
Redis实现分布式缓存
单机的Redis存在四大问题:
数据丢失、并发能力弱、故障恢复问题、存储能力
1、Redis持久化(解决数据丢失问题)
有两种持久化方案:RDB/AOF
★RDB(数据备份文件):把内存中的数据记录到磁盘中,当redis实例发生故障重启时,从磁盘中读取快照文件,恢复数据,快照文件就是RDB文件,该文件默认保存在redis运行的目录下
RDB持久化在四种情况下会执行:
●执行save命令 /同步
save命令会让主进程执行RDB,这进行数据备份时其他命令会被阻塞
●执行bgsave命令 /异步
bgsave命令,主进程会fork一个子进程,foke子进程时对于其他命令是阻塞状态,fork子进程完毕时,阻塞解除,由子进程来完成数据备份的操作
●Redis停机时
停机时会执行一次save命令,来实现数据备份
●触发我们自定义的RDB条件时
在redis.conf文件中配置,save 300 1 #300秒内有一个key被修改就执行bgsave操作
缺点:RDB执行时间间隔长,两次RDB之间会有数据丢失的风险
fork子进程、压缩、写出RDB文件都比较耗时
★AOF持久化
AOF(追加文件):redis处理的每一个写命令都会记录在AOF文件中,可以看做是命令日志文件
AOF默认是关闭的,要在redis.conf文件中配置来开启AOF
appendonly yes #是否开启AOF功能
appendfilename "appendonly.aof" #AOF文件名
AOF命令记录的频率可通过redis.conf来进行配置
appendfsync always #每执行一次写命令,立即记录到AOF文件中
appendfaync everysec #写命令执行完后先放入AOF缓冲区,然后每隔一秒将缓冲区的数据写入到AOF文件中,这是默认方案
appendfsync no #写命令执行完放入缓冲区,由操作系统来决定何时将缓冲区内容写到磁盘
Redis也会在触发阈值时自动去重写AOF文件(在redis.conf中配置)
auto-aof-rewrite-percentage 100 #AOF文件比上次文件 增长超过多少百分比时触发重写
auto-aof-rewrite-min-size 64 #AOF文件体积最小多大以上时才触发重写
两种持久化使用场景:
RDB:可以接受分钟内的数据丢失,追求更快的启动速度
AOF:对数据安全性要求较高
2、Redis主从复制
单接点的redis并发能力是有上限的,要提高redis的并发能力,需要搭建主从集群,实现读写分离
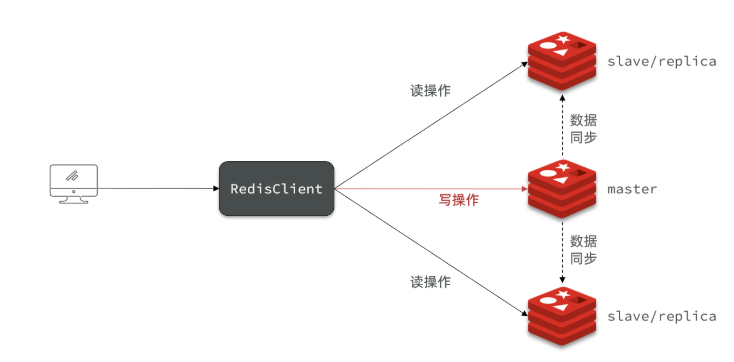
● 全量同步(RDB)
主从第一次建立连接时,会执行全量同步,将master节点上所有数据拷贝到slave节点上
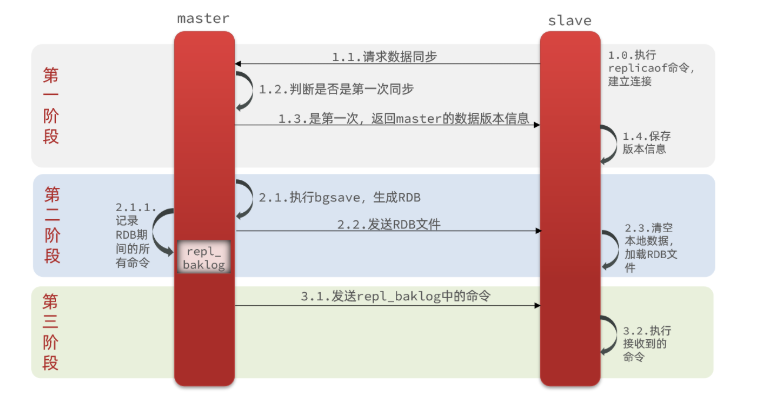
问题:redis的master是如何得知是和salve进行第一次连接的呢?
通过replid,此id用来保证master和slave的数据是否是同一批数据,每个master都有唯一的replid,它的从节点slave会继承它的replid
offset:偏移量,slave在完成数据同步时会记录当前同步的offset(偏移量),如果slave的偏移量小于master的offset,说明slave的数据落后于master,需要更新
因此,slave在进行数据同步时,需要向master声明自己的replid和offset,master才知道要同步哪些数据给slave
因为slave原本也是一个master,有自己的id和offset,当master变成slave时,会将自己的id和offset提交给master,master发现两个id不一致,就知道是第一次连接,就会进行全量同步
● 增量同步
只更新slave节点相对于master节点上没有的数据
在RDB进行数据同步时,同步的数据会保存到一个log文件中,这个log文件是一个环形的数组,首先数据从0开始保存在master中(一个弧长),然后slave也从0开始追随master的脚步,可以看做是一直覆盖master的数据来完成数据同步,当slave出现网络故障停止数据同步而master一直在保存新的数据时,它会覆盖掉slave的部分(这个不影响),但当master覆盖掉slave的部分之后,它会继续覆盖master的,相当于他已经走第二圈了,这时slave网络恢复在进行数据同步时,就只能全量同步了,增量同步会丢失数据
● 主从同步的优化
提高环形log文件的大小,发现slave宕机尽快恢复故障,避免master的偏移量覆盖掉slave的偏移量导致全量同步
限制master上的slave节点数量,如果slave节点过多,可以通过主-从-从链式结构减少master的压力
3、Redis哨兵(Sentinel)
redis提供了哨兵机制用来实现主从集群的自动故障恢复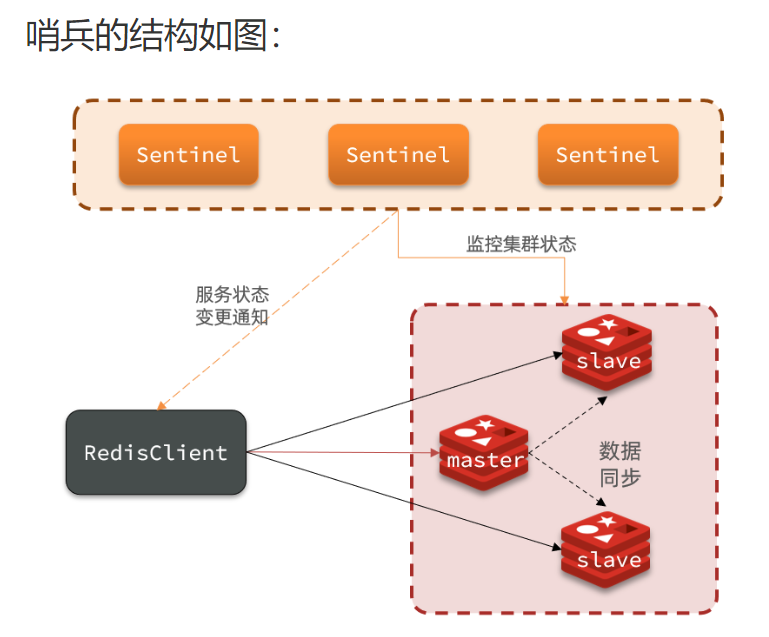
Sentinel会检测master和slave是否正常,如果master出现故障,会将一个正常的slave提升为master,当故障的master恢复后变为slave,以新的master为主
当redis发送故障,master进行更换时,会将最新的信息推送给redis客户端
哨兵基于心跳检测机制,每隔一秒向集群中的所有节点发送ping命令,每个节点向哨兵回应pong,当一个哨兵发现有一个节点没有回应时,认为该节点为主观下线,当哨兵集群中有一半以上的哨兵都没有收到该节点没响应时,此时该节点为客观下线
4、Redis分片集群
解决海量数据存储,高并发写的问题
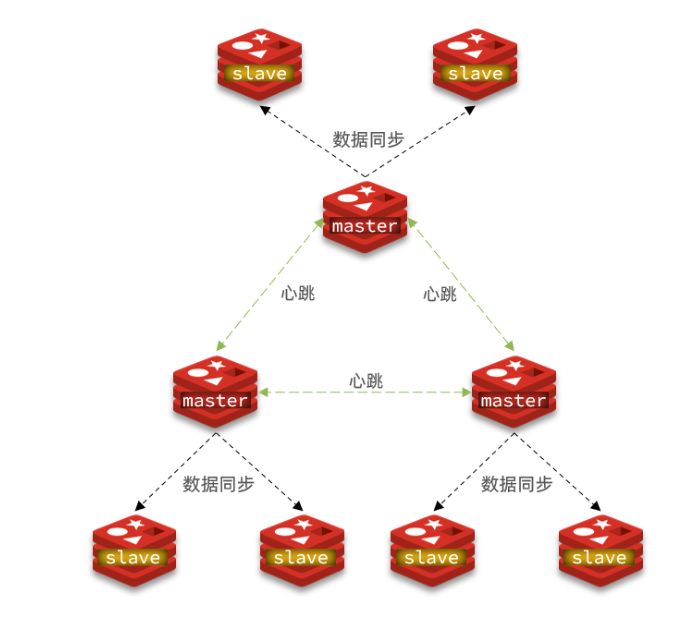
集群中有多个master节点,每个master保存不同的数据
多个master之间通过ping命令来互相检测彼此的健康状态
客户端请求访问任意集群节点,最终会被转发到正确的节点
散列插槽(0-16383)
redis会把每个master节点映射到插槽上,数据key与插槽进行绑定,redis根据key的有效部分计算出插槽值,来确定该key存储在哪个插槽上
计算插槽值:
如果key中包含{},且{}里面有字符,就根据{}里面的字符计算插槽值
如果key中没有{},用整个key来计算插槽值
计算方式:利用CRC16算法得到一个hash值,然后对16384取余,就可以得到该key对应的插槽值
插槽的好处:
1、移除或者新增节点的时候比较方便,因为数据是和插槽进行绑定的,所以只需要移动插槽就可以了
2、当需要增加节点时,只需要把其他节点上的哈希槽分一部分出来给新的节点
3、当需要删除节点时,只需要把要删除的节点上的哈希槽转移到其他节点上就可以了
4、而且,我们在做新增或者移除节点时,不需要停掉redis服务
Redis的集群伸缩
动态的增加节点和移除节点
增: add-node:指定新节点的ip和端口,集群中的任意一个节点的ip和端口
指定该节点是slave还是master
如果是slave,在指定它的master是谁


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类