


2016/5/7 星期六 22:46
| desc | |
| I can do 曲线回归了 |
即使用 岭回归或者 lasso 回归
它的思路就是使用了 次方很高的的方法 而不是
同时具有:W 正则化项 的约束
曲线拟合 ,即多项式回归
|
| 特征离散化 | 把原本连续的值切段。分布在一段的连续值,认为是同一个特征值。 |
| 线性回归之所以好 |
考虑的不是高维度,二十多个因子
而对于 X^2 可以视为 feature map,即也是一种 因素
即:new 特征啊
所以 高维度的 曲线拟合,多项式回归 也可以看做是 线性回归
|
| 关于过拟合的高方差解释 |
高次方的系数越大,波动越大,所以说是 高方差
即:如果分类的曲线 很多边边角角,那么:一般是过拟合了,高方差导致的 波动大
因为只有 高次方才能引起这些波动,所以 使用 正则化以后,消除这些高次方,从而使得 曲线光滑
曲线的光滑 来源于 正则化
 |
| 为什么说LR 的结果是概率 |
之所以说 log 以后就是 概率
是因为从 softmax 讲,它是 e指数族 吉布斯回归
|
| one VS rest的缺点 | 要单独很多分类器 |
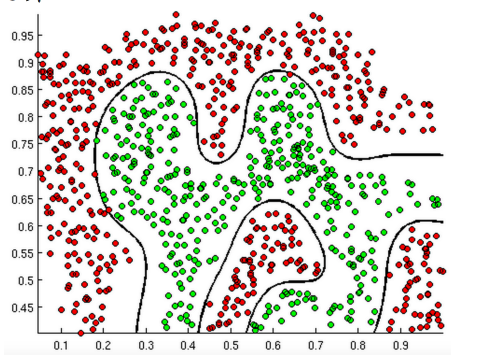
| feature map 一个角度 |
This transformation projects the input data into a space where it becomes linearly separable.
用空间的角度 解说
如果想用圆进行切分边界,那么 你的 核函数部分,即:曲线拟合部分 就要是一个圆的方程
# 寒小阳对于这个图的解释,里面是一个 圆的方程,如果点 落在圆内,那么 h(x)值比较小, 经过非线性以后就归到零类,如果大的话,那么就归到1类
启发:即如果 大致边界是这样的:
那么你也要用 一个这个曲线的 方程 带入到 sigmoid 函数当中才能进行 0-1区分啊
 |
| CTR |
input:就是一堆特征(比如商家出的钱作为feature),监督tag:就是这个广告点了还是没点
模型的输出就是点击概率
CTR 当中 不提 相似度,而是 这些广告的feature,然后看在各个情况下,点没点
就知道 各个因素的 权重了
输出结果按照 概率值 排序
CTR 是隐形的搜素引擎,即 没有用户的query
但是 仍然能get 到 usr 的info,这个作为 input
然后 找相关的 广告,排序取前面的 作为 res
CTR 和 推荐系统类似:
如果推荐系统,肯定是用户最容易点的,说明最相关
基于内容的 推荐系统 也是一个 基于相似度的
|
| 回归 | 神经网络 也可以 回归,回归神经网络 |
| why scaling |
scaling 是幅度变化,而不是归一化
比如 预测房价,如果一个 是 bedroom 个数,一个是 面积
那么 你的 因子图会是这样子,即 圆形会很扁,这样不利于优化,甚至是精度不准
|
| 工业化应用 |
工业化的数据 都在集群上,以HDFS 跑,而不是本地存储
所以此时 spark 的mllib 就有用了
|
| 这下看懂了 两个图 |
为什么 NG 要讲这个图
这个等值线是 cost,当然越小越好,所以一旦 meet 了 约束,就可以停止膨胀了
|
|
使用LR 的tech
数据量大
|
1. 采样再 LR
2. 分布式上 spark mllib
3. 将特征 离散化为 0-1,这样虽然训练数据量没有变,特征向量还变长了,
但是 因为 0-1 操作,使得计算速度变快
4. 连续值的特征,最好 scaling一样,使得因子图 不是 特别的细长,而是 圆形,这样利于优化的速度,这个也是可以 加速训练的
|
|
使用LR 的tech
样本倾斜
|
1. 修改 loss function,给 样本量少的一方,加大 分类错误后的损失值
# 理解这个需要 理解 LR 损失函数中的每一项,都是表示这个类下分错了的 贡献
2. 上采样,图像:比如 图像镜像旋转,倒置 等等 也可以作为同类样本
|
|
使用LR 的tech
关于特征的聚类
|
提前,将一些特征先 hash,比如 uuid?????????????
|
|
LR的好,处
|
1. 概率形式输出,不仅仅是 0-1 tag 类别,能直接概率性的回答问题
2. 概率输出 可以直接 point-wise 的O(n) 复杂度的排序
3. 每个因子的系数权重可以get到,能说出每个因子的哪个重要,利于汇报
4. 快,尤其是使用 0-1 的特征向量
# 能不能直接换成 bool 类型的特征向量呢?
note:
其实一直想要一个model,这个model 可以反映 各个因素的权重,哪个是主要权重
你以为有 SVM 也是有 weight 具体是什么的 输出。
即本质还是个线性回归,就是这个 参数不好调,需要SGD
但是对于分类的话,线性拟合不好操作,所以才有了 sigmoid 这个操作使得 回归适合于分类。
一个观点:
如果 模型简单而有效,那么这个是好的模型,因为出了问题能直接操作,人为操作,
这个是工业界喜欢的,但是 NN 就不能这么做
|
| LR 的进一步理解 |
· 不要用 做差 ||y-tag||2的损失函数,因为拆开后事很多的 凸函数,所以组合起来不够平滑
是这样的:
· feature map 做非线性操作 可以做 曲线分类,线性不可分的 分类
|

