


A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends
A Survey on Self-supervised Learning:
Algorithms, Applications, and Future Trends
Jie Gui, Senior Member, IEEE, Tuo Chen, Jing
自监督学习,在google scholar上检索,在2021年一年就产生了18,900 相关文章,也就是每天大概52篇相关工作发表出来。文章数量也是逐年上升,尤其是你可以去各大任务的SOTA工作看一下,基本上都是基于SSL进行预训练了。2019年是kaiming he等大神的MOCO出现的哪一年,在这之后陆陆续续出来了moco v2-v3, dinov1-v2等。后面到了2020年就基本上是大量输出了,其中20年已经有针对constractive learning推出了survey的文章[1],同时还有大神Lecun对SSL是大力推广,更是给SSL的研究工作助力了很多。
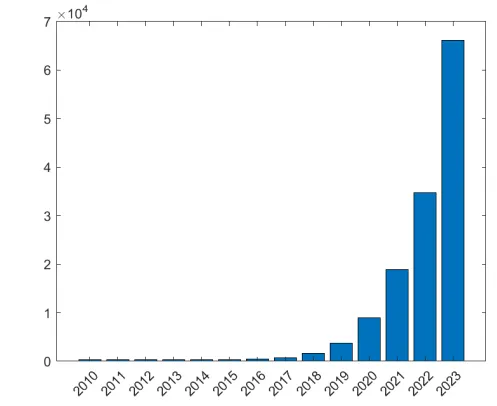
这些预训练工作基本上都是基于特别大的数据量,比如imagenet22k开展,然后再迁移到自己的任务上。所以SSL工作感觉已经成为普遍做法,就像在早期的深度学习领域,基于1000类的imagenet数据进行训练分类任务,然后再这个模型基础上对别的任务进行训练,这样模型比较容易收敛并提高效果,当时几年时间内基本上大家都这么来做。但是后面若干年后,随着别的任务数据量增加以及imagenet1k数据集的量显得稍微捉襟见肘了,这样做的好处逐渐消失了,大家不再先训练分类任务,而是直接在相应任务的数据集上进行模型优化。现在SSL的出现,克服了大数据集没有标签的问题,同时又能提升下游任务的效果,受欢迎是一定的,何况这种自监督学习实现起来又很简单,简直就是万能钥匙。
SSL的基本思路可以用下图来概括。
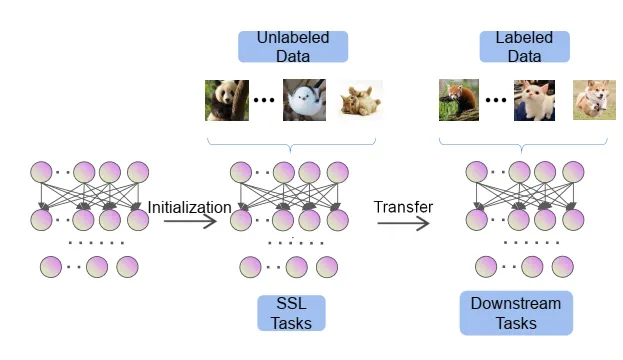
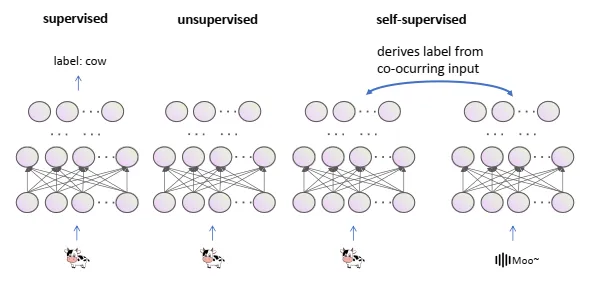
SSL最早在1994年文献3中定义,SSL的定义如下图,在这个图中,可以看到这里的SSL和无监督是有差别的,严格意义上其实是的,和无监督是不一样的,在SSL虽然没有直接的标签,但是可以有间接的标签将任务进行定义或者说是pretext task。在2020年ICLR2020 keynots,Yann Lecun将SSL定义为,对丢失信息的完善重建过程。主要包括四个方面,1. 从任意其它part预测任意part。2. 从历史预测未来。3. 从可见预测不可见。4. 从所有可用部分预测任意遮挡、马克、或者被污染部分。总之,在SSL中,输入的一部分是未知的,而目标函数就是预测这个特殊的部分。
pretext task也被称为代理任务,代理任务意味着这个任务不是主要目标,但是是生成一个鲁棒的预训练模型的方法。代理任务有两个典型的特点,1,用深度学习方法去学习特征,2,从数据本身产生监督信号,也就是自监督过程。代理任务一般有四种形式,基于上下文(Context-based methods),对比学习(Contrastive learning, CL),(Temporal Based)生成算法(generative algorithms)和对比生成方法(constrastive generative methods),其中对比学习是相对简单的,moco,dino等工作也正是基于这种方式的。生成算法一般是指masked image modeling(MIM)。
1、基于上下文(context-based methods)
这种方法主要是基于数据本身的上下文信息context,比如空间结构、局部和全局连续性等,进行学习。首先在NLP领域得到大量应用,在NLP领域的成功推动了CV领域的应用,在NLP领域比较常见的就是使用MASK掩码方式来训练,比如注明的BERT模型[4],通常是把句子中一些词随机mask掉,然后让模型预测这些词,也就是输入是部分被mask掉的句子,让模型把句子还原出来,根据还原的情况进行loss计算从而完成模型优化。而CV领域比较常见的就是“抠图“,通过把图片分成若干个块,然后让模型来预测每一块的位置。本来数据中是没有这个位置的标签的,通过自监督学习我们自己构造了这个标签,来帮助模型学习其中的语义信息[5]。还有借助数据增广的方式来进行自监督,把一幅图片进行各个角度的旋转,然后让模型来预测图片旋转的角度,相当于把自监督和数据增强进行了结合,让模型具有更强的泛化能力[6]。
- 对比学习
很多SSL方法都是基于CL提出的,单纯基于简单的实例区分任务进行CL学习。典型的方法比如MoCo v1, MoCo v2, SimCLR v1, SimCLR v2. 负样本对比学习是指来自同一实例样本的数据都是正样本,不同实例的数据是负样本,比如moco系列的方法是基于这个思路。另外,还有一种思路是自蒸馏的对比学习,典型的代表方法有BYOL(Bootstrap your own latent). 这种方法不需要负样本,通常使用的对比网络有两个分支,但是这两个分支不共享参数,其中一个在线网络,另外一个是目标网络。SimCLR, BYOL, SwAV这些都是这类方法。这些模型的目的是最大化来自同一张图的数据增广样本的相似度。SimSiam通过大样本以及动量解码器实现无负样本学习
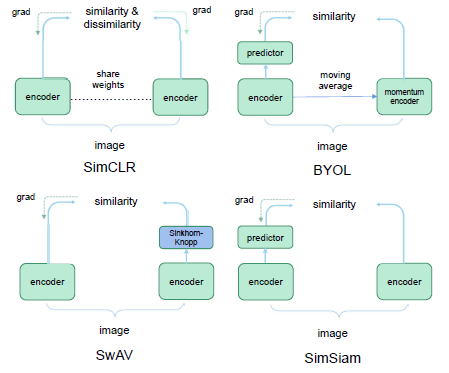
对比学习还有一种是基于特征相关的对比学习,比如Barlow Twins,衡量同一样本两个不同views输入相同网络得到embeddings的互相关矩阵,并使其尽可能接近于单位阵来避免坍缩。这种方法使得样本的两个view之间的embeddings尽可能相似,同时最小化向量分量之间的冗余。本文的方法叫做Barlow Twins,它不需要大的batches,也不需要不对称网络(predictor network,stop-gradient,moving average)。但它依赖于非常高维的输出向量。在低数据条件下的半监督分类任务上,Barlow Twins在ImageNet上优于先前的方法,并在下游任务与sota表现相当。
- 生成式算法,这类算法主要是MIM方法,典型的包括BEiT, masked AE, context AE, SimMIM等,通过对 “表征学习” 和 “解决 pretext task” 这两个功能做完全分离,使得 encoder 学习到更好的表征,从而在下游任务实现了更好的泛化性能。
- 对比生成方法,典型的如DINO这种方法,需要借助一个在线的蒸馏教师网络进行学习。
1. A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, pp. 1–22, 2020
2.A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends. Jie Gui, Tuo Chen, Jing
- V. R. de Sa, “Learning classification with unlabeled data,” in Neural Inf. Process. Syst., pp. 112–119, 1994
- Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” NAACL-HLT (2019).
- Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised Visual Representation Learning by Context Prediction. In ICCV 2015
- Gidaris, Spyros et al. “Unsupervised Representation Learning by Predicting Image Rotations.” In ICLR 2018


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2018-09-23 儿子的经典名言