,于是我们就越来越容易陷入这种状态。

由于没有考虑到环境差异而导致发生问题
有时进行了性能测试,也确认了系统性能能够满足生产环境的要求,结果顺利发布后,却发现在生产环境中并没有获得预期的性能。这种情况下可能就会追究责任,被追问性能测试的相关内容,比如“真的做了性能测试吗”“为什么出现了性能问题”等。特别是如果在生产环境中运行的时候发生问题,比如系统停止工作,或者是出现故障,那么就会对业务产生影响,有时甚至还会导致金钱上的损失,所以必须防止这种情况的发生。
至于为什么会出现此类问题,大家在调查原因时很容易忽视有一点,那就是测试环境与生产环境之间的差异。比如,硬件和使用的基础软件的类型的差异、磁盘延迟的差异、网络延迟的差异等。除了以上容易想到的形式上的差异之外,在生产环境中,由于内存量很大,因此有可能导致软件内存管理模块的开销也很大。另外,因为CPU核数很多,所以有可能导致多线程管理的开销也会变大。像这样,乍一看性能应该会提升,但实际上反而拖了后腿的情况也时有发生。
在无法准备和生产环境一样的性能测试环境的情况下,或者无法使用生产环境进行性能测试的情况下,当然就会有失败的风险。可能的话,在报价阶段就把准备好在生产环境一样的测试环境的费用也一起考虑进去,或者准备好在生产环境中运行后出现问题的情况下可以立即切换老系统的功能,也能让性能故障的损失降低到最小程度。
压力场景设计不完备导致发生问题
在性能测试时完全达到了期望中的性能,但在同样结构的生产环境中实际运行时,即使是同样的处理数量,性能也很差,这样的情况时有发生。在这种情况下,重要的是首先确认执行了怎样的性能测试。常见的有以下几种情况。
1)实际上有多种类的页面操作,但是测试中只执行了单一的页面操作,漏掉了更复杂的处理
2)测试时和实际运行时访问登陆,查找页面等负载较大的页面的比例有差异
3)用户的停留时间超过测试时的预估,在多个页面之间迁移,这些迁移信息积累在会话中,导致使用的内存也超出预估
没有考虑到缓冲、缓存的使用而导致发生问题
性能测试时性能很好,但是在生产环境中性能却很差,这种情况下就需要注意系统的缓冲和缓存的使用状态。
如果多次访问同一个页面,那么与该页面相关的缓存就会保存在LB、Web服务器、AP服务器的缓存或数据缓存,或者DB的缓冲缓存等中,响应速度就会变快。速度变快就证明可以按照预期的那样使用功能,性能也就没有问题。但无论如何,测试时与实际运行时的缓存使用量都会出现差别。
以下是几种比较常见的情况。
1)测试时只访问了同种类型的页面
2)只使用了同一用户ID来访问
3)只访问了相同的查找对象(商品名称等)
4)查找时只使用了相同的过滤条件
以上这些情况下,在性能测试的时候,利用缓存能够最快地返回响应,所以性能很好,也能以很低的资源负载来完成处理。但是,真正在实际生产环境中运行的时候,就会出现各种各样的处理和访问,缓存使用率就不像测试时那样高,也就变成了慢响应和高负载的模式。
为了防止出现这种情况,就需要在测试的时候预估好实际运行时的缓存命中率,并动态变更请求等。
没有考虑到思考时间而导致发生问题
在性能测试时获得了很好的结果,但在生产环境中,即使施加了同样的处理负载,却还是达到了系统的性能极限,这种情况下我们想到的另外一个原因就是压力测试场景的“思考时间”。这一点很容易被忽视,但却是常见。
思考时间指的是使用系统的用户的思考时间的预估值,用户会连续进行很多个处理,比如,打开页面后,进行登录-》选择菜单-》输入搜索关键字-》从列表中选择条目-》填写表单等操作,各个步骤之间的跳转并不是一瞬间完成的,用户在阅读或者填写时都会花费一定时间。预想到实际的使用状态,正确的预算好时间来设计压力场景,或者只是单纯地使用测试工具在前一个处理完成后立即发出下一个请求,这两种做法对系统的负载是有差异的。
对于服务器来说,即使在相同的吞吐(访问处理数/秒)状态下,也会由于思考时间的有无所造成的差异,导致HTTP并发连接数以及应用程序的会话保持数产生很大的不同。每秒访问处理数相同但思考时间不一样的情况下,思考时间越长,在系统上同时滞留的用户数和会话数也会越多。这就导致系统的内存和会话管理的压力出现差异。因此,在考虑压力场景时,如果没有把真实用户的思考时间纳入考量,那么这个性能测试就脱离了生产环境。
报告内容难以理解导致客户不能认同
向客户报告性能测试结构与普通测试结果的情况是不一样的。普通测试的情况下,只要能按照事先设计的那样来运行,就是合格。也就是说,如果使用OX来判断,那么只要全部项目都是O,就能得到客户的认同。
性能测试则不是通过OX来判断,而是通过数字来评价的。如果只是简单地拿一个数字作为指标,达到这个指标就算合格,那么向客户报告说“响应时间在3秒以内”“达到了每秒处理1000条的要求”等,有时也可以获得客户的认可。但实际上并没有这么简单,例如:
“每秒处理条数是1000条的时候,响应时间是2.5秒,CPU使用率是60%,但是当每秒处理条数是1200条的时候,响应时间变为了4秒,CPU使用率是80%。不过,场景的思考时间从平均5秒减少为3秒的时间,负载就下降了30%。另外,在登陆比例比较高的场景中,每100次登陆会有2次出错”
如果像这样认真地报告结果,客户反而会表示“完全听不懂”。
实际上,客户关心的焦点集中在“实际生产环境中运行时是否会出现性能方面的问题”。因此在报告性能测试结果报告时,有时不得不使用“在OO范围内的话没有问题,超过这个范围的话就会达到性能极限”这样的表述。对此,客户可能误解,觉得没有简明扼要地做出说明,甚至有些客户也可能完全不接受这种说明。
__EOF__

本文链接:https://www.cnblogs.com/jiaoyang77/p/9219347.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗