SQL去重
记得很多年前,有个测试妹子找到我:
强哥,我这个表数据重复了,怎么把重复的数据删掉呀?
类似的需要将数据去重的场景,在实际工作中还是比较常见的。
今天我们就来说说,使用SQL语句来去重,有哪些常见的方法。
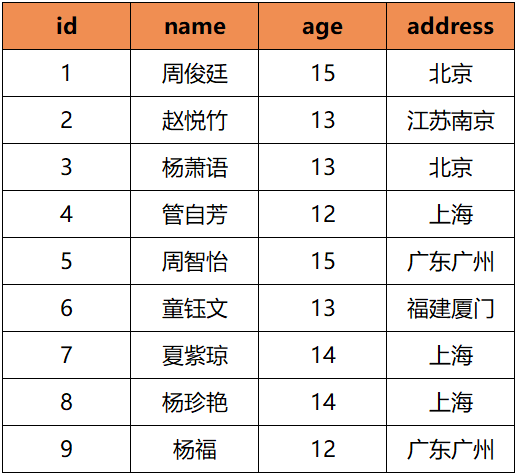
假如我们有一张student表:
create table student(id int,name varchar(50),age int,address varchar(100));
表中的数据如下:
方法一:使用DISTINCT关键字进行去重。
DISTINCT关键字,在使用时,后面会跟上去重的字段。可以保证这些去重字段的数据不重复。
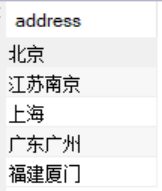
比如,取出student表中,不重复的address有哪些,可以使用如下SQL语句:
select distinct addressfrom student;
返回结果如下:
这种方法,最大的优点是使用起来比较简单。
但也有一个比较大的缺点,就是去重的字段与最终返回的结果集中的字段,是一致的。也就是说,在上面的SQL语句中,使用address字段进行去重,最终的结果,也只返回address一个字段。
如果想以address字段去重,并且同时返回其他字段,DISTINCT是做不到的。
方法二:使用GROUP BY关键字进行去重
与DISTINCT关键字一样,GROUP BY关键字,也是标准SQL支持的常用的去重方法。它可以在去重的同时,同步返回其他字段的信息。
还是以对address字段进行去重为例,其他字段可以使用聚合函数根据需要进行获取:
select min(id),max(name),max(age),addressfrom studentgroup by address;
返回结果如下:
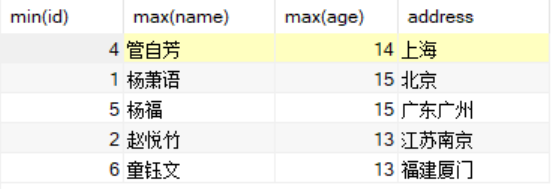
在上面的语句中,不仅对address字段进行了去重,也同时返回了id、name、age字段的信息。
在这一点上,比DISTINCT要好用很多。
不过,仔细一看,好像总是觉得哪里不对劲。
id=1的学生,应该叫周俊廷,而在上面的返回结果中却是杨萧语,返回的age字段,也有同样的问题。
也就是说,在返回的结果中,同一行的id、name、age,可能并不是同一个学生的,这就导致看起来数据有些混乱。
如果对数据的一致性有要求,可以使用下面的第三种方法。
方法三:使用窗口函数进行去重。
窗口函数有好几种,使用起来大同小异,这里只介绍ROW_NUMBER() over(partition by ... order by ...)。
selectid,name,age,addressfrom (select id,name,age,address,row_number() over(partition by addressorder by id asc) as rnfrom student)awhere a.rn = 1;
ROW_NUMBER()窗口函数的含义是,先对数据按照partition by的字段进行分组,然后以order by的字段进行排序,序号从1开始递增。
上面的SQL返回的结果为:
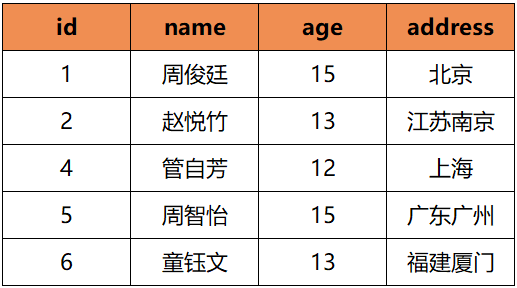
这个返回结果,就完美多了。
但是,需要注意的是,有些数据库是不支持窗口函数的。像MySQL数据库中就无法使用。
方法四:使用IN去重
这种方法的关键在于,找到一组不重复的数据的特征,然后以这个特征来取数据。
比如:按address来去重,如果数据有重复,取id最大的那条。
select *from studentwhere id in (select max(id)from studentgroup by address);
SQL返回结果如下:
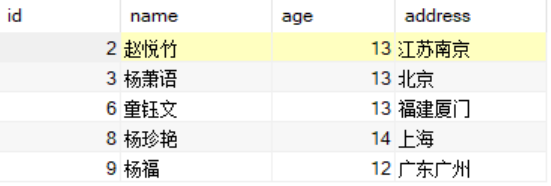
当然,也可以取id最小的那条,将上面语句中的max改成min就可以了。
这种方法适合表里有一个数据不重复的字段(上面SQL中的id字段)的情况。
如果表中不存在这样一个字段,这种方法就不再适用了。但有些数据库,天生自带了类似的字段可以使用。
比如,在ORACLE数据库中,可以使用ROWID替代上面SQL中的id字段。当然仅限于ORACLE数据库:
select *from studentwhere rowid in (select max(rowid)from studentgroup by address);
方法五:使用NOT EXISTS去重
与方法四的思路类似,使用NOT EXISTS也可以实现同样的效果。
select *from student awhere not exists(select 1from student bwhere a.address = b.addressand a.id > b.id);
SQL返回结果如下:
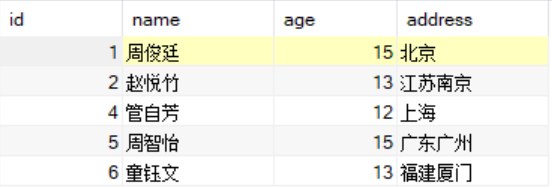
方法六:使用ALL关键字
在MySQL数据库中,有一个特殊的操作符ALL,这是一个集合操作符。
select *from student awhere a.id <= ALL(select b.idfrom student bwhere a.address = b.address);
SQL返回结果如下:
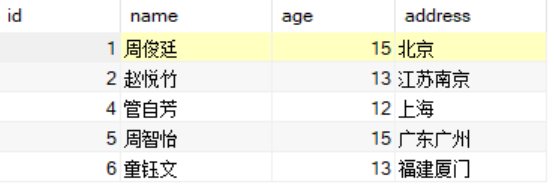
在上面的SQL中,ALL操作符的意思是说,a.id字段要<=ALL操作符括号里查询出来的所有值。
所以,这种方法的核心思路与方法四是类似的。
方法七:使用INNER JOIN + GROUP BY关键字
这种方法的核心思路,也与方法四是类似的。
selecta.*from student ainner join student bon a.address = b.addressand a.id >= b.idgroup by a.id,a.name,a.age,a.addresshaving count(*)=1;
SQL返回结果如下:
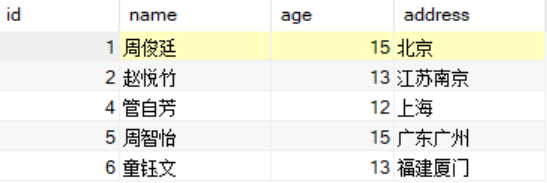
熟练使用上面7种数据去重的方法,基本上可以解决所有的数据去重问题了。
我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。
时间仓促,如有错误欢迎指出,欢迎在评论区讨论,如对您有帮助还请点个推荐、关注支持一下
作者:博客园 - 角刀牛
出处:https://www.cnblogs.com/jiaodaoniujava/
该文章来源互联网,本博仅以学习为目的,版权归原作者所有。
若内容有侵犯您权益的地方,请公告栏处联系本人,本人定积极配合处理解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号