

self supervised learning
self supervised learning 自监督学习,按照机器学习中传统分类方法,监督学习,无监督学习,强化学习,有些还会有半监督学习等。
监督学习,以计算机视觉领域中最简单的任务为例,给你一张只有一只狗的图,让你说这图是什么,你肯定说是狗。那么在计算机视觉任务重,给这图打的标签一般就是dog, 然后输入这张图,标签就是dog,模型输出如果不是dog, 就认为模型学错了,这个时候如果用一个loss损失函数来评估模型的表现的话,loss应该体现出来这个时候loss的值要很大,而如果模型输出的结果是这个图是dog,那么loss应该是0.此时模型优化过程就会根据loss进行调整模型参数的过程,这个过程称为是监督学习的过程。就是输入数据是有标签并直接和任务相关联的,用这个标签来对模型进行优化,在这个过程中,我们有理由相信此时模型只能做这个任务,如果换了个任务模型是不能用的。在深度学习领域,尤其是CNN卷积模型领域,通常需要大量带标签的数据才能使得模型具有良好的性能。那么在数据缺乏的情况下,之前常用的做法是基于公开的大数据集进行有监督学习,比如imagenet的分类数据,大概1M数据集,分为1000类别。那么如果我想做视觉中的别的任务,比如检测任务,但是我又缺乏足够的数据,那么之前通常的做法就是用这1M的分类数据训练一个分类网络,而后用这个分类网络作为backbone,在训练检测任务时,微调或者frozen住这个backbone,只用检测数据训练和检测相关的任务。在这个过程中,我们通常任务这个backbone的作用是特征提取,无数工作也表明当你数据很少时,这么做确实可以很好地提升性能。但是这个过程其实是针对分类任务进行训练的,是否真的最适合检测呢?
无监督学习,无监督学习就是在模型优化过程中,数据是没有标签的,那么此时我们就要去用一些measure去衡量样本之间的相似性,通常用的聚类等机器学习算法就是这类的方法,数据是没标签的,我们用一些measure,比如欧式距离,l1, l2等来衡量样本之间的相似性,样本由样本具有的一些特征来表征,比如x,y,或者w,h这种特性。这种方法通常情况下,受到measure的影响比较大,而且在这个过程中,有时候无法保证一定是收敛或者收敛到某一个点的。
半监督学习或者弱监督学习,所谓半监督学习,就是数据有标签,但是标签信息不完整,比如告诉你一张图里有人,但是不告诉你有几个人,人在哪里,但是你可以依赖这个弱标签找出来人在哪里,有几个人,这个过程的学习就是半监督学习。
强化学习,强化学习通常是用于机器人控制领域,就是没有办法给出具体的监督信息,但是可以给一个反馈,告诉你你走对了还是错了,或者算是一个惩罚、奖励反馈。在这个信息下,去达到最终的目的。
最近这些年非常热的一个方向,self-supervised learning,自监督学习,其实就是无监督学习,Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。自监督学习有两个方向,一个是端到端的,一个是对比学习,这次主要是介绍一下对比学习。已MOCO为例,对比学习其实思路真的很简洁好用。
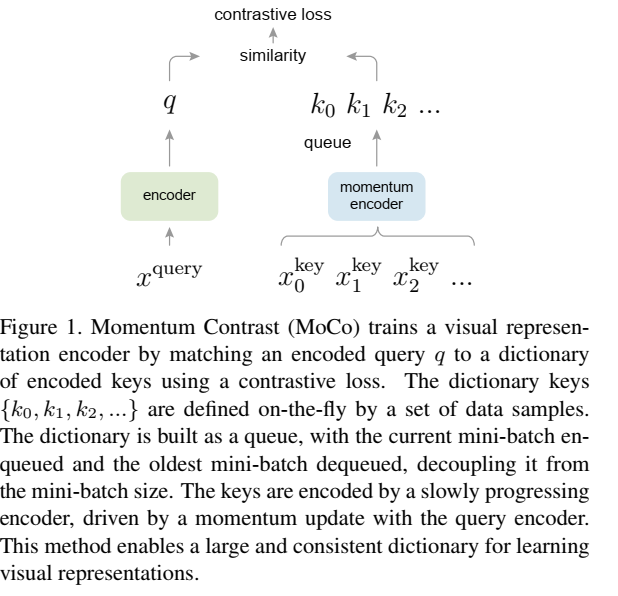

从图上可以看到,简单吧。
DINO - Emerging Properties in Self-Supervised Vision Transformers
DINOv2: Learning Robust Visual Features without Supervision
Meta AI Research, FAIR
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Patrick Labatut, Armand Joulin, Piotr Bojanowski
https://github.com/facebookresearch/dinov2
这是后来出现的DINO系列的工作,也是META的工作,这个和CNN一样,也是对比学习实现自监督学习,但是不太一样的这是基于VIT来做的,训练上会收敛难点。目前来看,后期基于自监督的很多工作都是基于这个框架来的。前面一篇介绍深度估计的工作,就是基于dino来做的。
推荐一个非常好的讲解视频,https://www.bilibili.com/video/BV19S4y1M7hm/?spm_id_from=333.788
PS.自监督里的DINO和后来检测里出现的DINO不是一回事哈,大家搜工作的时候可能会被推荐不同的工作。自监督的DINO是先出来的工作,是META做的,检测领域的DINO是商汤相关老师做的,所以有些同学在知乎上回复人家帖子骂人家误导自己,其实大可不必,你加个关键词 self supervised就会出来自监督的DINO文章了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律