
| desc | |
| 为什么需要特征工程 |
如果特征好,那么简单 的model 就可以了
不好操作才需要采用 NN model
|
| 关于高级可视化 |
NN 层层可以可视化
sigmoid 层上可视化
|
| AUC曲线 | area under ROC curve |
| 特征迭代 |
通俗的解释:
其实就是:加了一个有用的特征
|
| 特征与业务紧紧绑定 |
业务过程分析透彻了,就能提出:组合维度,造出非常贴近业务的特征
数据清洗与筛选特征的过程 使得你 了解业务
|
| 关于样本比例 |
大多数样本对正负样本敏感
多等几天可以增大数据量
采样一般会破坏数据的分布,因为是很多个维度,不能每个维度都 分布符合
|
| 连续数据 离散化 |
学会将连续数据离散化,尤其是0-1 离散
可以大大提高训练的速度
连续的可以 离散化
hash 是散列,可以视为 将高维度的数据 离散化 为低维度的数据
|
| 类别变量 |
可以 one hot,也是 0-1离散化
即:不要出现2,可以用 三四个bit 表示多类别
|
| 启发: |
sklearn 的 有 preprocess 的package
你就不用自己手写
一般的数据处理使用 sklearning.preprocess
对于 nlp 的预处理,可以使用 nltk
而不要 自己再写,这是在 发明 重复的轮子,而且每次都是。。。。
# 一个观念:不要自己手写数据预处理了
重点学 sklearning 的preprocess
这个能体现工程能力
|
| 代表 |
感知机最能体现 模型
LR 最能体现特征 工程了
|
| 关于kaggle | 在上面能看到很多 feature engining |
| 对于电商领域的推荐,可以从哪里抓特征 |
分三个角度:
店家:开店时长,评价星级,服务,文本分析,
商品:商品质量,评论与评分,材质,价格,销量
用户:历史数据,爱好标签
|
| 数据处理技巧 |
不可信的样本丢掉
缺失值极多的字段不考虑
|
| 正负样本不平衡处理办法 |
1. 正样本 >> 负样本,且量都挺大 => downsampling
2. 正样本 >> 负样本,量不大 =>
1)采集更多的数据
2)上采样 /oversampling(比如图像识别中的镜像和旋转)
3)修改损失函数/loss function 中负样本的 惩罚系数,加大,如果错了 增大惩罚值
|
| 关于统计特征 |
1. 需要细粒度统计:
1)按品类 求平均等,而不是直接粗暴的划分
2)对于评分的细粒度:分为:是促销和不是促销
2. 统计特征,诸如:用户最近消费的半年的 最高值、最低值等等,易于:用户画像
|
| 特征的语义解释 |
day of week 反映是否接近周末
week of year 反映季节因素
hour of day 反映一天的时间段
|
| TF-IDF |
TF-IDF 两部分都是比值
TF:词频数/本文的词数
IDF:log(总文档数目/含t的文档数目+1)
|
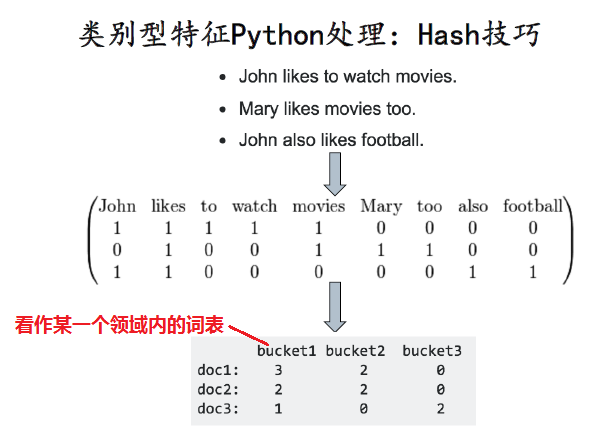
| 文本哈希的技巧 |
首先总结出几个领域内的词表
然后看 各个文本,在该领域内词表出现的个数,作为一种特征
 |
| 采用分布的方式表示特征 |
即看每个类别在 男女中占的比例
设置一个特征向量:各个位的含义:
足球 散步 看电视
3个男生,2个喜欢足球,1个喜欢散步,0个喜欢看电视
3个女生,0个喜欢足球,1个喜欢散步,2个喜欢看电视
那么按照 男女 各自在 足球 散步 看电视的分布,就是:
1/3 2/3 0
0 1/3 2/3
同样道理,对于年龄也可以使用分布的方法,即特征的各个位是:
足球 散步 看电视
2个21岁,2个足球,0个散步,0个看电视---(2, 0, 0)
1个22岁,0个足球,0个散步,1个看电视---(0, 0, 1)
1个30岁,0个足球,0个散步,1个看电视---(0, 0, 1)
1个48岁,0个足球,1个散步,0个看电视---(0, 1, 0)
1个50岁,0个足球,1个散步,0个看电视---(0, 1, 0)
 |
| 特征选择的三大方法 |
1. 直接相关度筛选,看相关度
2. 看对准确率的贡献,遍历各个子集,考虑了特征之间关联
3. 模型来选
|
| 相关度法 |
评估单个特征和结果值之间的相关程度,排序留下Top
相关度评价方法:
Pearson相关系数,互信息,距离相关度
优点:快
缺点:没有考虑到特征之间的关联作用,可能把有用的关联特征误踢掉
|
| 关于 互信息 |
语义解释:
B的值透露了多少关于A 的信息,即,可以看
I(Y; X) = H(Y) - H(Y|X)
也就是 某一个特征 X 给的Y的信息
|
| 看对准确率的贡献 |
把特征选择看做一个特征子集搜索问题
选出特征集合的若干子集,然后遍历各个子集看哪个效果好,用以评估模型的效果
典型的包裹型算法为 “递归特征删除算 法”(recursive feature elimination algorithm)
相当于删除 那些对于 模型正确率 贡献不大的 特征因素
优点:考虑了特征之间的关联因素
缺点:慢
|
| 模型来选 | 使用模型的方法,比如 L1 norm,对于 训练好后,系数为0的,就是被剔除的特征 |
| sk learning 相关的包 | sklearn.feature_selection.selectkbest |

