
Python 菜鸟笔记
记录笔者日常学习笔记,无深解内容,除了笔者无人看懂。python官网
python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1
从右到左索引默认-1开始的,最大范围是字符串开头
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
比如:
>>> s = 'abcdef'
>>> s[1:5]
'bcde'
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。
加号(+)是字符串连接运算符,星号(*)是重复操作。如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = 'Hello World!'
print str # 输出完整字符串
print str[0] # 输出字符串中的第一个字符
print str[2:5] # 输出字符串中第三个至第六个之间的字符串
print str[2:] # 输出从第三个字符开始的字符串
print str * 2 # 输出字符串两次
print str + "TEST" # 输出连接的字符串
print("%s*%s=%s"%(m,n,m*n),end= "\t") #第二个end参数可以设置是否换行,默认是换行,\t是不换行
print(f'%s*%s={i*j}'%(i,j)) #格式化字符串,{}里面是变量
print(r"hello\nchengdu") #不转义\n,直接将转义符按字符串输出
List(列表) 是 Python 中使用最频繁的数据类型。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
list = [ 'runoob', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
print list # 输出完整列表
print list[0] # 输出列表的第一个元素
print list[1:3] # 输出第二个至第三个元素
print list[2:] # 输出从第三个开始至列表末尾的所有元素
print tinylist * 2 # 输出列表两次
print list + tinylist # 打印组合的列表
元组是另一个数据类型,类似于 List(列表)。
元组是不允许更新的,而列表是允许更新的。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 )
tinytuple = (123, 'john')
print tuple # 输出完整元组
print tuple[0] # 输出元组的第一个元素
print tuple[1:3] # 输出第二个至第四个(不包含)的元素
print tuple[2:] # 输出从第三个开始至列表末尾的所有元素
print tinytuple * 2 # 输出元组两次
print tuple + tinytuple # 打印组合的元组
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'runoob','code':6734, 'dept': 'sales'}
print dict['one'] # 输出键为'one' 的值
print dict[2] # 输出键为 2 的值
print tinydict # 输出完整的字典
print tinydict.keys() # 输出所有键
print tinydict.values() # 输出所有值
Python数据类型转换
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
Python算术运算符
以下假设变量: a=10,b=20:
运算符|描述|实例
-|-|
+|加 - 两个对象相加|a + b 输出结果 30
-|减 - 得到负数或是一个数减去另一个数|a - b 输出结果 -10
*|乘 - 两个数相乘或是返回一个被重复若干次的字符串|a * b 输出结果 200
/|除 - x除以y|b / a 输出结果 2
%|取模 - 返回除法的余数|b % a 输出结果 0
|幂 - 返回x的y次幂|ab 为10的20次方, 输出结果 100000000000000000000
//|取整除 - 返回商的整数部分(向下取整)| >>> 9//2 4 >>> -9//2 -5
Python逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
以下实例演示了Python所有成员运算符的操作:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print "1 - 变量 a 在给定的列表中 list 中"
else:
print "1 - 变量 a 不在给定的列表中 list 中"
if ( b not in list ):
print "2 - 变量 b 不在给定的列表中 list 中"
else:
print "2 - 变量 b 在给定的列表中 list 中"
# 修改变量 a 的值
a = 2
if ( a in list ):
print "3 - 变量 a 在给定的列表中 list 中"
else:
print "3 - 变量 a 不在给定的列表中 list 中"
Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
以下实例演示了Python所有身份运算符的操作:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 20
b = 20
if ( a is b ):
print "1 - a 和 b 有相同的标识"
else:
print "1 - a 和 b 没有相同的标识"
if ( a is not b ):
print "2 - a 和 b 没有相同的标识"
else:
print "2 - a 和 b 有相同的标识"
# 修改变量 b 的值
b = 30
if ( a is b ):
print "3 - a 和 b 有相同的标识"
else:
print "3 - a 和 b 没有相同的标识"
if ( a is not b ):
print "4 - a 和 b 没有相同的标识"
else:
print "4 - a 和 b 有相同的标识"
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True
Python 支持四种不同的数值类型:
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。
- 长整型(long integers) - 无限大小的整数,整数最后是一个大写或小写的L。
- 浮点型(floating point real values) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- 复数(complex numbers) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3+e18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7j |
- 长整型也可以使用小写"L",但是还是建议您使用大写"L",避免与数字"1"混淆。Python使用"L"来显示长整型。
- Python还支持复数,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
Python Number 类型转换
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串
Python math 模块、cmath 模块
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。
Python math 模块提供了许多对浮点数的数学运算函数。
Python cmath 模块包含了一些用于复数运算的函数。
cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。
要使用 math 或 cmath 函数必须先导入:
import math
查看 math 查看包中的内容:
>>> import math
>>> dir(math)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
Python数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根 |
Python随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
Python三角函数
Python包括以下三角函数:
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
Python数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| |反斜杠符号 | |
| ' | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
Python字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b |
| * | 重复输出字符串 | >>>a * 2 |
| [] | 通过索引获取字符串中字符 | >>>a[1] |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in a |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in a |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n'``>>> print R'\n' |
Python 字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符%s的字符串中。
python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 |
|在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X')
0|显示的数字前面填充'0'而不是默认的空格
%|'%%'输出一个单一的'%'
(var)|映射变量(字典参数)
m.n.|m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话)
python的字符串内建函数
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
| string.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
| string.splitlines([keepends]) | 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
Python列表截取
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取列表中第三个元素 |
| L[-2] | 'baidu' | 读取列表中倒数第二个元素 |
| L[1:] | ['baidu', 'Taobao'] | 从第二个元素开始截取列表 |
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2)比较两个列表的元素 |
| 2 | len(list)列表元素个数 |
| 3 | max(list)返回列表元素最大值 |
| 4 | min(list)返回列表元素最小值 |
| 5 | list(seq)将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj)在列表末尾添加新的对象 |
| 2 | list.count(obj)统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq)在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj)从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj)将对象插入列表 |
| 6 | list.pop([index=-1])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj)移除列表中某个值的第一个匹配项 |
| 8 | list.reverse()反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False)对原列表进行排序 |
Python 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
如下实例:
实例(Python 2.0+)
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
创建空元组
tup1 = ()
元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,)
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
L = ('spam', 'Spam', 'SPAM!')
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | 读取第三个元素 |
| L[-2] | 'Spam' | 反向读取,读取倒数第二个元素 |
| L[1:] | ('Spam', 'SPAM!') | 截取元素 |
元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2)比较两个元组元素。 |
| 2 | len(tuple)计算元组元素个数。 |
| 3 | max(tuple)返回元组中元素最大值。 |
| 4 | min(tuple)返回元组中元素最小值。 |
| 5 | tuple(seq)将列表转换为元组。 |
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2)比较两个字典元素。 |
| 2 | len(dict)计算字典元素个数,即键的总数。 |
| 3 | str(dict)输出字典可打印的字符串表示。 |
| 4 | type(variable)返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear()删除字典内所有元素 |
| 2 | dict.copy()返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val])创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None)返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key)如果键在字典dict里返回true,否则返回false |
| 6 | dict.items()以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys()以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None)和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2)把字典dict2的键/值对更新到dict里 |
| 10 | dict.values()以列表返回字典中的所有值 |
| 11 | pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem()返回并删除字典中的最后一对键和值。 |
Python 日期和时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳, 如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time # 引入time模块
ticks = time.time()
print "当前时间戳为:", ticks
Python 函数
定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
参数传递
在 python 中,类型属于对象,变量是没有类型的:
a=[1,2,3]
a="Runoob"
以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象。
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用printme()函数,你必须传入一个参数,不然会出现语法错误:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print str
return
#调用printme函数
printme()
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 printme() 调用时使用参数名:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print str
return
#调用printme函数
printme( str = "My string")
默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print "Name: ", name
print "Age ", age
return
#调用printinfo函数
printinfo( age=50, name="miki" )
printinfo( name="miki" )
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。不定长参数实例如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )
变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
- 全局变量
- 局部变量
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total
#调用sum函数
sum( 10, 20 )
print "函数外是全局变量 : ", total
import 语句
模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块 fib 的 fibonacci 函数,使用如下语句:
from fib import fibonacci
这个声明不会把整个 fib 模块导入到当前的命名空间中,它只会将 fib 里的 fibonacci 单个引入到执行这个声明的模块的全局符号表。
搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
PYTHONPATH 变量
作为环境变量,PYTHONPATH 由装在一个列表里的许多目录组成。PYTHONPATH 的语法和 shell 变量 PATH 的一样。
在 Windows 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=c:\python27\lib;
在 UNIX 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=/usr/local/lib/python
命名空间和作用域
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
例如,我们在全局命名空间里定义一个变量 Money。我们再在函数内给变量 Money 赋值,然后 Python 会假定 Money 是一个局部变量。然而,我们并没有在访问前声明一个局部变量 Money,结果就是会出现一个 UnboundLocalError 的错误。取消 global 语句前的注释符就能解决这个问题。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
Money = 2000
def AddMoney():
# 想改正代码就取消以下注释:
# global Money
Money = Money + 1
print Money
AddMoney()
print Money
dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入内置math模块
import math
content = dir(math)
print content;
以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']
在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
globals() 和 locals() 函数
根据调用地方的不同,globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用 locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用 globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用 keys() 函数摘取。
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。init.py 用于标识当前文件夹是一个包。
考虑一个在 package_runoob 目录下的 runoob1.py、runoob2.py、init.py 文件,test.py 为测试调用包的代码,目录结构如下:
test.py
package_runoob
|-- __init__.py
|-- runoob1.py
|-- runoob2.py
package_runoob/runoob1.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
def runoob1():
print "I'm in runoob1"
package_runoob/runoob2.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
def runoob2():
print "I'm in runoob2"
现在,在 package_runoob 目录下创建 init.py:
package_runoob/init.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
if __name__ == '__main__':
print '作为主程序运行'
else:
print 'package_runoob 初始化'
然后我们在 package_runoob 同级目录下创建 test.py 来调用 package_runoob 包
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入 Phone 包
from package_runoob.runoob1 import runoob1
from package_runoob.runoob2 import runoob2
runoob1()
runoob2()
Python 文件I/O
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
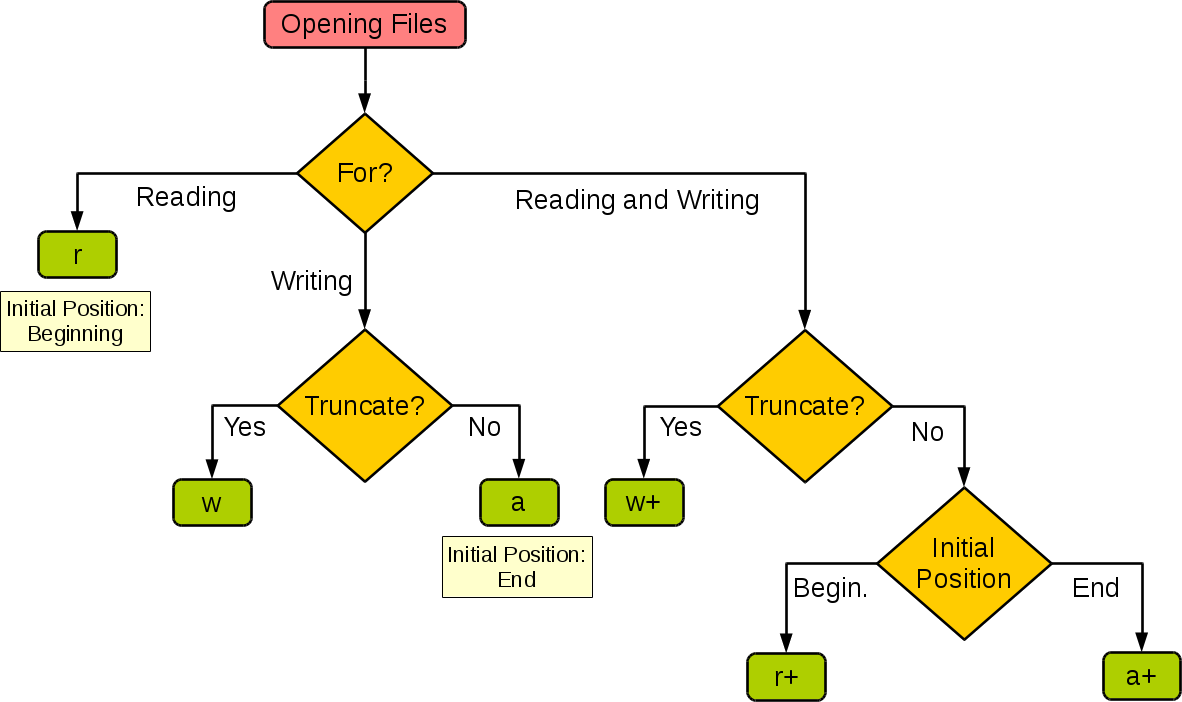
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name
print "是否已关闭 : ", fo.closed
print "访问模式 : ", fo.mode
print "末尾是否强制加空格 : ", fo.softspace
close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name
# 关闭打开的文件
fo.close()
读写文件:
file对象提供了一系列方法,能让我们的文件访问更轻松。来看看如何使用read()和write()方法来读取和写入文件。
write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
语法:
fileObject.write(string)
在这里,被传递的参数是要写入到已打开文件的内容。
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
fo.write( "www.baidu.com!\nVery good site!\n")
# 关闭打开的文件
fo.close()
上述方法会创建foo.txt文件,并将收到的内容写入该文件,并最终关闭文件。如果你打开这个文件,将看到以下内容:
$ cat foo.txt
www.baidu.com!
Very good site!
read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
例子:
这里我们用到以上创建的 foo.txt 文件。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.baidu.
文件位置:
文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print ("读取的字符串是 : ", str)
# 查找当前位置
position = fo.tell()
print ("当前文件位置 : ", position)
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print ("重新读取字符串 : ", str)
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.baidu.
当前文件位置 : 10
重新读取字符串 : www.baidu.
重命名和删除文件
Python的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
rename()方法:
rename()方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
例子:
下例将重命名一个已经存在的文件test1.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )
remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
例子:
下例将删除一个已经存在的文件test2.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")
Python里的目录:
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 创建目录test
os.mkdir("test")
chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir("newdir")
例子:
下例将进入"/home/newdir"目录。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")
getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
例子:
下例给出当前目录:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 给出当前的目录
print os.getcwd()
rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')
例子:
以下是删除" /tmp/test"目录的例子。目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 删除”/tmp/test”目录
os.rmdir( "/tmp/test" )
文件、目录相关的方法
File 对象和 OS 对象提供了很多文件与目录的操作方法:
Python File(文件) 方法
Python OS 模块 文件/目录方法
Python 异常处理
Python 内置函数
函数解析
Python 操作 MySQL 数据库
Python 网络编程
Python SMTP发送邮件
Python 多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
Python GUI编程(Tkinter)
Python 提供了多个图形开发界面的库,几个常用 Python GUI 库如下:
- Tkinter: Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里。Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中。
- wxPython:wxPython 是一款开源软件,是 Python 语言的一套优秀的 GUI 图形库,允许 Python 程序员很方便的创建完整的、功能健全的 GUI 用户界面。
- Jython:Jython 程序可以和 Java 无缝集成。除了一些标准模块,Jython 使用 Java 的模块。Jython 几乎拥有标准的Python 中不依赖于 C 语言的全部模块。比如,Jython 的用户界面将使用 Swing,AWT或者 SWT。Jython 可以被动态或静态地编译成 Java 字节码。
Tkinter 编程
Tkinter 是 Python 的标准 GUI 库。Python 使用 Tkinter 可以快速的创建 GUI 应用程序。
由于 Tkinter 是内置到 python 的安装包中、只要安装好 Python 之后就能 import Tkinter 库、而且 IDLE 也是用 Tkinter 编写而成、对于简单的图形界面 Tkinter 还是能应付自如。
注意:Python3.x 版本使用的库名为 tkinter,即首写字母 T 为小写。
import tkinter
创建一个GUI程序
1、导入 Tkinter 模块
2、创建控件
3、指定这个控件的 master, 即这个控件属于哪一个
4、告诉 GM(geometry manager) 有一个控件产生了。
#!/usr/bin/python3
import tkinter
top = tkinter.Tk()
# 进入消息循环
top.mainloop()
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# Python2.x 导入方法
from Tkinter import * # 导入 Tkinter 库
# Python3.x 导入方法
#from tkinter import *
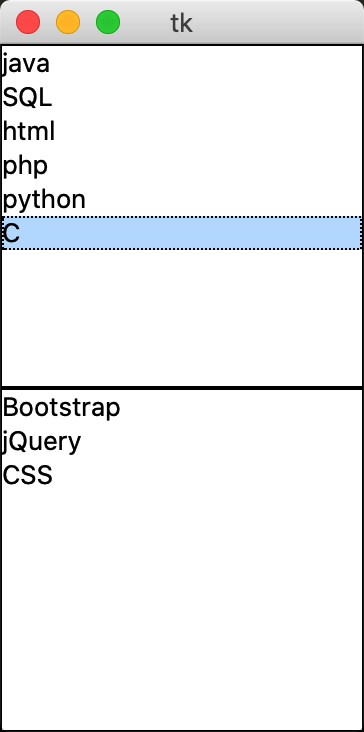
root = Tk() # 创建窗口对象的背景色
# 创建两个列表
li = ['C','python','php','html','SQL','java']
movie = ['CSS','jQuery','Bootstrap']
listb = Listbox(root) # 创建两个列表组件
listb2 = Listbox(root)
for item in li: # 第一个小部件插入数据
listb.insert(0,item)
for item in movie: # 第二个小部件插入数据
listb2.insert(0,item)
listb.pack() # 将小部件放置到主窗口中
listb2.pack()
root.mainloop() # 进入消息循环
Tkinter 组件
Tkinter的提供各种控件,如按钮,标签和文本框,一个GUI应用程序中使用。这些控件通常被称为控件或者部件。
目前有15种Tkinter的部件。我们提出这些部件以及一个简短的介绍,在下面的表:
| 控件 | 描述 |
|---|---|
| Button | 按钮控件;在程序中显示按钮。 |
| Canvas | 画布控件;显示图形元素如线条或文本 |
| Checkbutton | 多选框控件;用于在程序中提供多项选择框 |
| Entry | 输入控件;用于显示简单的文本内容 |
| Frame | 框架控件;在屏幕上显示一个矩形区域,多用来作为容器 |
| Label | 标签控件;可以显示文本和位图 |
| Listbox | 列表框控件;在Listbox窗口小部件是用来显示一个字符串列表给用户 |
| Menubutton | 菜单按钮控件,用于显示菜单项。 |
| Menu | 菜单控件;显示菜单栏,下拉菜单和弹出菜单 |
| Message | 消息控件;用来显示多行文本,与label比较类似 |
| Radiobutton | 单选按钮控件;显示一个单选的按钮状态 |
| Scale | 范围控件;显示一个数值刻度,为输出限定范围的数字区间 |
| Scrollbar | 滚动条控件,当内容超过可视化区域时使用,如列表框。. |
| Text | 文本控件;用于显示多行文本 |
| Toplevel | 容器控件;用来提供一个单独的对话框,和Frame比较类似 |
| Spinbox | 输入控件;与Entry类似,但是可以指定输入范围值 |
| PanedWindow | PanedWindow是一个窗口布局管理的插件,可以包含一个或者多个子控件。 |
| LabelFrame | labelframe 是一个简单的容器控件。常用与复杂的窗口布局。 |
| tkMessageBox | 用于显示你应用程序的消息框。 |
标准属性
标准属性也就是所有控件的共同属性,如大小,字体和颜色等等。
| 属性 | 描述 |
|---|---|
| Dimension | 控件大小; |
| Color | 控件颜色; |
| Font | 控件字体; |
| Anchor | 锚点; |
| Relief | 控件样式; |
| Bitmap | 位图; |
| Cursor | 光标; |
几何管理
Tkinter控件有特定的几何状态管理方法,管理整个控件区域组织,以下是Tkinter公开的几何管理类:包、网格、位置
| 几何方法 | 描述 |
|---|---|
| pack() | 包装; |
| grid() | 网格; |
| place() | 位置; |
Python JSON
JSON 函数
使用 JSON 函数需要导入 json 库:import json。
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
json.dumps
json.dumps 用于将 Python 对象编码成 JSON 字符串。
语法
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
实例
以下实例将数组编码为 JSON 格式数据:
#!/usr/bin/python
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = json.dumps(data)
print json
以上代码执行结果为:
[{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]
使用参数让 JSON 数据格式化输出:
>>> import json
>>> print json.dumps({'a': 'Runoob', 'b': 7}, sort_keys=True, indent=4, separators=(',', ': '))
{
"a": "Runoob",
"b": 7
}
python 原始类型向 json 类型的转化对照表:
| Pythond | JSON |
|---|---|
| dictd | object |
| list, tupled | array |
| str, unicoded | string |
| int, long, floatd | number |
| Trued | true |
| Falsed | false |
| Noned | null |
json.loads
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
实例
以下实例展示了Python 如何解码 JSON 对象:
#!/usr/bin/python
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print text
以上代码执行结果为:
{u'a': 1, u'c': 3, u'b': 2, u'e': 5, u'd': 4}
json 类型转换到 python 的类型对照表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number (int) | int, long |
| number (real) | float |
| true | True |
| false | False |
| null | None |






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具